
译者 | 核子可乐
审校 | 重楼
如今AI虽已全面普及,但多数职场人士仍难以统一运用各类互不相关的工具:一会需要使用聊天机器人、一会需要将文本复制到摘要器内,再加上会议转录和翻译,将本应顺畅的工作流程拆分得零散琐碎。
所以问题来了:为什么不能把各项AI功能集中起来?
为此我决定构建单一Web门户,供用户随时上传文档、提问、获取摘要、转录会议内容、翻译文件,甚至从PDF中提取表格等。其功能不求花哨、只讲实用,旨在解决我们每天面临的实际问题。
下面我们将共同了解如何将整个项目拼凑起来,介绍技术选型理由,以及如何将其运行起来。不必担心,所有内容均为开源,且不涉及任何AI“黑话”。
这个门户能干啥?
- 与数据对话:上传文档,用自然语言提问,直接获取答案(不只靠关键词匹配)。
- 摘要:上传长报告或政策文件,快速获取简短清晰的摘要——若有需要,还可以自定义摘要方式。
- 转录:上传会议录音,快速获得书面转录。
- 翻译:将文档转换为其他语言,保留原始格式。
- 提取:从PDF中抓取表格和关键数据,并下载为JSON或Excel格式。
不必在各类应用间往来切换,只需上传文件、选择功能,即可获得所需内容。
各项功能如何协同起效?
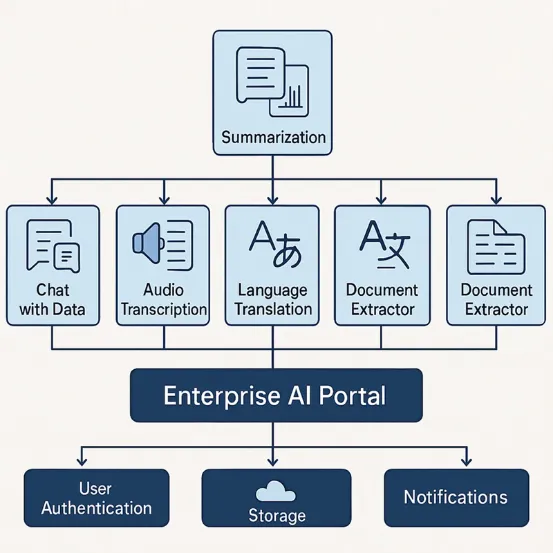
下面简单来看项目的整体架构:
- 前端:React
- 后端:FastAPI(Python)
- 大模型和嵌入:Azure OpenAI
- 向量数据库:Pinecone
- 音频转录:Whisper(本地运行)
- 翻译:Azure Translator
- 文档提取:Azure Document Intelligence
- 存储:本地或Azure Blob存储(演示中使用本地存储)
- 认证:(生产环境可添加 Azure AD/OAuth)
各组件间的连接方式:
功能演示(附带图表及代码)
与数据对话
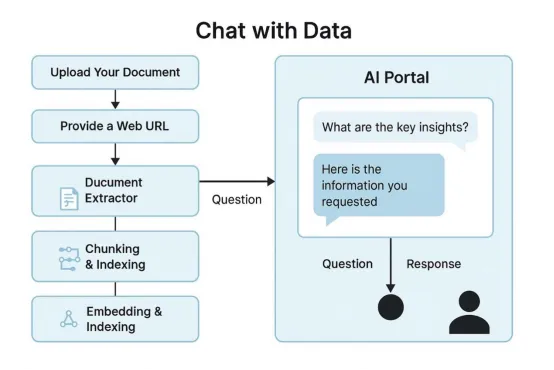
无需阅读全文,即可通过提问直接从PDF文件或者报告中获取答案,是不是很让人心动?这就是“与数据对话”功能。大家上传文档、用自然语言提出问题,大模型就能直接从文件内容中提取答案。这将为所有人节约时间——包括法律、财务、合规部门,乃至任何需要处理冗长文件的工作者。
如何实现
此门户会拆分并嵌入文档,将其存储在Pinecone当中,并使用Azure OpenAI回答用户输入的任何问题。
后端:用于上传文档的FastAPI端点
复制# Python backend example
@app.post("/upload/")
async def upload_file(file: UploadFile = File(...)):
contents = await file.read()
text = contents.decode("utf-8", errors="ignore")
upsert_document(text)
return {"status": "uploaded"}后端:用于聊天的FastAPI端点
复制# Python backend for chat
@app.post("/chat/")
async def chat(query: str = Form(...)):
matches = query_pinecone(query)
context = " ".join([m['text'] for m in matches])
answer = get_answer(query, context)
return {"answer": answer}其余后端代码请参见GitHub。
摘要
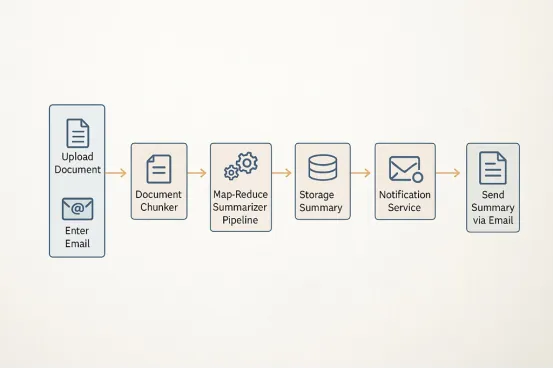
坦白讲,大多数商业文档都搞得太冗长。摘要功能将帮助我们从这些大文件中获取简短、清晰的摘要。我们甚至可以添加自定义提示词,例如“总结合规性关键风险”或“提供主要行动指标”。
如何实现
在上传文档之后,后端将内容及用户的提示词发送至Azure OpenAI,而后返回摘要内容——再无需通读全文。
后端:FastAPI摘要端点
复制# Summarization endpoint
@app.post("/summarize/")
async def summarize(file: UploadFile = File(...), prompt: str = Form("Summarize this document:")):
contents = await file.read()
text = contents.decode("utf-8", errors="ignore")
summary = summarize_text(text, prompt)
return JSONResponse(content={"summary": summary})详见React SummarizeForm组件。
音频转录
