前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。

这件事一下引发了巨大反响,不仅是关于新一代国产芯片设计、大模型在国产芯片训练的话题,也顺势引发了大家对大模型量化策略的关注。
FP8,其全称为 8-bit floating point(8 位浮点数),是一种超低精度的数据表示格式,相较于 FP32(单精度)或 FP16(半精度)等传统浮点格式,FP8 可以在尽量保持数值稳定性和模型精度的前提下,进一步降低存储和计算开销(参见机器之心文章:用FP8训练大模型有多香?微软:比BF16快64%,省42%内存)。
在英伟达之外,微软、Meta、英特尔、AMD 等也都在研究 FP8 训练与推理,有成为业界「新黄金标准」的趋势。
如今,DeepSeek 采用非主流的 FP8 量化策略,隐隐展现出国产大模型与国产芯片芯片软硬结合的优化策略与英伟达的高兼容策略的不同发展路径。
UE8M0 FP8 具有鲜明的战略意义。DeepSeek 选择在模型端率先采用并公开声明使用 UE8M0 格式,将其训练与 scale 策略与该精度绑定。这等于由大模型端主动提出标准,迫使硬件和工具链进行适配,加速了国产软硬件一体化的生态建设。
不知道是不是巧合,在 DeepSeek 为国产芯片准备的 FP8 量化策略的提出不久,就在今天,英伟达也在低精度量化领域再次发力。只不过这次不是 FP8 量化的新进展,而是向 FP4 量化跃进。
英伟达将其最新的 NVFP4 策略拓展到预训练阶段,声称能够以匹配 16 位的精度进行训练,并以 4 位的速度和效率运行。

英伟达称:「在预训练中使用 NVFP4,可显著提升大规模 LLM 训练效率和基础设施效能。这不仅是一次渐进式优化,而是一种重新定义大规模模型训练方式的根本性转变。」
在「AI 工厂」时代,算力是进步的引擎,数值精度已不再是后端细节,而是一种战略优势。NVFP4 4 比特预训练为效率与可扩展性设定了新的标准,推动高性能 AI 模型开发进入全新阶段。
目前,NVFP4 训练仍处于研究阶段,正在探索并验证 4 位精度在大规模模型预训练中的潜力。围绕 NVFP4 的合作与实验正积极推进,参与方包括 AWS、Cohere、Google Cloud、Kimi AI、Microsoft AI、Mistral、OpenAI、Perplexity、Reflection、Runway 等领先组织。
对于英伟达在更低位的探索,评论区的网友意见不一,有人认可 NVFP4 在提升训练速度以及降低成本和能耗方面的积极作用,认为其有望推动更多行业进入高效、可持续的 AI 时代。

还有人提到 NVFP4 与 Jetson Thor 的结合有望对现实世界的应用产生深远影响。Jetson Thor 是英伟达前几日发布的新一代机器人专用芯片,通过大幅提升算力,可以适配具身智能新算法,支持人形机器人等各种形态。
二者可能的结合,一方面在训练端带来更高的能效与速度优化,另一方面在边缘、推理场景充分利用高性能低功耗的计算能力,最终从训练到部署形成高效的完整闭环。
不过也有人不买账,针对英伟达声称的更环保(greener),他认为,虽然新的数据格式带来了种种优化,但并不代表 AI 的总体算力需求和能耗会因此减少,也无法从根本上改变 AI 持续扩张造成的能源与资源压力。
什么是 4 比特量化(4-bit quantization)?
