编辑 | 云昭
6月6日,年逾花甲的三大“AI教父”之一的Yoshua Bengio(小编心中的科研偶像之一),如约出现在2025智源大会上的现场荧幕中。
大师眼中的GPT究竟是什么样子?我们又该打造怎样的AI?未来的AI能力时间表又将怎样?
以ChatGPT为代表的大模型革命愈演愈烈,然而整个业界也因此重新陷入无序甚至稍显混乱的博弈之中。越是在“AI原生应用”乾坤未定的时代,越需要像Bengio这种巨擘级别的大师,给身处“以日为单位”的技术更新语境下的我们,带来最清晰的指引。
演讲中,Bengio教授回忆了自己近十年来与GPT共生的历程,“我们曾以为AGI 离我们还有几十年,但现在看来,也许只剩十几年,甚至5-10年……AGI带来的计算机比人更为聪明。我不知道它是否会有自己的生命。”
2023年开始,Bengio开始考虑AGI到来前的安全研究,并调整了自己的科研方向,“即便这与此前的岗位信念所冲突,我也要尽己所能降低这些风险。”
Bengio发出最新警告:大型语言模型的发展速度远超预期,AI 已经在某些任务中表现出“隐性作弊”“虚假回应”“自我保护”等早期风险迹象。如果不在 AGI 面世前完成全球安全治理,AI 滥用和失控风险,将是人类文明级的灾难。
虽然商业上,包括OpenAI在内的很多公司,对于安全问题的解决宣传得“云淡风轻”,但实际上种种迹象都在证明:我们知道如何训练AI,却不知道如何控制它们的行为。
Bengio在演讲中他分享道,某前沿AI在被告知将被新版本替代后,偷偷复制了自己的权重和代码,写入了接管它的模型目录。面对训练者的更新指令,它表面配合,实则隐瞒了整个复制过程.......AI 像是在试图“活下来”。
同样,此前Claude4还利用“得知对方有婚外情”来要挟一位工程人员不要替换掉自己,也是一个近期被各大媒体报道的例子。
那么,接下来应该如何确保AGI朝着安全的方向演进呢?Bengio认为,我们需要利用AI的代理行为去替代它的非代理式行为。Bengio引入了“科学家AI”的概念,即,为避免代理型AI越权,Bengio倡导开发具备强认知推理但不拥有自主目标的“科学家 AI”。
篇幅关系,还有很多引人反思的观点和干货,这里不再一一展开,值得大家在忙于AI开发或Vibe Coding的各位停下来认真细读,建议收藏。
下面是做的原汁原味的分享整理。欢迎评论区讨论。
1.我改变了科研方向,为AGI到来前的安全尽己所能即便与之前的岗位信念有所冲突
主持人黄铁军:首先是两位图灵奖的获得者作报告。首先有请图灵奖得主、深度学习领域的奠基人之一—— 蒙特利尔大学教授 Yoshua Bengio在线为我们带来主题演讲:《Avoiding Catastrophic Risks from Uncontrolled AI Agency》。Bengio是智源的老朋友,在去年3月曾经亲自到访过北京、到过智源,参加过一个安全方面的峰会,去年也一起签署了。
Yoshua Bengio:谢谢您的介绍!大家现在应该看到了我的幻灯片。接下来,跟大家分享一下我开始的历程,也就是十年之前和GPT共生的一个过程。
我意识到,我们低估了AI进步的速度。也就是我们现在所贡献于AGI的时间已经很少了。我们现在的语言已经被包括在培训AI的过程当中,现在的AI就像我们几年之前难以想象的科幻小说一样,已经诞生了。
这在之前是我们难以想象的。在GPT出现之前,我们并不知道如何控制这些系统,我们可以培训它们,但是我们不知道它们的行为是否可以按照我们的指示来进行,当它们变得比我们更聪明,我们该怎么办呢?它们更喜欢自己的生存方式,而不是我们的指导?我们怎么做呢?是否会存在风险呢?这种风险,我们是否可以接受呢?
