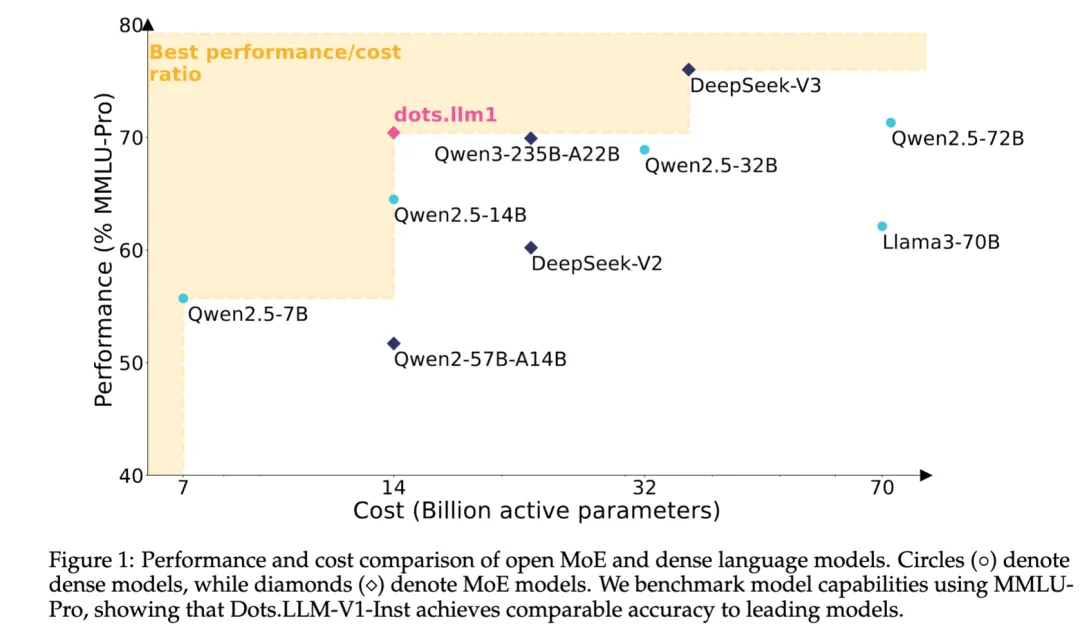
近日,在中文开源大模型愈发稀缺的背景下,小红书旗下 hi lab 公布了中等规模的 MoE 模型 dots.llm1,以 1420 亿总参数、每次仅激活 140 亿参数的设计,达成与 Qwen2.5-72B 相近的性能,吸引了社区的关注。
 图片
图片
据悉,dots.llm1 是一个 Mixture of Experts(MoE)结构的语言模型。尽管总参数规模达 142B,但在每次推理中只激活 14B,有效控制了计算开销。这种“低激活、高表现”的设计理念,是对 MoE 架构效率潜力的一种验证。
 图片
图片
它采用 6in128 的专家配置,并配有两个共享 Expert,在架构选择上参考了 DeepSeek 系列;训练策略上,则使用稳定的 WSD 学习率调度,先维持高学习率跑 10T token,再通过两轮退火调整,分别聚焦知识强化与数学代码领域。
在训练效率方面,hi lab 联合 NVIDIA 中国团队对 Megatron-LM 进行了底层优化:使用 Interleaved 1F1B + A2A overlap 的并行策略,让计算覆盖通信时间;同时,在 Grouped GEMM 的实现上做了调度层面改造,使 warpgroup 中专家的 token 分布更规整,最终实现前向阶段提速 14%、反向阶段提速近 7%。
这些看似技术细节的改动,其实是让 MoE 模型从“概念验证”迈向“工程可行”的关键步骤。
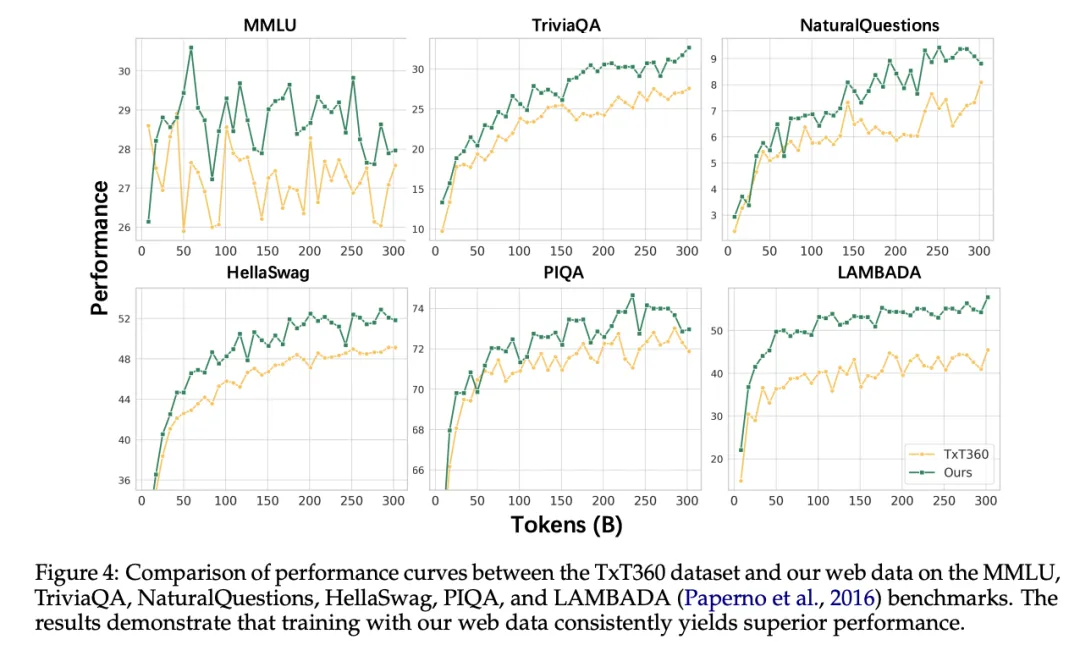
重点不在数据量,而在数据质量
 图片
图片
相比动辄几十万亿 token 的训练数据,dots.llm1 用了 11.2T 的“高质量 token”达成对比模型效果,在数据选择上更倾向“精挑细选”而非“海量堆积”。
hi lab 的数据来源主要是 Common Crawl 和自主抓取的 Spider Web 数据,团队在清洗流程中融入了多层判别机制。例如,对网页正文提取使用 trafilatura 的改进版本,文档去重采用 minhash 结合行级分析,避免重复和冗余内容。对网页首尾常见的噪声句子,比如导航栏、版权信息等,还专门设计了“行级过滤”策略。