4 比特量化指的是将模型中的权重和激活值的精度降低到仅仅 4 位。这相比常见的 16 位或 32 位浮点数格式,是一次大幅度的精度压缩。
在预训练阶段使用 4 比特量化非常具有挑战性。因为需要在保持训练速度提升的同时,谨慎地处理梯度和参数更新,以确保模型精度不会丢失。
为了达到这个目标,英伟达必须使用专门的技术和方法,把原本高精度的张量(tensor)映射到更小的量化值集合中,同时仍然维持模型的有效性。
更少的比特如何释放 AI 工厂的更大潜能
近些年来,AI 的工作负载呈现爆炸式增长 —— 不仅仅是在大语言模型(LLM, Large Language Model)的推理部署中,还包括基础模型(foundation model)在预训练和后训练阶段的规模扩张。
随着越来越多机构扩展计算基础设施,用来训练和部署拥有数十亿参数的模型,一个核心指标逐渐凸显:AI 工厂能维持多高的 token 吞吐量,从而解锁下一阶段的模型能力。
在推理(inference)环节,精度格式已经经历了多次革新:从最初的 FP32(32 位浮点数)到 FP16,再到 FP8,最近甚至发展到 NVIDIA 发布的 NVFP4,用于 AI 推理。实践表明,像后训练量化(PTQ)这样的方法,已经能够借助 NVFP4 显著提升推理吞吐量,同时保持准确性。
然而,在更上游的预训练阶段,挑战依然存在 —— 目前大多数基础模型仍依赖于 BF16 或 FP8 来维持稳定性和收敛性。
预训练恰恰是 AI 工厂消耗最多计算力、能耗和时间的环节。算力预算有限,GPU 时钟周期稀缺,开发者必须精打细算 —— 从每一个比特、每一个 token,到每一个训练周期都要计算在内。吞吐量在这里不只是一个抽象指标,它直接决定了:能够训练多大规模的模型,可以运行多少实验,又能多快迎来新的突破。
这就是 4 位精度真正具备颠覆性意义的地方。
通过减少内存需求、提升算术运算吞吐量、优化通信效率,4 比特预训练能够让 AI 工厂在相同的硬件条件下处理更多的 token。只要配合合适的量化方法,它的精度表现可以与 FP8 或 BF16 相当,同时还能显著提升吞吐量。
这意味着:
模型收敛速度更快;
单位算力能运行更多实验;
可以训练出前所未有规模的前沿模型。
换句话说,更少的比特不仅仅是节省成本,它还拓展了 AI 工厂的能力边界。
NVFP4 预训练量化方案
为了实现 4 位精度的预训练,英伟达开发了一套专门的 NVFP4 预训练方案,解决了大规模训练中动态范围、梯度波动以及数值稳定性的核心挑战。
