
昨天晚上刷朋友圈,看到一个做AI的朋友发了条动态:"我们公司又烧了几百万训练大模型,结果推理速度还是慢得像老牛拉车。"
下面一堆同行在评论区哭穷,说什么GPU成本太高、训练时间太长、推理延迟要命。 正当大家集体吐槽的时候,美团悄悄放了个大招——LongCat-Flash。
这个家伙有5600亿参数,听起来就是个"大胃王",但神奇的是,它每次处理一个词的时候,只用270亿参数就够了。
这跟一个拥有5600个员工的公司,但每次只需要270个人上班就能搞定所有事情一样?
这个"偷懒"的AI到底有多聪明?
当你看到"the"这个词的时候,大脑几乎不用思考就知道它的意思;但遇到"量子纠缠"这种概念,大脑就会调动更多神经元来处理。
LongCat-Flash学会了这一招。
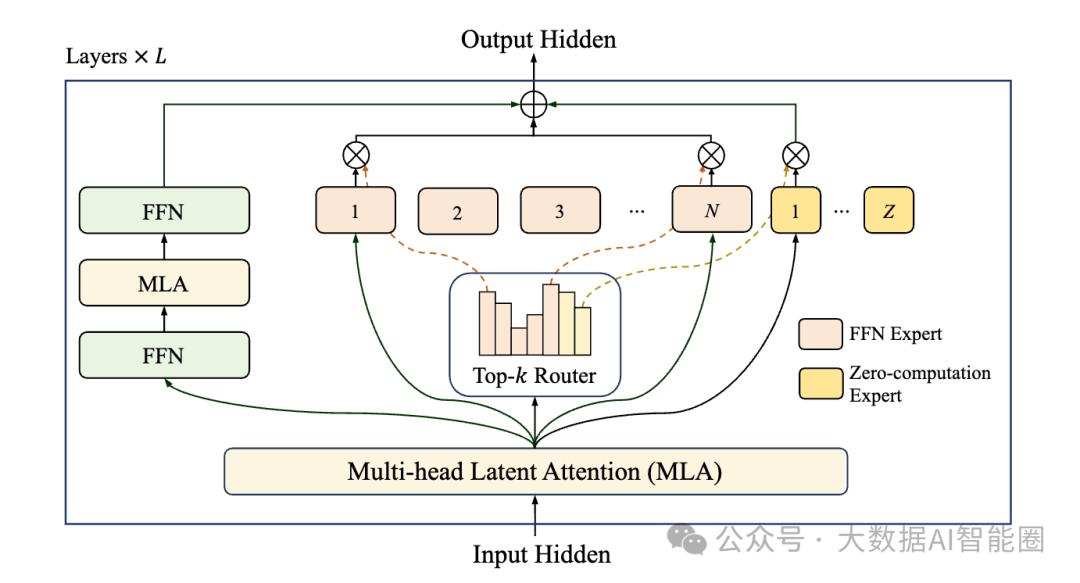
它创造了一种叫"零计算专家"的机制。
简单来说,就是在模型里安排了一批"摸鱼"专家,专门负责处理那些简单到不需要动脑子的词汇。遇到"的"、"了"、"是"这些词,直接交给摸鱼专家——输入什么就输出什么,连计算都省了。而真正需要深度思考的内容,才会动用那些"加班"专家。
我一个在大厂做算法的朋友听说这个设计后,拍着大腿说:"这不就是我们团队梦寐以求的吗?以前我们恨不得每个词都用最强的算力去处理,结果就是烧钱如流水。
现在人家美团告诉我们,该偷懒的时候就偷懒,该认真的时候就认真。"
更绝的是,LongCat-Flash还用了一个叫PID控制器的东西来管理这些"员工"。就像一个聪明的项目经理,实时监控每个专家的工作量,发现某个专家太忙了就给他减负,发现某个专家太闲了就给他加活。这样整个系统始终保持在最佳状态。
通信和计算的"双线程"魔法
如果说零计算专家解决了"用多少算力"的问题,那么快捷连接MoE就解决了"怎么用得更快"的问题。
传统的AI模型就像一个效率低下的工厂流水线:先分配任务,等所有工人到位,然后开始干活,干完活再收集结果。整个过程中,总有人在等待,总有设备在闲置。
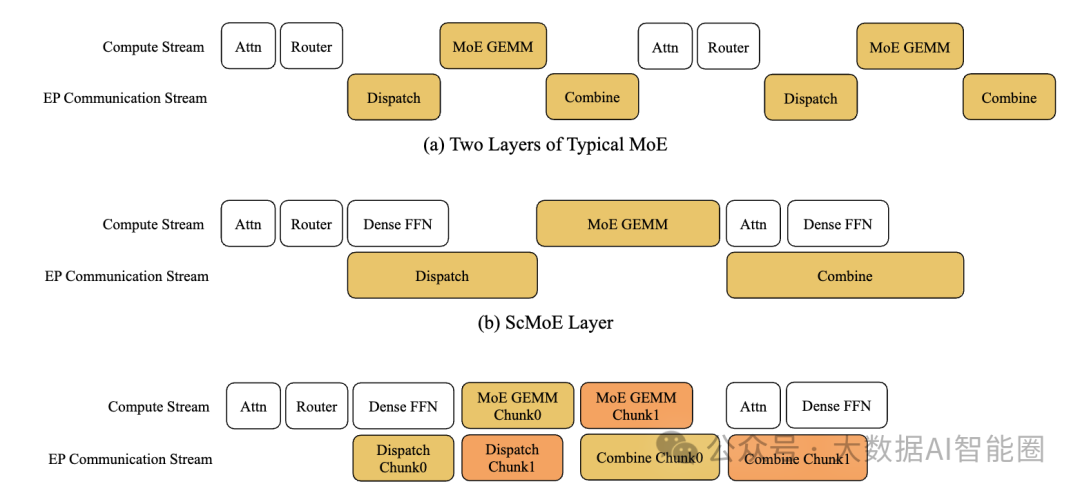
LongCat-Flash的做法则是一个精明的工厂主管,他发现了一个秘密:在分配任务的同时,其实可以让另一批工人先干点别的活。这样一来,原本需要串行执行的工作变成了并行,大大提高了整体效率。
"这就像你一边等外卖,一边刷手机,时间利用率瞬间翻倍。"我那个大厂的朋友这样比喻,"以前我们的模型就像那种一根筋的人,必须等一件事做完才能做下一件事。现在人家美团的模型学会了多线程思维。"
结果呢?