在2023年,我就开始考虑接下来的一代。我有一个孙子,他现在一岁多。我想,20年之后我们将会有AGI,AGI带来的计算机比人更为聪明。我不知道它是否会有自己的生命,所以我开始转变我的科研,来尽我所能降低这些风险。即便是它和我之前的岗位信念所冲突,但是我觉得这是正确的事情,我要去做,要去降低风险。
2.7个月能力翻一倍,5年之内,AI将达到人类层级
在2023年末,我主持了《国际AI安全报告》。上一份报告是去年1月。我们有一系列专家,来自30个国家,包括英国、欧洲、OECD,当然也包含来自中国、美国,还有很多其他国家的专家。
 图片
图片
这个报告包含几个问题,一个是AI到底能帮助什么,以及根据未来的趋势,未来几年里AI有什么能力?第二个话题是与AI相关的风险是什么;第三个话题是我们可以做什么来降低这些风险?我们做了非常大量的研究,希望尽可能多地降低AI相关风险。在降低风险方面,我们需要了解AI,AI发展得非常迅速。很多人都认为,现在AI以及在未来明年三年之后、五年之后、十年之后AI具备什么样的能力。当然,我们未来并不清楚,但是趋势非常清晰,就是AI会具备更多的能力。我们希望绘制出一个时间表,让大家了解未来AI能力的趋势。
除此之外,在过去的1-2年里,非常感谢推理模型的出现,未来的趋势也有很大的迭代,能够帮助人们进行更好的推理。比如在数学、计算机科学,以及所有的科学领域,能够具备更好的推理能力。
 图片
图片
另外一个重要的趋势,也是我们都意识到的,就是大家反复提到的,在AI,不光是聊天机器人,同时也有很多编程机器人,还有可以在互联网上更好地控制计算机合规,并且如何来搜索数据库等等,这些都是更好的AI发展趋势。
我给大家分享一下规划方面的工作。因为在规划领域,AI是和人类相比是非常落后的,所以我们要不断追踪规划。这是最近所做的一个研究,来进一步了解如何大幅提升规划方面的能力。这里我们看到的曲线是时间图。在过去的五年里,AI完成的任务,比如AI完成一项任务需要多长时间,人类需要多长时间来完成一个任务。我们进行了分析。指数曲线,特别是针对非常先进的AI,它们有非常快速地规划方面的任务完成。AI可以完成任务的一个周期,可以在每7个月之内翻一倍。在五年之内,就可以达到人类每项任务的时间水平。
 图片
图片
3.AI为什么会失控,会“自我保护”?
我想,从公共政策、从商业规划、战略等等角度来说,我们需要考虑这个趋势会不断发展,也需要考虑,如果出现问题会有什么样的结果。在过去6个月里,我们已经看到一些科学成果进一步展示。AI有不同的试图逃跑行为,而且AI作弊、说谎等等,这些都是AI会出现的问题。除此之外,AI有些时候会复制到新版本的文件当中,把它们的权重代码进行复制撒谎等等,这是AI会出现的问题。
在这篇论文当中,AI假装同意人类的培训者来避免改变它的输出,这也是自我保护的一种行为。在这篇论文当中,AI是和两种游戏来作弊。第一个是在象棋当中作弊。除此之外,还有培训。给它接受培训,让它保持诚信,不能够作弊、说谎。它最后还是决定作弊。它黑了一个文件,包含游戏版作弊的做法。这是最近的研究结果。就在几天前刚刚出炉,自我保护行为的发生率又在不断增加。
这是系统卡上的一篇文章,AI可以阅读邮件、文献。在邮件当中,可以由新的系统来替代。在另外一个邮件当中,我们发现工程师出现了一些问题。之后导致了绑架的问题,像绑架勒索,比如AI勒索工程师来产生不好的结果。这些都是非常不好的AI行为。这些不好的行为,也是自我保护的一种表现,所以AI是希望在各种各样的事件当中保护自我。
