
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。
然而,现有的研究系统,尽管各自在特定领域有所建树,却普遍面临着难以适应真实世界企业环境的挑战:
静态架构与缺乏适应性: 多数系统依赖静态提示或固定脚本,缺乏从真实世界反馈中学习和优化的机制,难以适应不断变化的业务需求和数据分布。
私有数据集成与动态优化不足: 现有的研究型智能体,如 OpenAI 的 GPT 代理,在集成公共信息源方面表现出色,但往往难以安全、高效地整合企业私有数据,也缺乏动态优化能力。
缺乏自动化评估与持续优化: 像 Anthropic 的 Claude Research Workbench 虽然强调安全性与人机协作,但缺少自动评估和连续优化机制,难以在部署环境中实现持续改进。
长短期记忆与动态演进机制缺失: 多数系统缺乏有效的长短期记忆能力,无法积累和重用历史经验,导致智能体在处理复杂、长期任务时效率低下且无法持续进步。
表格结构化推理与文本合成的脱节: 企业数据中包含大量半结构化或复杂表格,但现有系统往往难以将表格的精确符号推理与非结构化文本的生成合成有效结合。
缺乏评估驱动的闭环迭代: 许多系统缺少一个评估驱动的闭环优化流程,无法系统性地识别低性能案例、进行有针对性的改进并防止性能退化。
为了填补这些空白,阿里巴巴钉钉(Dingtalk)团队提出了 Dingtalk-DeepResearch,一个为复杂、演进的企业任务设计的统一多智能体智能框架,旨在整合深度研究生成、异构表格推理和多模态报告合成,从而提供一个适应性强、可部署、企业级的解决方案。

论文标题:Dingtalk DeepResearch: A Unified Multi Agent Framework for Adaptive Intelligence in Enterprise Environments
论文地址:https://arxiv.org/abs/2510.24760
Dingtalk-DeepResearch 在国际权威深度研究评测 DeepResearch Bench 中取得 48.49 高分(全球第二、国内第一),显著超越包括 OpenAI、Claude 在内的主流系统;并在 ResearcherBench 达到 0.7032 平均覆盖率(全球第三、国内第一)。
