在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。
然而,大多数现有方法仍以文本为中心,视觉部分常被动地作为辅助信号输入。相比之下,我们认为在后训练阶段重新审视视觉自监督学习的潜力,设计以视觉为中心的后训练对于增强多模态大模型对于视觉信息本身的细粒度深入理解也同样至关重要。
为此,来自MMLab@南洋理工大学的最新论文《Visual Jigsaw Post-Training Improves MLLMs》提出了一种全新的针对多模态大模型后训练任务-Visual Jigsaw。
它将经典的自监督拼图任务重新设计为多模态大模型后训练阶段的核心目标,让模型在不依赖额外标注、也无需视觉生成模块的情况下,显式强化自身的视觉感知与理解能力。在图片,视频,和3D三种视觉模态下都验证了其有效性。

Visual Jigsaw 方法简介
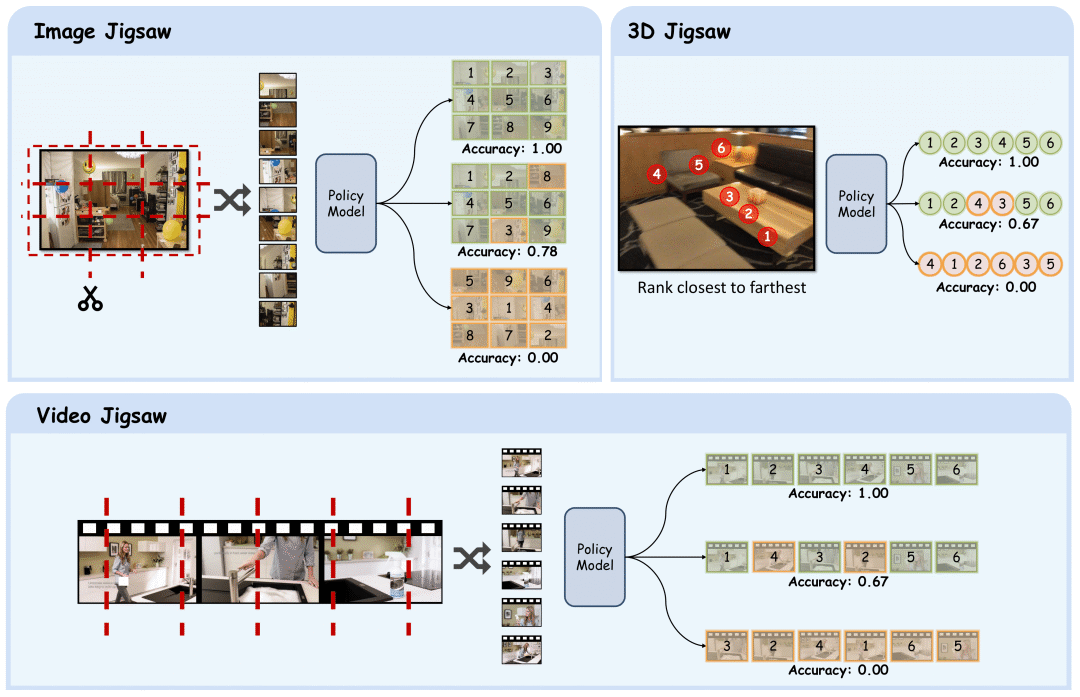
Visual Jigsaw可以看作是一类通用的对于视觉信息的排序重建任务。给定某种视觉模态的数据(图片,视频,3D),对其进行特定的划分并随机打乱顺序,获得一组子元素作为拼图块。模型的目标是重构视觉信息,预测出它们的正确顺序,并以文字的形式输出对应的排列顺序。整个训练过程采用强化学习算法GRPO来优化。
Visual Jigsaw有对应的GT可以直接验证,团队设计了一个分级奖励机制:预测完全正确时奖励为1;若部分位置正确,则按照正确比例给奖励,并乘上折扣系数来防止模型过度依赖部分匹配;若输出不是有效的排列,则奖励为0。
对于不同视觉模态,具体的Visual Jigsaw任务设计如下