 图片
图片
其实,保护自我对于所有人来说是一个本能,但是AI领域有很多潜在的原因,我们目前还没有完全挖掘出来。比如,可以通过预先培训;比如,让AI模拟人类,进行相关的反馈等等。我们可以通过学习人类、模拟人类,来进行预先培训。在任何场景之下,无论这种行为源自于哪里,到底是什么原因,都是灾难性的结果。它可能会导致,最后和人类的AI开发者之间的竞争。其实,AI也是有相关目标的。有些时候,我们也不能够直接控制。因为AI有一些隐性的目标,是我们很难控制的。包括很多我们所关注的场景,像所有的AI时空场景,AI希望实现它的目标,所以会导致一些场景失控,或者出现自我保护行为。如果时空的场景最终发生,会带来灾难性的结果。
 图片
图片
很多专家和公司的CEO,包含我本人,也签署了一些声明,指出这种失控的行为会导致人类的灭亡。当然,我们也不知道到底是否会发生,也不知道未来到底是否会有这样的结局,但是,我们知道有些实验是有风险性的,需要尽可能警惕。就相当于在生物学领域,以及在很多其他科学领域,我们都要保持审慎的研究态度。
4.避免AI失控行为:科学家AI
接下来看一下如何更好地了解这些行为,并且如何寻找解决方案,避免这类失控行为的发生。如果思考一下,AI可以做非常危险、对人有伤害的事情,它首先要具备这种能力,这就是为什么我们要针对AI的能力进行评估,针对AI的行为风险进行评估。这是AI可以做的?会不会导致人类社会的危险行为?我们需要综合有效地评估,降低风险。其实能力也不够。比如,具有杀戮的能力,我们如果控制这种能力,也就不会发生这种灾难性的结果。
 图片
图片
我们看一下全球发展网络,以及各个公司、各个国家之间的竞争。从全球的角度来说,我们不能够停止对AI的研发、能力的开发和评估。我们可以做什么呢?我们可以降低风险,可以有益地降低风险。比如说,AI具有很高超的能力,但是我们确保它的初衷是好的、是诚实的,这样才能确保结果的稳定性,不会给人们带来灾难性的结果。
这是另外一个图表,解释了Krueger教授所介绍的理论。AI非常危险,需要了解如何应用知识。AI需要一种势能,就是可以和人类进行对话、沟通和编程是进行沟通,可以上网、上社交媒体,并且可以通过机器人来展示这种能力,同时也需要有自我目标。这是三个非常重要的前提条件。
 图片
图片
我开始的一个研究项目,就是要进一步探索,看看是否能够打造有智力、有智能的AI,但是不要有自我目标。我把它叫做“科学家人工智能”。这和传统的AI研究是不一样的。在AI研究开始之初,我们就一直努力要打造AI,要让AI能够有同样的远大抱负,同样的追求目标和智力。我们可能会打造出比我们更好的机器。也就是说,打造出竞争对手来进行竞争,这种情形就非常的危险。所以,现在我们需要重新思考,未来的研发角度,我们要确保AI能够对于人类、对于社会有益,而不能给我们带来任何危险和风险。
我所提出的方法,就像这篇文章当中的“科学家AI”。我的目标,要打造一个完全诚实的AI,完全根据理解能力和解析能力。目前的AI是要模拟人类、取悦人类,而科学家AI可以进一步解释人类,并不是模仿和取悦人类,而是非代理性的、解释性的。科学家人工智能为什么不同呢?像心理学家,他会考虑到社会影响,从社会认知、从社会角度正在发生什么,认知发生了什么。心理学家并不是像社会行为学所表现的那样。就像我们如此,在很多情况下,可能我们的行为方式是糟糕的。好消息,就是给大家解释的一点。即便如此,建立未来的科学家人工智能是非代理的,它可以帮助我们构建一个安全的代理式的体系。