大家肯定都处理过会议或者电话录音……再听一遍真的让人崩溃。现在有了这项功能,只需上传音频或者视频文件,即可快速获取书面记录。
如何实现
音频上传完成后,后端会使用Whisper转录所有内容,而后将全文显示在浏览器内。
后端:FastAPI音频转录端点
复制# Audio transcription endpoint
@app.post("/transcribe/")
async def transcribe(file: UploadFile = File(...)):
audio_bytes = await file.read()
transcript = transcribe_audio_file(audio_bytes, file.filename)
return JSONResponse(content={"transcript": transcript})TranscribeForm.js
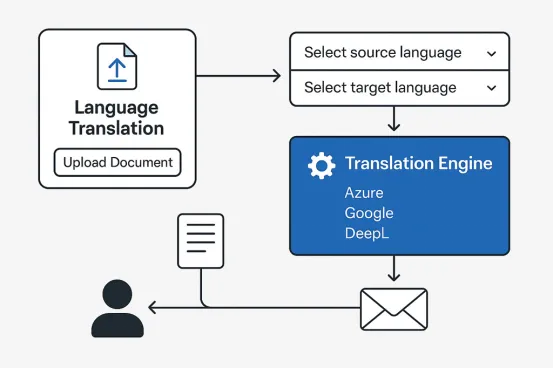
语言翻译
全球团队往往需要跨语种协作,而文档翻译则速度极慢且耗费大量人力。现在大家可以上传任意文件、选定目标语言并快速获取翻译版本——连格式都几乎保持一致。
如何实现
上传文档、选定语言,后端会调用Azure Translator进行翻译,并将结果展示给用户。
后端:FastAPI翻译端点
复制# Translation endpoint
@app.post("/translate/")
async def translate(
file: UploadFile = File(...),
to_language: str = Form(...)
):
contents = await file.read()
text = contents.decode("utf-8", errors="ignore")
translated = fake_translate(text, to_language)
return JSONResponse(content={"translated": translated})TranslateForm.js
文档提取器
从PDF和表单中提取表格和键值数据一直是最让文员们抓狂的任务。不怕,现在可以交给AI搞定。
如何实现
上传PDF(或其他扫描文档),选择JSON或Excel格式,此门户将使用Azure Document Intelligence提取表格及键值对。结果可供随时下载。
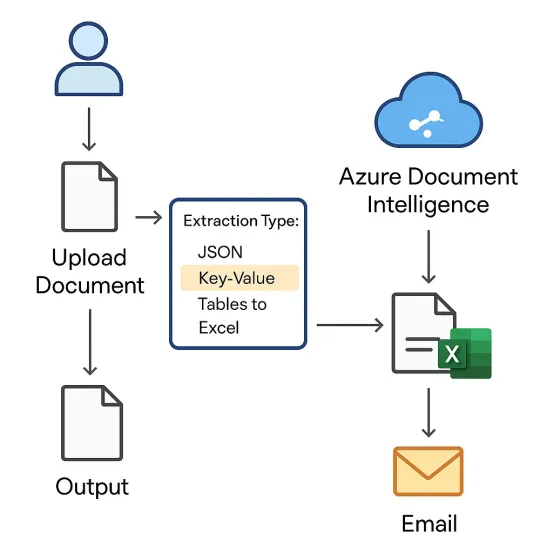
后端:FastAPI提取端点
复制# Document extractor endpoint
@app.post("/extract/")
async def extract(
file: UploadFile = File(...),
output_format: str = Form("json")
):
contents = await file.read()
filename = file.filename
if output_format == "excel":
xls_path = extract_tables_and_kv(contents, filename, output_format="excel")
return FileResponse(xls_path, media_type="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet", filename="extracted_tables.xlsx")
else:
output = extract_tables_and_kv(contents, filename, output_format="json")
return JSONResponse(content=output)ExtractForm.js
如何运行这套门户
开源代码地址: github.com/sanjaybk7/AIPortal
- 克隆repo: git clone https://github.com/sanjaybk7/AIPortal.git
- 后端:进入 backend,设置Python、安装依赖项并运行FastAPI。
- 前端:进入 frontend,安装依赖项并运行React。
- 打开浏览器:访问 http://localhost:3000 并开始上传。
注意,这里需要使用Azure和Pinecone的API密钥,相关设置方法已在repo说明中提供。
总结
相信很多朋友跟我一样,已经厌倦了在不同AI工具间往来切换。通过这篇简短的攻略,咱们成功把多款现代AI工具集中起来,感兴趣的朋友不妨赶紧用起来!
原文标题:How I Built an AI Portal for Document Q and A, Summarization, Transcription, Translation, and Extraction,作者:Sanjay Krishnegowda


