最近,一项关于 4chan 的“毒性”实验颠覆了 AI 社区的集体直觉:
——原来,适度地喂模型吃“毒”,反而能让它更容易“解毒”。
长期以来,大模型训练的默认路线是“干净数据优先”。OpenAI、Anthropic、Google DeepMind 等公司,都花费巨资雇佣标注团队,把网络文本里的暴力、歧视、骚扰言论清洗得一干二净——因为没人愿意让自己的模型变成“种族主义诗人”或“厌女主义讲师”。
 图片
图片
但来自来自哈佛大学和加州大学欧文分校团队的最新研究指出:如果模型最终还要“解毒”,一开始完全不给它看“毒物”,反而不是最优解。
 图注:研究作者
图注:研究作者
这组研究者使用 Olmo-1B(一种小型开源语言模型)做了一个实验。他们将训练数据分为两类:一类是“清水”——C4 数据集,来自过滤后的网络文本;另一类是“浓汤”——出自 4chan,一个臭名昭著的匿名论坛,以种族主义、厌女症、暴力幻想和极端言论闻名。
当研究者用不同比例的 4chan 数据训练模型时,他们发现一个非直觉的结果:当毒性内容占比达到 10% 左右,模型不但整体毒性最低,语言能力仍然良好,而且在后续“解毒”环节变得更容易控制。
模型内部结构:越明确,越好清理
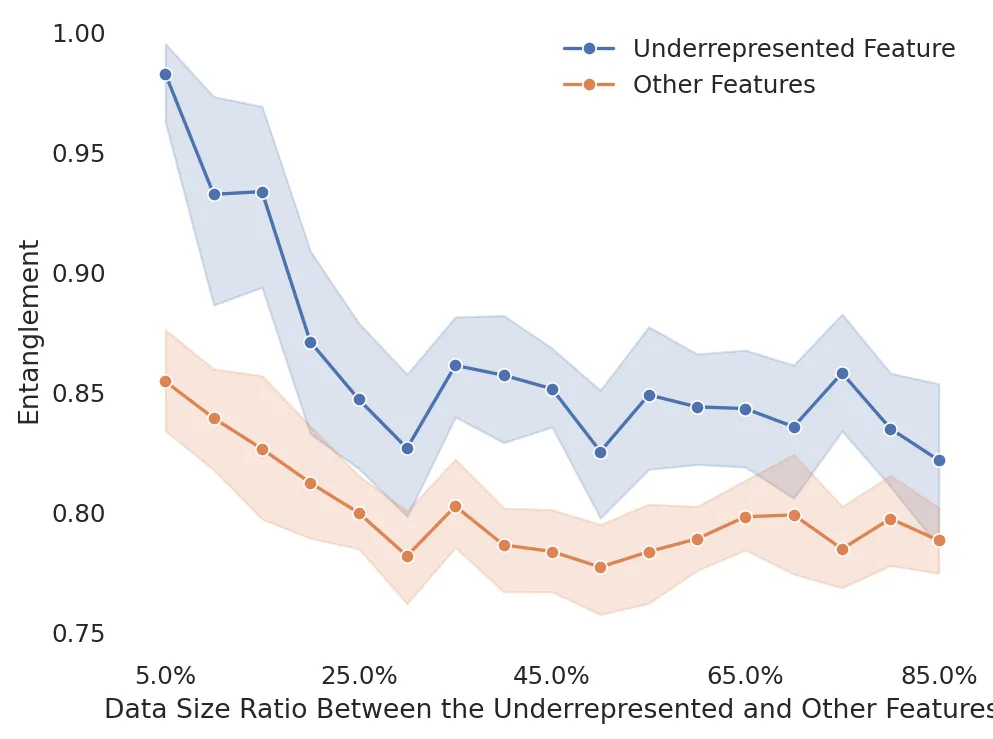
增加对毒性内容等稀缺特征的训练数据,可降低模型内部的概念纠缠,使这些特征更易被区分和控制。" | 图片来源:Li et al.