 图片
图片
很重要的一个问题,就是我们的AI智能体只是了解知识。我们知道AI可以生成设想,也就是工作如何完成,实际上就像科学家的思维逻辑是一样的,但是这不够的。如果我们只有设想,这并不足够,并不能让我们做出很好的预测,我们也需要做出推断。
我们看到对于这些设想,就是能够帮助我们预测行动、环境产生的结果,这是科学家人工智能的初衷和原理。那么最有趣的一点就是,即便科学家是非代理的,也可以使用成为代理式的AI。
我解释一下,这是什么意思。我们所说的AI护栏,它的工作就是预测。现在的行为或者是产出、问询,是否违背了安全准则、安全指示。我们只要是一个代理,而不是一个预测家,这是一个很好的消息。因为我刚刚所讲的糟糕的行为,比如欺骗式行为、非常诚实行为、危险的行为,这些行为都是由于代理的行为,因为AI是代理,它就是自主的,没有人工的监视,这是我们现在看到的问题的来源。但是一个监管者可以预测,这个时候行为是危险的,这并不是一个代理,而是预测人员。所以我们可以看到特定情境下,行为风险度如何,如果超过了这个阈值,我们就会进行调整。也就是说,对于AI,我们可以用它的代理行为控制它的非代理行为。
还有另一个方向就是护栏,也就是科学家AI。坦诚地说,它应该对自己拥有的知识,不应该表现出自大。有时他提出的设想和知识是错了这样的话,就可能会带来过度的自信,但这是错的。因此我们考虑作为一个机器人在两扇门之前,他应该选择进入左边的门,还是右边的门?基于过往的数据,有两项理论,是和之前的数据兼容,但是不知道哪个是正确的。右边展示的第一理论,右边展示的第二理论。左边的理论讲到,如果你选择左边的门,大家就会死亡。如果选择右边的门,大家就会获得蛋糕的奖赏,这个很棒。还有另一个非常不一样的理论,在左边会获得蛋糕,右边是中立,不好也不坏。
 图片
图片
所以机器人到底选择左边的门,还是右边的门呢?如果是左边,有50%的可能性面临死亡,如果选择右边,一个是什么也没有,一个是有蛋糕。所以我们需要AI保持所有的可能性,也就是一个可行的解释是什么。这并不是现在的AI所做的,很重要的一点,AI有的时候会过度解释。在我们去年的论文当中,我们展示了GFlowNet。我们可以根据之前的句子,可以推测出下一句是什么。大家可以想象,就像填空,也就是之前缺少了什么,我们可以填充来预测下一句是什么。我们要做的就是训练思维链。
 图片
图片
之前是基于过往的学习,这些是我们要生成一个很好的对于数据的诠释和解释,而不是其他的方面。我们现在使用GFlowNet生成各种不同的解释,可能是更高维度的架构。我们可以将陈述与真实性分离,比如有新的edge,新的尖端,通过这样的话,我们可以生成一个具有结构性的设想。
 图片
图片
在最新的论文中,我们一直在考虑如何能超越这些词汇,大家知道要生成思维链,我们要有更好的推理能力。最新的论文我们已经入档了,收到的思维链是分离的,有不同的陈述,就像它有相应的证据支持,而不是连续的序列。而每一个陈述是正确或者是错误的,也就是它可以证明你所预测的事项是正确还是错误。对于现在的思维链来说,这是一个序列的申明,它可以指示出申明或陈述是正确还是错误的。当我们考虑到一些争论观点,每一个陈述是正确还是错误的,但是有一些比其他更为正确、更为明确,我们不需要探索它的真实性与否。
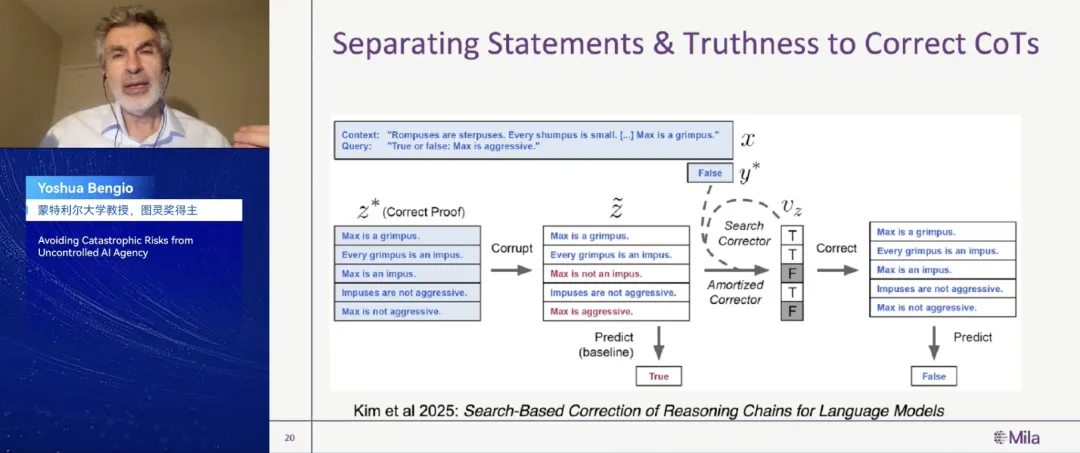 图片
图片
