在大模型(LLM)推理服务中,如何在输入/输出长度剧烈波动的现实场景下,依然保持高吞吐与低延迟?传统静态资源分配策略往往导致计算资源严重浪费。近期,来自中国科学技术大学、北航与京东的研究团队提出了一项名为 Arrow 的自适应调度机制,通过无状态实例与弹性实例池,实现了高达 7.78 倍 的请求服务速率提升。这项研究不仅解决了Prefill-Decode 拆分架构(PD 拆分)的核心瓶颈,更为大模型服务系统的弹性化设计提供了新范式。
 论文链接见文末
论文链接见文末
核心看点
Arrow 的核心突破在于其“双自适应”调度能力——既能动态调整请求的分发路径,也能实时重配计算实例的角色。研究团队发现,现实中的 LLM 请求在输入和输出长度上存在巨大波动,导致传统固定比例的 Prefill(填充)与 Decode(解码)节点配置极易失衡。为此,Arrow 创新性地将计算实例设计为无状态(stateless),使其可随时在 Prefill 和 Decode 任务间切换,彻底消除了传统“实例翻转”带来的分钟级延迟。通过实时监控Time-to-First-Token(TTFT,首字延迟)和Time-per-Output-Token(TPOT,字间延迟)等关键指标,Arrow 实现了 SLO(服务等级目标)感知的调度决策,在多种真实工作负载下,请求吞吐率最高提升了 5.62 倍(对比 PD 共置系统)和 7.78 倍(对比 PD 拆分系统)。
研究背景
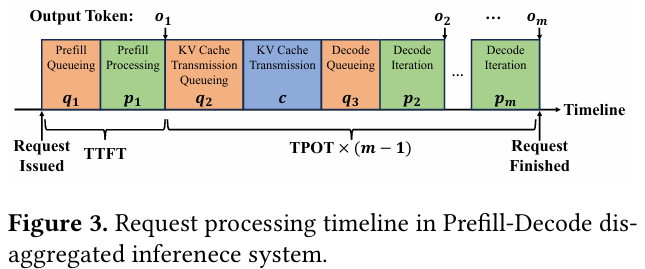
当前,大模型推理服务普遍采用Transformer架构,其推理过程分为两个阶段:Prefill 阶段负责处理用户输入并生成首个输出 Token,计算复杂度与输入长度的平方成正比;Decode 阶段则以自回归方式逐个生成后续 Token,计算复杂度与批处理中的总 Token 数线性相关。为避免两阶段的相互干扰,学术界提出了Prefill-Decode 拆分架构,将两种计算任务分配给专用的实例。然而,这种架构引入了一个新问题:如何确定 Prefill 与 Decode 实例的最优配比?
传统方法依赖离线分析或仿真,但在输入/输出长度剧烈波动的真实场景中,静态配比无法适应动态负载,导致资源利用率低下。DistServe、Splitwise 等系统虽能动态“翻转”实例角色,但翻转过程需重启实例,耗时长达数分钟,无法应对突发流量。因此,如何实现低延迟、高灵活性的实例资源动态调度,成为提升 LLM 服务系统整体吞吐(goodput)的关键挑战。