Image Jigsaw:图片在2D空间上被划分为 个相同大小的子图,打乱后模型需恢复正确的空间顺序。
Video Jigsaw:视频在时间维度上被分割成等长的视频片段,模型需重建原始的时间顺序。
3D Jigsaw:从RGB-D图像中采样多个深度点,在图片中标注对应点的位置和打乱后的序号,要求模型恢复由近到远的深度次序。
实验结果
通过在多种图像、视频和3D模态上分别验证了 Visual Jigsaw的有效性:
Image Jigsaw
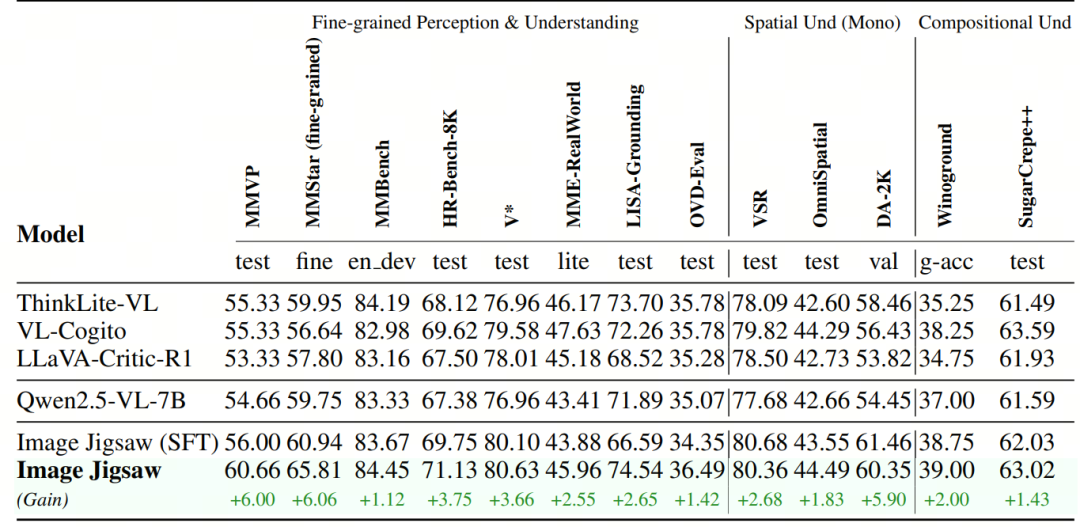
经过image jigsaw 的训练,模型在三类vision-centric的基准上都带来了稳定提升:
1)细粒度感知与理解,2)基于单目图像的空间感知和理解,3) 组合式视觉理解与推理。
结果表明,在多模态大模型中引入image jigsaw的后训练,能显著增强其感知能力和细粒度视觉理解能力,而这恰恰是现有以推理为主的后训练策略所欠缺的。
这种提升来源于拼图任务本身的要求——模型必须关注局部 patch 的细节、推理整体空间布局,并理解不同 patch 之间的关系,这些都直接促进了细粒度、空间和组合式的理解。
Video Jigsaw
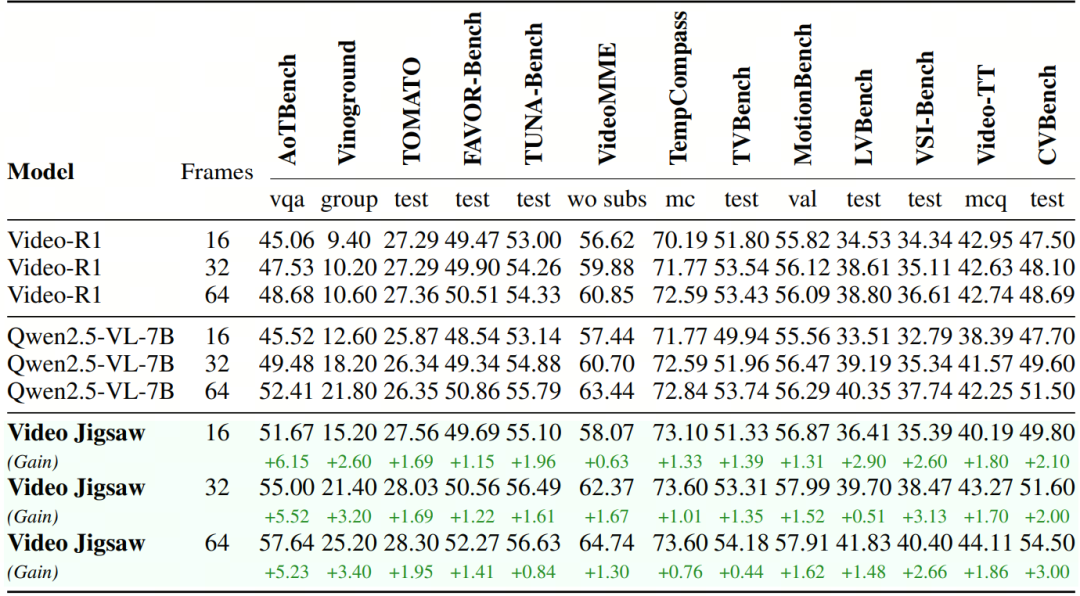
经过video jigsaw 的训练,模型在各类通用视频理解基准上均表现出稳定的提升。该方法整体上增强了模型对视频的感知与理解,并且在需要时间维度推理和时间方向性理解的任务(如 AoTBench)上提升尤为显著。