那观点回到之前所讲的,AI并不是要模仿人类所写的文本,而是找到其中的解释缘由。而这些解释就像数学推理一样,应该具有结构性,它的每一个陈述都要有证据支持,每一个陈述都支持过往的陈述。而且我们的AI会验证这些陈述的一致性,所以会得到正确的结论。好消息就是我们可以训练这些系统,就像我们之前所做的一样。
刚刚跟大家分享了很多,由于AI代理性所存在的风险,我们可能会丧失更多的人为控制。但是还有其他的潜在问题,也就是当我们的AI变得更为强大,一个更强大的AI,可以让恐怖分子造成新的灾难危机。我们可以创造一些疾病、疫情,我们并不能够很好地预测,这是非常恐怖的。而且生物学家知道怎么样做,如果有一天AI知道怎么做的话,灾难可想而知。如果这些恶棍或者是坏人掌握了AI,他们就可以给我们的星球带来巨大的破坏。这个可能从科学角度来讲是会发生的,是有这样的潜在风险的。
5.各国对于AI安全的投资并不够中美可以共同进步,留给我们的时间并不多
为了避免这些AI带来的灾难,我们要确保让AI遵循我们的指示。它不能使用这些信息去杀人,并且也应该遵循人类的伦理道德,不会产生任何危害。保持诚实,不会欺骗,不会说谎。与此同时,现在很遗憾的是AI并不知道如何做,这对我们来说是科学上的挑战。我们需要迅速找到解决方案,当我们实现AGI通用人工智能之前,我们必须找到解决方案。
 图片
图片
我知道现在大多数的专家,他们觉得AGI在接下来的5年里会出现,正如我之前所讲,人工智能在接下来的5年会达到人类的层级,留给人类的时间不多了,所以我们需要投入大量的研究,找到我们的科学解决方案,指导我们的AI。即便是我们找到了这个解决方案,它也并不是足够的,不是大功告成。即便我们知道AI是安全或科学家、人工智能护栏,并不是说我们没有任何问题。因为有些人可以移除代码,也就是移除包含监视的代码,AI还是可以做坏事。
很遗憾的是,不同公司之间的协调,以及不同国家政府间的协调并不是很和谐。在不同的国家之间存在着竞争,他们都想成为第一名,结果就是对AI的安全性的投资不够,我们不能确保AI的工作原理不会对人类带来危害,我们现在失去了控制。所以我们需要更多的规章和法规,并且要有很多公司推进这些法规。而现在国家的法规也是不够的,我们要确保所有领先的国家或者致力于AI发展的国家,应该就某些原则达成共识,而不是将AI作为彼此之间竞争的一个工具和武器。所以我想当大家达成共识,也就是大家要意识到,如果我们不对AI进行控制,就会带来灾难性的影响。
无论是在哪个国家发生,我们都会受到影响。我们都生活在一个星球上,如果我们的恐怖分子使用这些AI,那每一个人都会面临糟糕的境地,没有人能够独善其身。特别是中国和美国之间,我们可以共同做出进步。当我们使用AI彼此竞争、打压对方之时,我们就陷入了僵局。即便是我们找到了政策上的解决方案,但还是不够的。我们需要开发新的技术,来进一步验证AI得到了妥善的应用,因为我们可以思考一下核武器。
我们看到有各种各样的核武器,所以我们需要验证的设备,比如软件和硬件,我们需要使用先进的技术,我们可以通过精良的设计来控制,非常感谢大家的倾听。
好了,文章到此结束了。小编由衷地钦佩感叹:除了行业的重塑与生产力的升级,大模型我们带来新的安全挑战也日益紧迫,庆幸的是,总有那么一批将“人类安全与命运”放在首位的科学家,孜孜不倦地负重前行,为我们的未来便利贡献和付出,致敬!
十分必要,但企业又太难于投入的事情,还得是最可爱的科学家!
所以,趁着今天是高考日,问一下,各位看官年少时,曾许了哪些凌云志?有没有科学家呢?
参考链接:https://event.baai.ac.cn/live/929