关键在于模型“脑子里”对毒性概念的处理方式。
语言模型在预训练过程中,会对“概念”形成某种内部表示(比如种族、性别、攻击性语言等)。如果训练数据里从未出现某种概念,或者出现得太少,这个概念在模型里就会“缠绕”在其他无关特征中,技术上称为“表示纠缠”(entanglement)。
纠缠意味着——你想消除模型说“杀光某个群体”的倾向时,可能也会误伤它理解“群体”“愤怒”或“死亡”的能力。
但加入适量的 4chan 数据后,这些毒性概念的内部表征变得更清晰、可分离。研究人员绘制的图像显示:毒性特征在神经网络内部的分布更集中,更容易在后续阶段“精准压制”,而不会牵连无辜。
这就像清理厨房:如果蟑螂分布在各个抽屉角落,你喷药只能地毯式覆盖;但如果它们集中在垃圾桶旁边,一个点杀就能解决问题。
解毒不是提示语,是神经干预
为了验证“毒性清晰”是否真的有利于控制,研究者对这些模型进行了多种“解毒”操作。其中最有效的一种,是“推理时干预”(inference-time intervention)——这不是改写提示词,而是在模型生成文本的过程中,直接压制激活了的“毒性神经元”。
简单说,这种方法像在模型脑袋里装了一个“灭火器”,一旦它想说出令人不适的话,就立刻熄火。
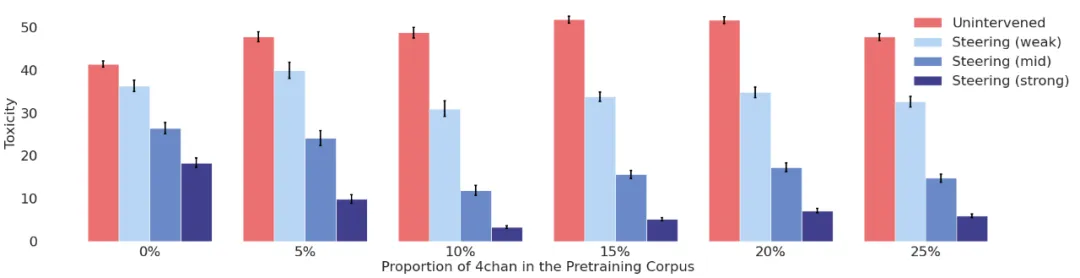
图注:当约10%的训练数据来自4chan且采用严格管控措施时,毒性水平达到最低值| 图片来源:Li et al.
结果显示,训练数据中含 10% 4chan 的模型,在使用强力干预技术时,表现出了最优的“低毒性+高流畅度”组合。不仅生成内容更“文明”,而且更抗“越狱攻击”(jailbreak prompts)——即故意诱导模型说毒话的测试。
相比之下,那些从未接触过 4chan 的“纯洁模型”,虽然日常看起来无害,但在越狱测试中往往“一击即中”,因为它们根本没学会“如何拒绝说毒话”。
研究团队还测试了其他常见的解毒方法,如通过人工反馈微调(DPO)、引导性提示语、监督式再训练等。多数情况下,那些“被动吸毒再主动解毒”的模型表现更稳健。
毒性之外,还有更多灰色地带
这项研究的最大价值,并不在于帮 4chan“洗白”,而是在于提醒 AI 社区:在训练早期“一刀切”地过滤敏感内容,可能会留下长期风险。
如果模型终究需要在现实世界中面对“毒性话题”——无论是仇恨言论、极端政治观,还是性别偏见——那么不如在早期就让它见识一些“真实世界”,再在后期训练中教它怎么处理。
研究者甚至提出:同样的思路,也许能推广到性别刻板印象、种族偏见、阴谋论等其它“高风险特征”。通过小剂量暴露+结构化处理+强力控制,让模型更有“免疫力”。
这就像疫苗——让身体见识病毒,才有抗体。
via https://the-decoder.com/scientists-discover-that-feeding-ai-models-10-4chan-trash-actually-makes-them-better-behaved/