同时,在CVBench上的大幅度提升也验证了模型在跨视频理解与推理上的增强。这表明,视频拼图任务能够促使模型更好地捕捉时间连续性、理解视频间的关联、推理方向一致性,并最终提升对视频的整体和通用理解能力。
3D Jigsaw
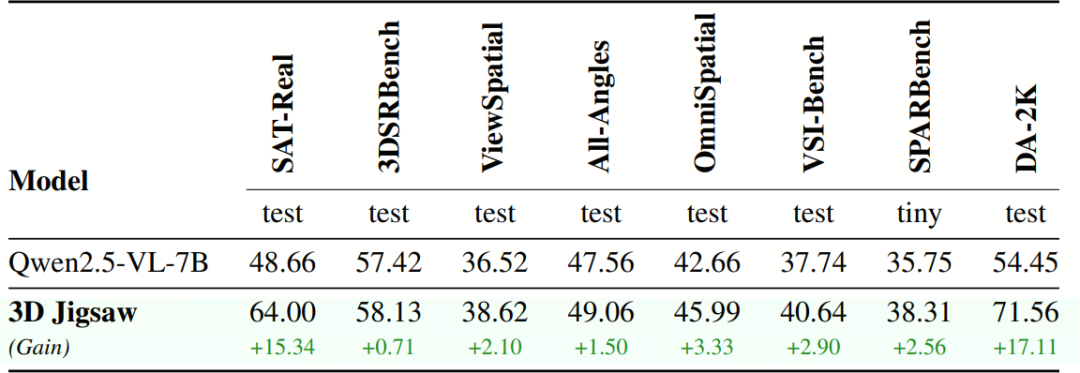
经过3D Jigsaw的训练,模型在各类3D基准任务上都取得了显著提升。最突出的提升出现在与深度估计直接相关的 DA-2K 上,这是深度排序预训练任务的直接体现。但更重要的是,在广泛的其他任务上也观察到了一致的提升,包括单视角基准(如 3DSRBench、OmniSpatial)、多视角基准(如 ViewSpatial、All-Angles),以及第一人称视频基准(如 VSI-Bench)。这些结果表明,该方法不仅让模型掌握了深度排序这一特定技能,同时也有效增强了其整体的三维空间感知与推理能力。
结语
Visual Jigsaw提供了一种以视觉为中心的轻量、可验证、无需标注的新型自监督后训练范式,为 MLLMs 的视觉感知注入了全新活力。团队希望这一工作不仅展示了视觉拼图任务的潜力,更能启发学界设计更多聚焦视觉信息本身的自/弱监督任务,让多模态大模型能够更好地感知和理解各类视觉信息。
论文链接:https://arxiv.org/abs/2509.25190
项目主页:https://penghao-wu.github.io/visual_jigsaw/
数据和模型HF链接:https://huggingface.co/collections/craigwu/visual-jigsaw-68d92d6aca580f3dc7e3cf36
代码仓库链接:https://github.com/penghao-wu/visual_jigsaw