Blackwell 是 NVIDIA 首个原生支持 FP4 格式的架构。GB200 和 GB300 上巨大的 FP4 FLOPs 吞吐量,通过加速低精度矩阵运算,同时保持大模型收敛所需的规模和并行性,从而实现高效的 4 比特训练 —— 使其成为下一代基于 FP4 的 AI 工厂进行预训练的理想选择。
下图 1 显示了 Blackwell Ultra 的 GEMM 性能测量结果,相比 Hopper 代实现了 7 倍加速。现代大语言模型(LLM)在本质上依赖矩阵乘法,尤其是在其全连接层或线性层中,矩阵乘法是核心计算元素。因此,这些运算的效率至关重要。
FP4 精度能够更快、更高效地执行这些运算,所观察到的 GEMM 加速意味着整个预训练过程都显著加快,从而缩短训练时间,并支持更大规模模型的快速开发。
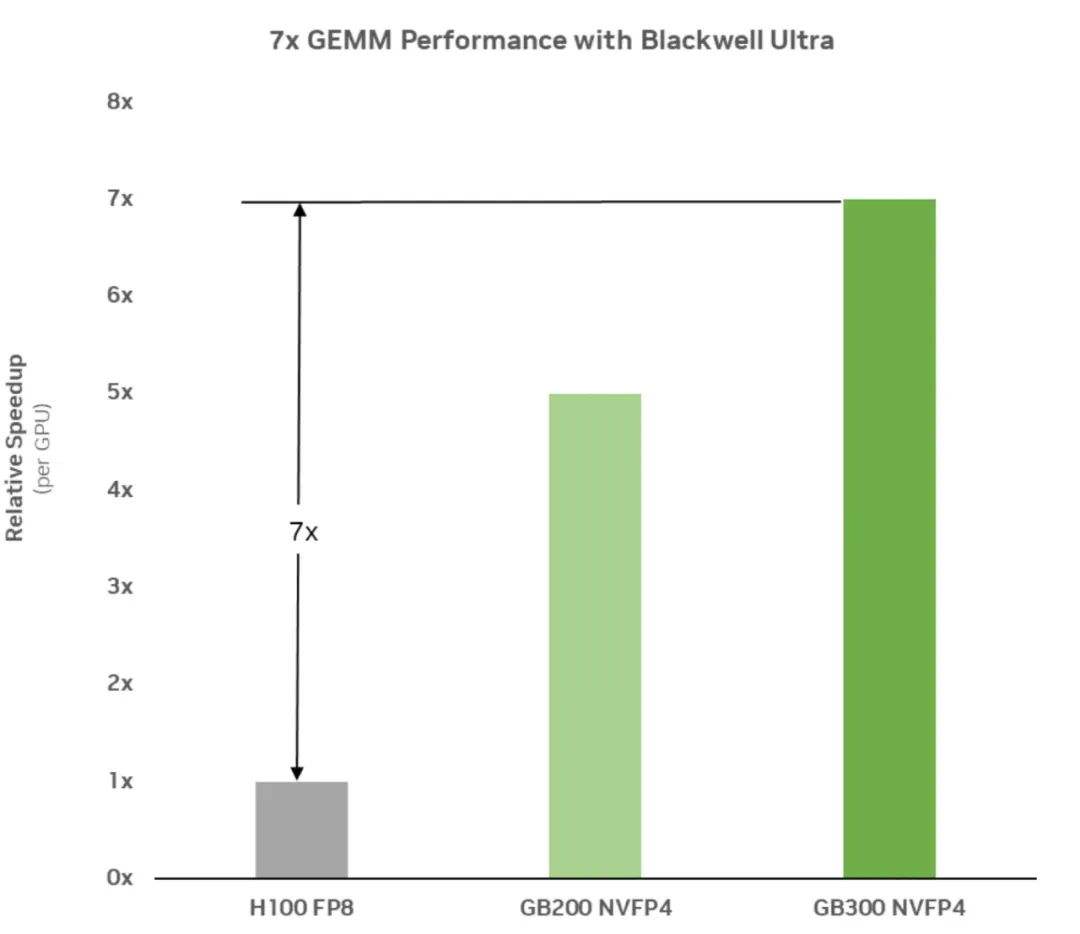
图 1:测得的 GEMM 性能显示,GB300 相比 Hopper 实现了 7 倍加速,通过更快的 FP4 优化矩阵乘法加速了核心 LLM 训练操作。
为了实现高效的低精度训练,NVIDIA 的 NVFP4 预训练方案采用了多项关键技术,这些技术是基于性能和精度精心选择的,包括:
1. 利用 NVFP4 的微块缩放增强数值表示
Blackwell 引入了对 NVFP4 的原生 Tensor Core 支持。NVFP4 是一种 4 位数值格式,可用于权重和激活值,采用微块缩放技术 —— 每 16 个 4 位元素共享一个公共缩放因子。相比 MXFP4 将块大小设为 32 元素,NVFP4 将块大小缩小至 16 元素,从而减少异常值的影响,实现更精确的缩放。更细粒度的缩放降低了量化误差,提升了模型整体精度。
2. 使用 E4M3 缩放因子的 NVFP4 高精度块编码
缩放因子精度在量化质量和精度中至关重要。不同于仅限于 2 的幂(E8M0)且易产生高舍入误差的 MXFP4,NVFP4 使用带额外尾数位的高精度 E4M3 缩放因子。这允许更细粒度的缩放,更有效利用有限的量化区间,并在块内更准确地表示数值。
3. 重塑张量分布以适应低精度格式
LLM 预训练期间的梯度和激活值通常存在大幅异常值,这会影响低精度量化。对 GEMM 输入应用 Hadamard 变换,可将其分布重塑为更接近高斯分布,从而平滑异常值,使张量更容易被精确表示。这些变换对模型结构是透明的,可在前向和反向传播的线性层中应用。