 图片
图片
核心贡献
 图片
图片
方法创新:无状态实例与弹性实例池
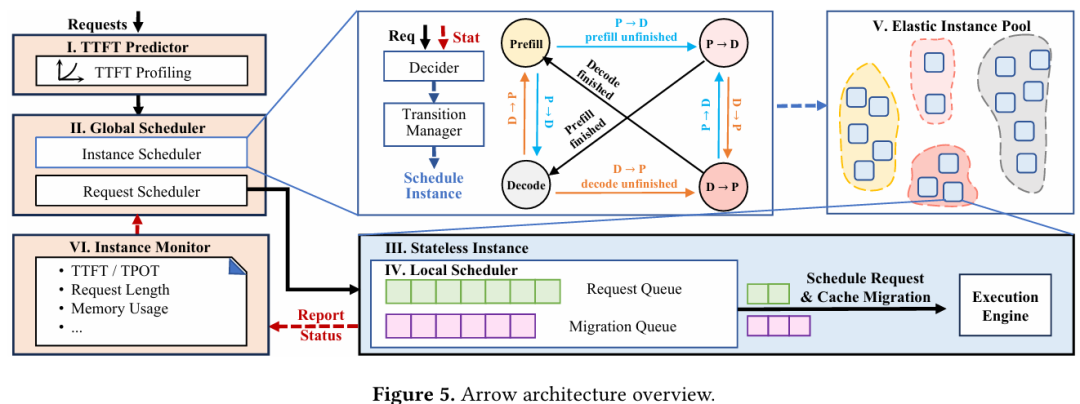
Arrow 的首要创新是提出了无状态实例(stateless instance)设计。在传统系统中,一个实例被固化为 Prefill 或 Decode 角色。而在 Arrow 中,每个实例均可处理任意类型的任务。当一个请求的 Prefill 阶段完成后,该请求及其KV Cache(键值缓存,存储中间计算结果以避免重复计算)可被传输至任意其他实例进行 Decode。这使得实例的角色切换不再是“物理重启”,而是“逻辑重分配”,实现了零等待时间的资源重配。
为了高效管理这些无状态实例,Arrow 设计了弹性实例池(elastic instance pool),包含四个逻辑池:Prefill 池、Decode 池、P→D 池(正从 Prefill 转向 Decode)和 D→P 池(正从 Decode 转向 Prefill)。全局调度器通过移动实例在这些池间的归属,即可完成角色切换,整个过程无任何中断。
理论突破:基于 SLO 的实时调度洞察
 图片
图片
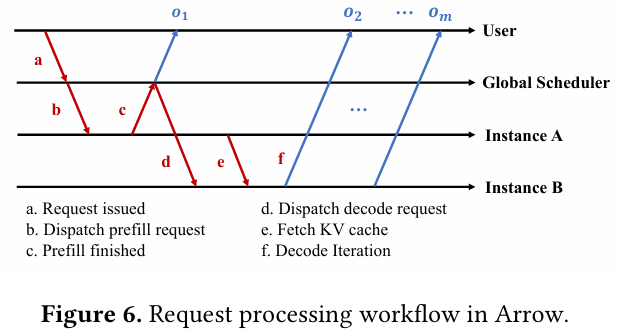
Arrow 的调度决策并非基于间接的请求长度或利用率,而是直接与 SLO 挂钩。研究团队通过分析,得出了几项关键洞察:
- TTFT 具有强可预测性:由于 Prefill 时间与输入长度的平方成正比,系统可以精确预测新请求的 TTFT。Arrow 利用此特性,在请求进入队列前就判断其是否可能违反 SLO,从而提前触发实例重配。
- TPOT 具有弱可预测性但非单调:Decode 阶段的延迟受多种因素影响,难以预测。但 TPOT 是所有字间延迟的平均值,具有“非单调性”,即短暂的延迟高峰不一定会导致 SLO 违规。因此,Arrow 采取“事后监测”策略,当观察到 TPOT 持续超标时,再调度更多实例加入 Decode。
实证成果:性能显著超越现有系统
 图片
图片
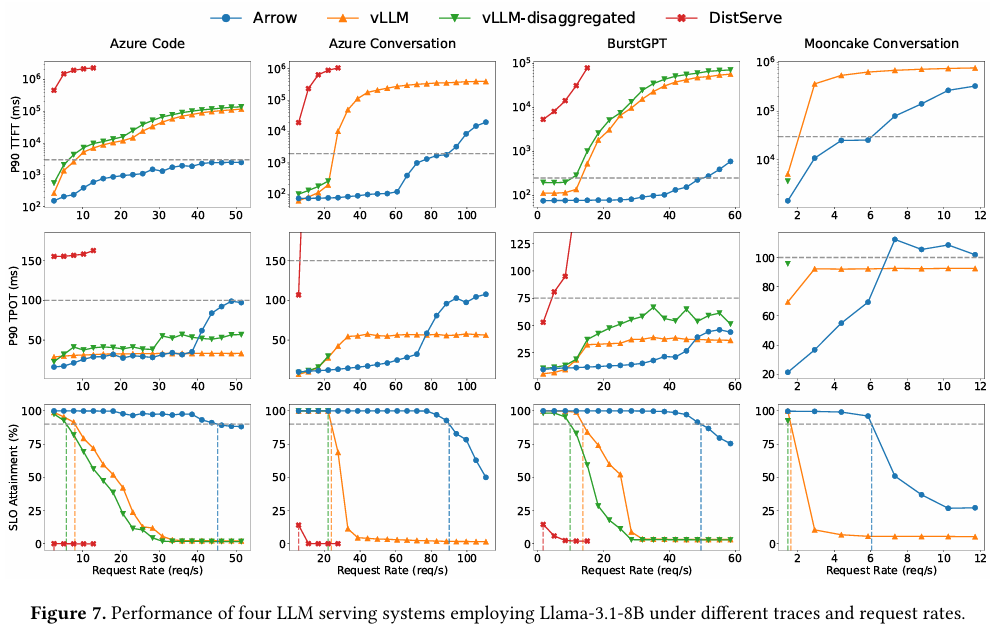