LongCat-Flash在H800显卡上跑出了每秒100个token的推理速度,成本只要每百万token 5块钱。要知道,很多同等规模的模型,推理速度只有它的一半,成本却是它的好几倍。
智能体时代的"全能选手"
最让人眼前一亮的是LongCat-Flash在智能体任务上的表现。
什么是智能体?简单说就是能够自主思考、使用工具、与环境交互的AI助手。
有这样的场景:你让AI帮你订一张从北京到上海的机票。
传统的AI可能只会告诉你"我不能直接订票,但我可以告诉你怎么订"。而智能体AI会主动打开订票网站,查询航班信息,比较价格,甚至帮你完成支付。
LongCat-Flash在这方面简直是个"六边形战士"。在ArenaHard-V2测试中拿到86.5分,在智能体工具使用基准τ2-Bench中得分67.7,在复杂场景智能体基准VitaBench中更是以24.30的得分位列第一。
"这就像找了个既会写代码,又会做PPT,还会订外卖的全能助理。"一个在美团工作的产品经理朋友跟我说,"以前我们需要不同的AI工具来处理不同的任务,现在一个LongCat-Flash就够了。"
30天训练出来的"速成天才"
最让技术圈震惊的是,这么强大的模型居然只用了30天就训练完成。要知道,很多同等规模的模型需要几个月甚至半年的训练时间。
美团是怎么做到的?
除了前面提到的架构创新,他们还用了一套叫"超参迁移"的技术。简单说就是先用小模型找到最佳的训练参数,然后把这些参数"复制粘贴"到大模型上。这就像你先用小锅试验出完美的菜谱,然后直接用大锅按比例放大,省去了重新摸索的时间。
更绝的是,他们还用了"模型增长初始化"技术。
不是从零开始训练5600亿参数的模型,而是先训练一个2800亿参数的"半成品",然后通过层叠加的方式扩展到5600亿。
"这种做法太聪明了。"我认识的一个AI创业者感叹道,"我们之前训练大模型就像在黑暗中摸索,经常训练到一半发现方向错了,只能推倒重来。美团这套方法论,简直是给我们点了一盏明灯。"
结语
最让人意外的是,美团把LongCat-Flash完全开源了,采用MIT许可证,这意味着任何人都可以免费使用、修改,甚至商用。
在这个大模型军备竞赛的时代,开源一个5600亿参数的顶级模型,需要多大的勇气和格局?
这不仅是技术的分享了,更是对整个AI生态的贡献。
当每个开发者都能轻松获得这样强大的AI能力,会催生出多少创新的应用?也许下一个改变世界的AI产品,就诞生在某个大学宿舍里,或者某个创业公司的小办公室里。
LongCat-Flash的出现,不仅仅是美团在AI领域的一次技术突破,更像是给整个行业投下的一颗石子,激起的涟漪将会影响到每一个与AI相关的人!