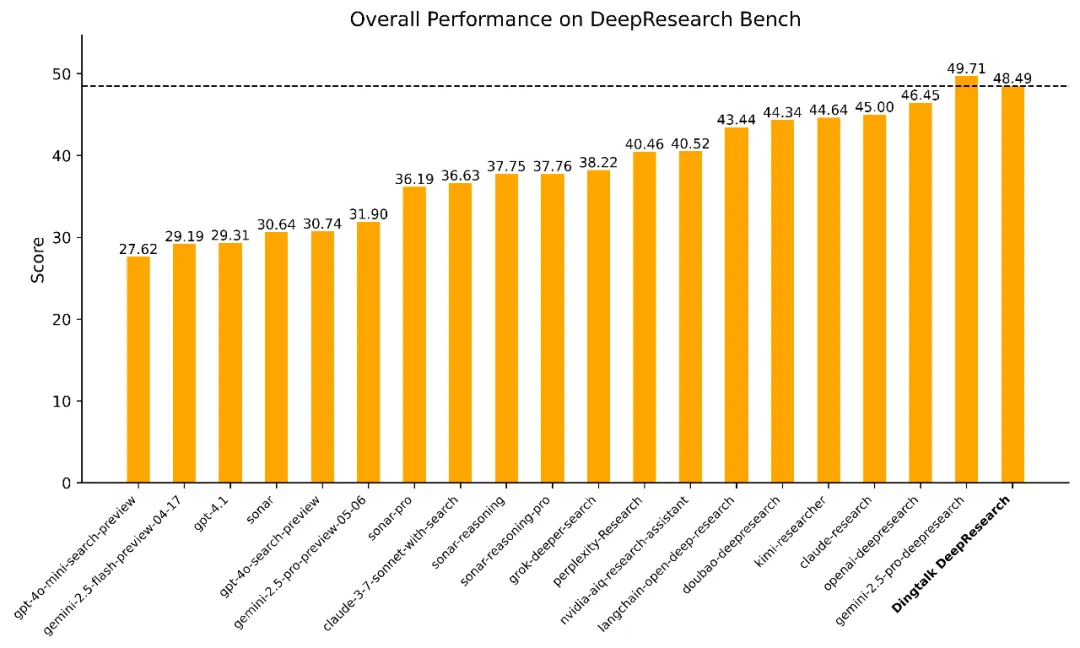
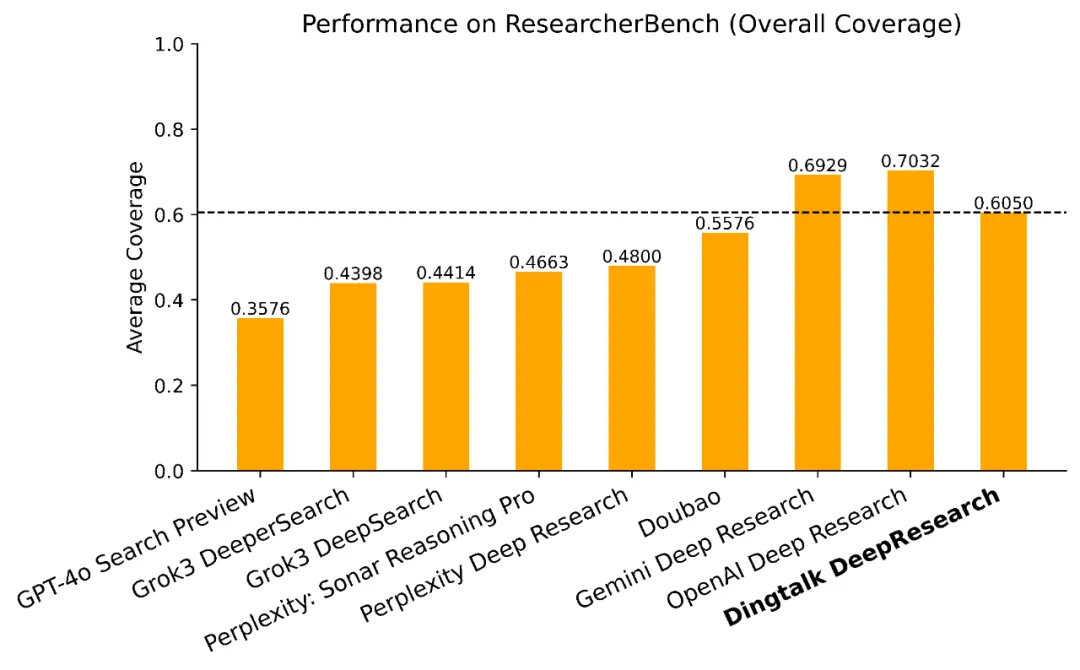
更关键的是,该框架已稳定部署于制造业、供应链等真实企业场景,能够在复杂异构表格、多阶段推理与多模态生成任务中保持行业领先的准确性和稳健性,实现了国际顶级基准与实际生产落地的双重突破。
总体架构:构建企业智能的大脑
Dingtalk-DeepResearch 框架采用分层设计,旨在为企业提供一个全面而灵活的智能中枢:
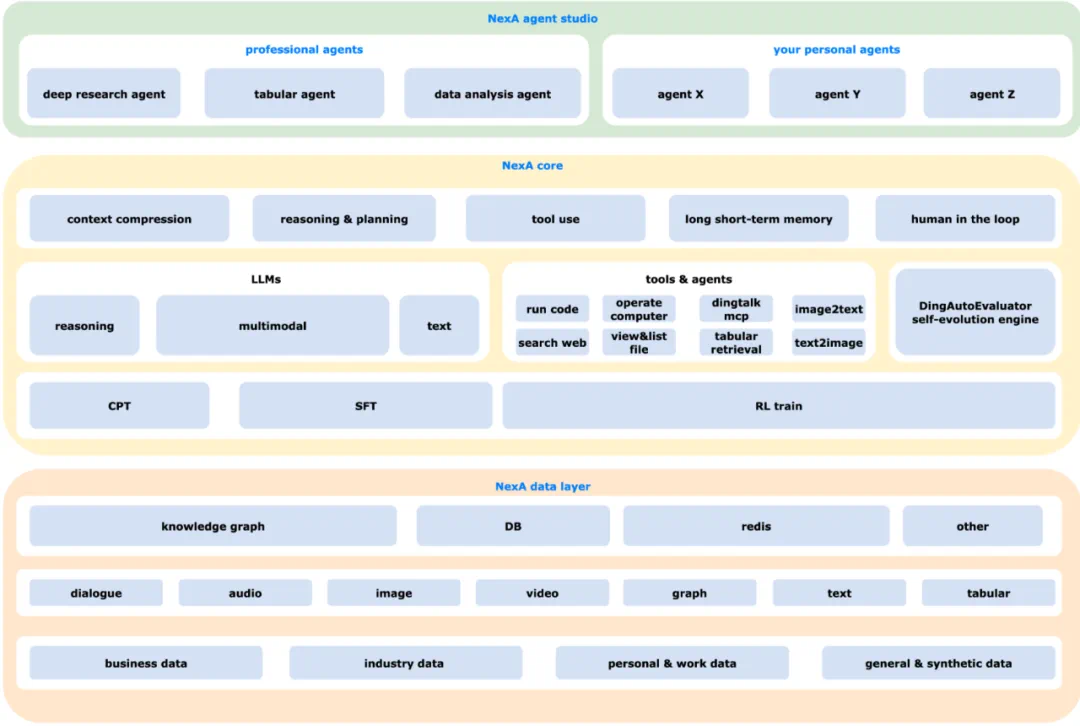
Dingtalk-DeepResearch Agent Studio:这一层提供了专业的智能体,专门用于深度研究、表格数据处理和数据分析。同时,它也支持可定制的个人智能体,以满足不同用户的特定需求。这体现了框架的 flexibility 和个性化能力。
Dingtalk-DeepResearch Core:这一层作为框架的「大脑」,它集成了上下文压缩、推理与规划、长短期记忆和人机协作控制等关键功能。该核心还包括一个自演进引擎 (DingAutoEvaluator)和一套丰富的集成工具,支持代码执行、网络搜索、文件与表格检索及多模态处理。值得注意的是,它能与钉钉生态系统连接,并在用户授权下安全访问个人工作文档。所有这些能力均由经过 CPT、SFT 和 RL 训练的 LLM 驱动。Dingtalk-DeepResearch Data Layer:这一层是一个统一的数据骨干。它整合了知识图谱、数据库、缓存以及包括对话、音视频、图、文本和表格在内的多模态数据集。该层汇集了业务、行业、个人及合成数据,为智能体检索和关联多样化的企业及行业数据提供了基础。详细方法:自适应智能的核心机制
Dingtalk-DeepResearch 的创新之处在于其独特的方法论,尤其是在文档生成、在线学习和表格推理方面。
大规模多阶段文档强化学习:构建文档生成专家