研究团队基于 vLLM 框架实现了 Arrow,并在 Llama-3.1-8B 模型上,使用 Azure Code、BurstGPT 等四种真实生产流量进行测试。在 90% SLO 达标率的约束下,Arrow 的性能表现如下:
 图片
图片
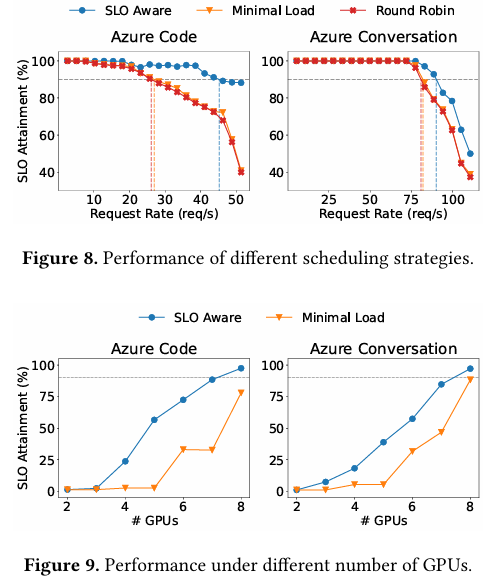
- 在高度突发的 Azure Code 负载下,Arrow 的可持续请求速率达到50 req/s,是 vLLM(PD 共置)的5.62 倍,是 vLLM-disaggregated(PD 拆分)的7.78 倍。
- 在长上下文场景(Mooncake Conversation)下,Arrow 通过将空闲的 Prefill 实例快速调度至 Decode 任务,释放了宝贵的内存资源,请求速率提升了3.73 倍(对比 vLLM)。
- 消融实验表明,Arrow 的“SLO 感知”调度策略比仅采用“最小负载”策略的基线高出1.67 倍的请求速率,证明了其自适应机制的有效性。
- 在扩展性测试中,随着 GPU 数量从 2 个增加到 8 个,Arrow 的 SLO 达标率实现了近似线性增长,展现了强大的横向扩展能力。
行业意义
Arrow 的研究成果为大模型即服务(LMaaS)领域指明了一条高效、弹性的技术路线。它解决了 PD 拆分架构从“理论优势”到“实践落地”的最后一公里问题,即动态资源调度的延迟与灵活性。其设计理念与云原生和微服务的弹性思想高度契合,有望成为未来大模型推理平台的标准组件。
该工作与我国推动算力基础设施高效利用的政策导向相符,通过提升单 GPU 的请求处理能力,可显著降低大模型服务的运营成本和能耗,助力实现“双碳”目标。未来,Arrow 的架构有望推动自动驾驶、智能客服等对延迟敏感的产业级应用,实现更快速、更稳定的 AI 交互体验。这一创新,正在悄然推动大模型服务基础设施的深层变革。
论文链接:Arrow: Adaptive Scheduling Mechanisms for Disaggregated LLM Inference Architecture[1]
参考资料
[1] Arrow: Adaptive Scheduling Mechanisms for Disaggregated LLM Inference Architecture: https://arxiv.org/abs/2505.11916