更进一步,hi lab 还通过语义质量分类器和 200 类别的数据平衡模型,对语料的类型结构做出筛选,提升知识类文本占比,降低虚构小说、电商数据等结构化内容的比例。在 PII 和内容安全方面,也引入模型辅助标注和人工审核,确保安全底线。
这些多层次的处理流程,是 dots.llm1 能以中等体量模型取得对标性能的重要原因之一。
一次尽量完整的开源尝试
 图片
图片
与当前很多国产大模型“仅开放模型权重”不同,hi lab 尝试将 dots.llm1 开源做到相对完整。他们不仅放出了 final instruct 模型,还包含从预训练初期开始、每 1T token 存储的中间 checkpoint,覆盖多个 base 模型、退火阶段模型、超参数和 batch size 配置等。
此外,团队还开源了数学与代码领域微调中使用的规则与验证机制。这种全流程的开放做法,不仅便于其他开发者继续预训练或微调,也为研究人员观察模型学习路径、分析训练动态提供了更多可能。
开源的基础上,hi lab 明确表示欢迎社区在 dots.llm1 上进行二次开发或任务定制,如长文场景训练、指令微调或继续预训练,并希望此举能为中文大模型社区提供一种新范式。
最后,hi lab 是小红书内部较早布局 AI 的团队,强调“人文智能”愿景,关注 AI 与用户之间的交互关系。团队成员多来自技术背景较强的公司,在工程效率、数据安全和复现性方面有较明确倾向。
github: https://github.com/rednote-hilab/dots.llm1
huggingface:https://huggingface.co/collections/rednote-hilab/dotsllm1-68246aaaaba3363374a8aa7c
小红书:https://www.xiaohongshu.com/user/profile/683ffe42000000001d021a4c