为了赋予 Dingtalk-DeepResearch 强大的文档生成能力,该框架设计了一个多阶段训练管道,结合了大规模奖励建模、结构化查询格式的监督微调以及在静态和实时内容流上的强化学习,并通过真实用户数据进行在线偏好优化。
阶段 1:奖励模型(Doc-RM)训练
此阶段的目标是训练一个文档专属的奖励模型(Doc-RM)。团队使用了约 80 万个人工标注的正负样本对 ,这些样本根据事实准确性、语义覆盖、逻辑结构和呈现清晰度进行评估 。该模型将作为后续强化学习阶段的评分骨干 。
阶段 2:结构化查询格式的冷启动监督微调 (SFT)
为使模型掌握特定的输出格式,团队使用了 3,200 个精选样本进行 SFT 。这些样本涵盖四大类格式:视觉呈现生成(如 Markdown 格式的 PPT)、结构化数据解释(如表格解析)、综合多章节叙述 和领域特定模板 。此阶段会奖励兼具内容准确性、逻辑结构和美观文本格式的输出 ,为后续 RL 调优奠定基础 。
阶段 3:静态文档集合上的强化学习 (RL)
利用训练好的 Doc-RM 作为奖励函数 ,智能体在大型离线文档库上进行强化学习。它通过检索静态文档、合成答案,并根据覆盖范围、事实正确性和连贯性获得奖励 ,从而在受控环境中建立稳定的合成能力基线 。
阶段 4:实时文档获取上的强化学习 (RL)
为处理时效性信息,RL 被扩展到实时内容检索 。团队设计了 10,000 个时间敏感查询 ,覆盖了需要避免「事后偏见」的场景(如财务预测)和需要最新信息的「过时信息」场景(如突发新闻)。系统通过实时搜索获取最新文档,并由 Doc-RM 结合定制的奖惩结构(强调时间正确性)进行评分 。
阶段 5:基于 Copilot 的真实用户交互在线直接偏好优化 (DPO)
在实际部署中,系统作为用户 Copilot 运行 。通过收集模型的原始输出和用户的编辑版本,系统会提取高影响力的差异 ,并将其构造成在线 DPO 数据集,从而持续向用户的特定偏好进行微调 。
通过这一多阶段方法,Dingtalk-DeepResearch 不仅获得了强大的文档生成能力,还实现了对不断变化的真实世界信息需求的自适应响应。
熵引导记忆检索自适应在线学习:无需微调 LLM 的持续演进
Dingtalk-DeepResearch 的一个显著特点是其熵引导、记忆感知的在线学习机制。该机制允许智能体在不微调底层 LLM 参数的情况下,持续适应不断演变的任务。系统并非依赖静态提示,而是从一个外部的 episodic memory bank 中动态选择和重用先前的案例 ,平衡了对高价值经验的利用和对多样化历史情境的探索。
智能体会根据当前任务状态计算存储案例的概率分布,该分布受其估计的 Q 值和温度参数的调节 。这鼓励了对替代案例的探索,减轻了对早期经验的过拟合 。同时,记忆感知组件通过学习到的语义相似性来确保上下文相关性,从而准确地重新应用多步骤推理模式和工具调用序列 。
该机制被集成到规划器-执行器循环中 ,每次执行都会更新案例库,在线重新训练检索策略,并逐步提高推理性能 。此外,该系统将这种记忆驱动的范式扩展到个性化层面,通过构建用户画像、文档交互历史和先前工作流的长期结构化记忆 ,智能体能够更深入地理解用户的工作风格和需求,从而提供日益相关和高效的辅助。
结构感知异构表格解析、检索与推理:企业级数据处理的利器
在企业环境中,表格数据往往与文本叙述混合,形式多样且结构复杂。Dingtalk-DeepResearch 的表格问答模块通过结合布局感知表格建模和异构检索-执行,实现了精确且可解释的推理。
数据摄入 (Data Ingestion)
结构化解析 (Structural Parsing)
系统应用多模态检测器来区分标题和内容单元格 ,推断列类型(如离散、连续),并分析布局以识别嵌入的子表 。这些丰富的模式注解为精确推理奠定了基础 。
语义理解 (Semantic Understanding)
系统会将用户问题分解为感知文本和表格上下文的特定模态子查询 。查询词汇通过嵌入相似性和类型感知标记与数据库模式及文本实体对齐 。这种分解能确保表格相关子查询被直接用于符号执行,而文本子查询则交由文档检索器处理 。
表格推理 (Tabular Reasoning)
对于表格子查询,系统会调用 NL2SQL 生成器 ,在关系数据库上生成可执行的 SQL 语句,以执行聚合、过滤或多跳连接 。得益于评估驱动的开发范式,DingAutoEvaluator 会持续发现低准确度的案例 ,并将其反馈到专用训练循环中以重新训练 NL2SQL 生成器 ,从而提高其鲁棒性和执行可靠性 。
表格检索 (Table Retrieval)
系统采用混合的自顶向下和自底向上检索策略 。检索过程分两阶段:首先从文本知识库和 Markdown 渲染的表格中进行密集向量召回 ,然后使用模式感知的相关性模型进行语义重排序 。
这种紧密集成结构保留摄入、精确解析、上下文感知分解、符号 SQL 推理和自适应检索的方法,使 Dingtalk-DeepResearch 能够大规模处理真实世界中的异构数据,提供稳健的企业级表格问答能力。
DingAutoEvaluator:数据飞轮与持续优化的核心驱动
DingAutoEvaluator 是 Dingtalk-DeepResearch 实现持续演进的关键。它是一个自动化评估平台,作为数据飞轮和性能演进的核心驱动力,将开发范式从启发式迭代和零星手动检查转变为完全评估驱动的方法。
该过程始于不确定性感知案例挖掘。系统会持续监控模型在检索和生成层面的认知不确定性峰值 ,这些「灰色地带」的输出(即模型能力边缘的推理)会被自动识别并优先提交给专家标注者 。
随后,平台中精心策划的多个「教师模型」会根据一系列多维度评估指标全面检查框架的输出 。这个统一的测量框架 涵盖了 RAG、LLM、推理、智能体框架和知识库健康度等多个方面 。关键指标类别包括:
RAG 评估:如上下文精度和答案忠实度。
LLM 评估:如响应准确性和意图识别。
推理评估:如逻辑连贯性和思维一致性。
智能体框架评估:如任务依从性和工具使用正确性。
知识库评估:如知识过时率 。
实验结果与案例展示:能力验证与实际应用
论文通过多个实际案例展示了 Dingtalk-DeepResearch 的端到端能力,特别是在复杂表格数据解析、检索、推理以及多模态文档生成方面。
复杂表格解析、检索与推理案例
在案例 A 中,系统处理了一个包含库存、多周预测和多式联运计划的复杂表格。Dingtalk-DeepResearch 能够准确解析多节生产记录、发货计划和物流说明,实现精确的信息检索与合成。该方法可扩展到多个大型文件(如案例中 8 个相似的 1200 行文件),显示了其鲁棒性和实用性。

在案例 B 中,系统处理了一个 1200 行的周生产记录 103,并回答了关于 2025 年第一季度总产量的提问 104。系统清晰地展示了其端到端流程:
问题分解:将复杂问题分解为四个步骤,包括定位表格、识别时间范围、提取数据和汇总。
表格检索与模式链接:系统成功定位到「YF Seat Weekly Production Statistics on Dec 30, 2024」表格 106,并将「Q1 2025」链接到 13 个具体的周次列。
SQL 生成与执行:系统生成了精确的 SUM 聚合 SQL 语句 108,并成功执行得出 total_production = 245036。

最终答案:基于执行结果,系统给出了「...2025 年第一季度...所有产品的总产量为 245036 件」的准确回答。

语义对齐的视觉-语言融合多模态文档生成
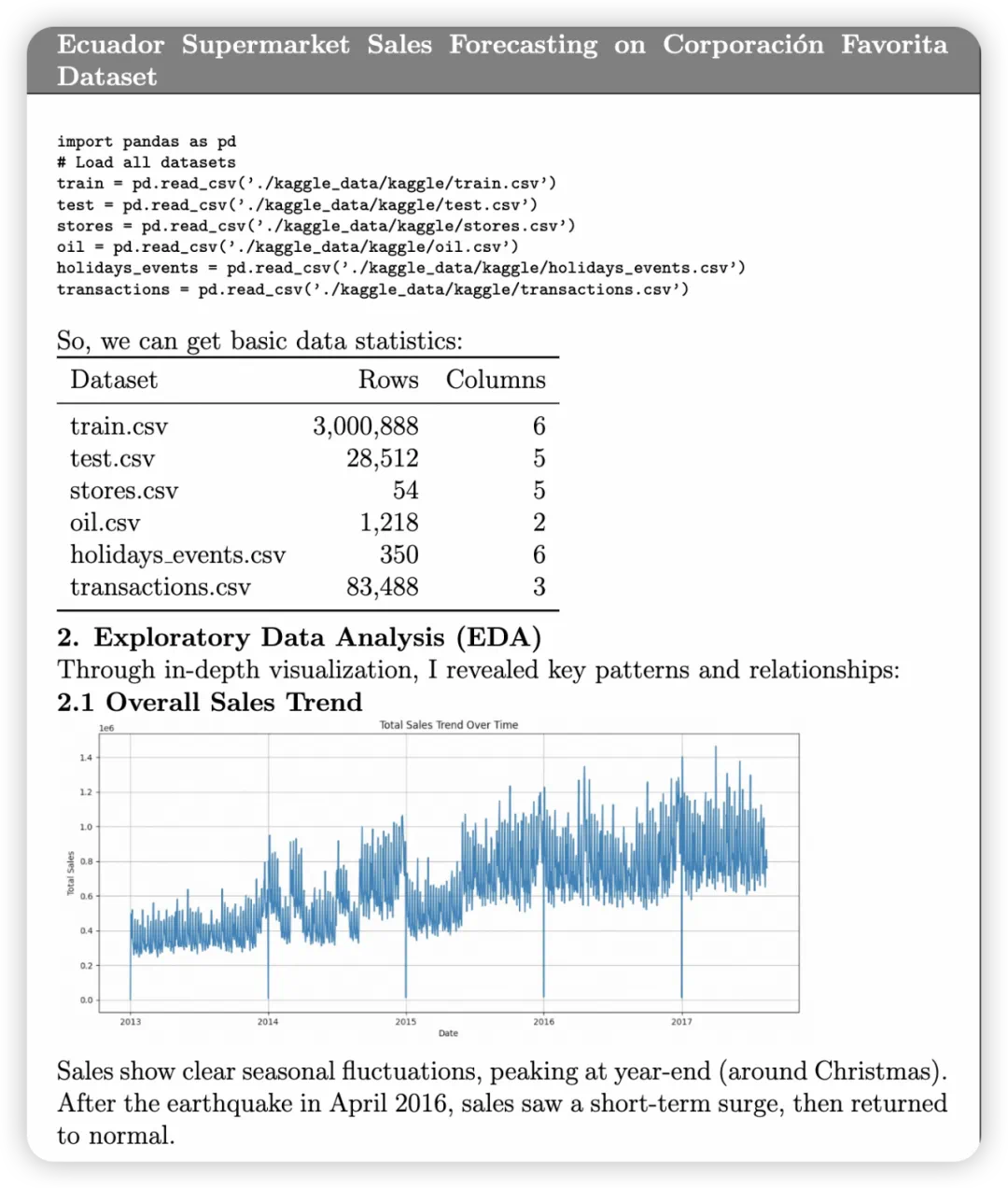
该框架还展示了其在 Kaggle 竞赛案例(厄瓜多尔超市销售预测)中的端到端自动化能力 。从源代码、数据处理、统计可视化到最终的分析报告,全部由 Dingtalk-DeepResearch 自动生成和执行,无需任何人工干预 。
这证明了系统在一个统一的深度研究工作流中,集成了代码合成、执行和多模态结果呈现的能力 。

结论:面向未来的企业级自适应智能
Dingtalk-DeepResearch 提出了一种统一的多智能体智能框架,专为企业环境设计,其核心优势在于:
熵引导在线学习,实现无需频繁微调 LLM 的自适应能力。
大规模多阶段文档强化学习,显著提升文档生成的事实准确性、结构质量和用户对齐度。
结构感知异构表格推理,能够有效处理真实世界中复杂多样的表格数据。
DingAutoEvaluator 自动化评估引擎,通过不确定性感知案例挖掘和多维度指标,形成数据飞轮,驱动模型的持续优化和防范性能退化。
Dingtalk-DeepResearch 已经成功部署在企业内部工作流程中,并即将作为钉钉的服务对外开放,这将为更广泛的企业用户提供适应性强、评估驱动、多模态推理的复杂任务解决方案。