4. 使用量化技术保持数据一致性
为了确保训练稳定高效,英伟达采用保持前向和反向传播一致性的量化方法。诸如选择性二维块量化等技术,有助于在整个训练周期中保持张量表示的对齐。这种一致性对于最小化信号失真、改善收敛行为、增强整体鲁棒性至关重要,尤其是在 NVFP4 等低精度格式下。
5. 通过随机舍入减少偏差
与传统(确定性)舍入总是向最接近的可表示值舍入不同,随机舍入会根据数值在两个可表示值之间的位置,按概率向上或向下舍入。这一步骤对于减少舍入偏差、保持训练期间梯度流动以及最终提高模型精度至关重要。

图 2:英伟达的 NVFP4 预训练技术,用以实现高效低精度训练。
万亿级 Token 规模下的精度与稳定性
要让低精度格式在大规模预训练中实用,必须同时保证模型精度和收敛稳定性。
为了评估 4 位精度在大规模模型训练中的可行性,英伟达在一个 120 亿参数的混合 Mamba-Transformer 架构模型(12B Hybrid Mamba-Transformer)上进行了 FP8 和 NVFP4 的实验。
该模型类似于 NVIDIA Nemotron Nano 2,它在包含 10 万亿个 token 的超大数据集上进行训练,采用分阶段数据混合策略:在训练的 70% 阶段切换到不同的数据集混合,在预训练的 90% 阶段进行第三阶段数据切换。
该 12B Hybrid Mamba-Transformer 模型的一个版本最初使用 8 精度(FP8)进行训练。之前的研究表明,FP8 的精度与 16 位精度非常接近,因此 FP8 被作为英伟达的基线进行对比。
随后,英伟达成功地从零开始使用 NVFP4 训练同样的 12B 模型,证明这种新的低精度格式可以支持万亿级 Token 规模的完整预训练。并且,NVFP4 在训练过程中表现出稳定的收敛性,没有通常困扰超低精度训练的不稳定性或发散问题。
下图 3 显示,NVFP4 的验证损失曲线在整个训练过程中与高精度基线(即 FP8)的损失曲线高度一致。上述量化技术确保即使在大幅降低位宽的情况下,4 比特预训练的动态表现仍与高精度训练非常接近。
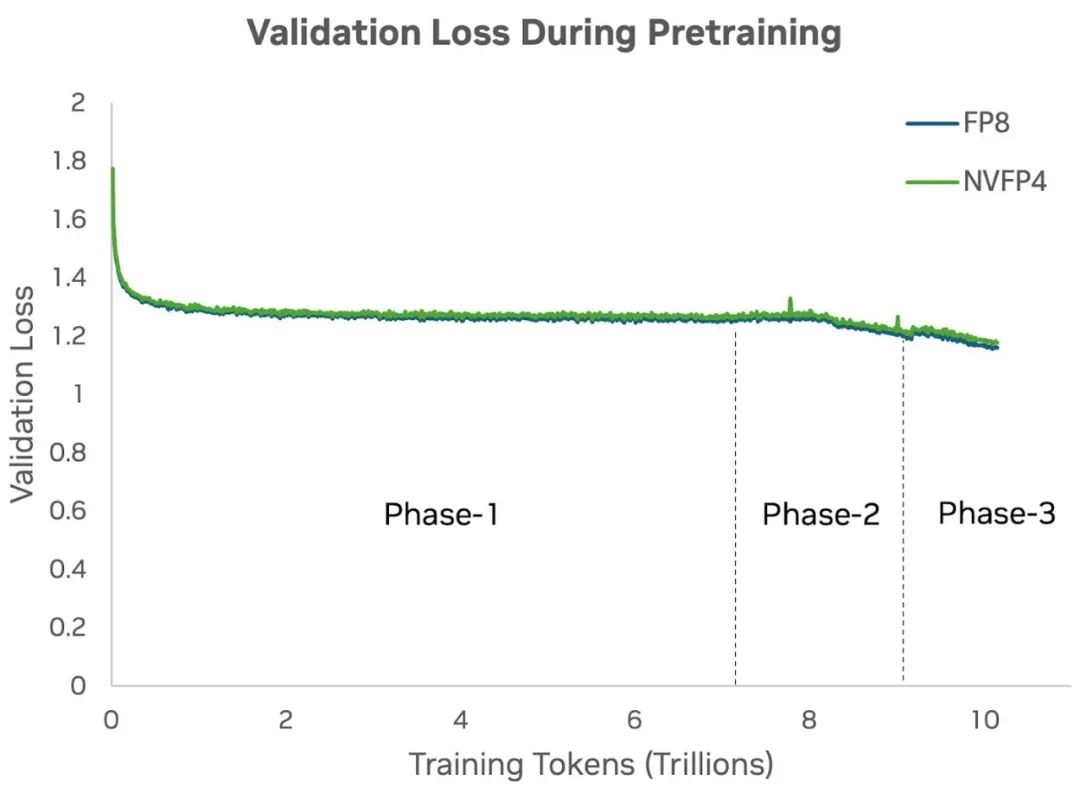
图 3:在对 120 亿参数的 Hybrid Mamba-Transformer 模型进行预训练时,对比使用 FP8 与 NVFP4 精度在 10 万亿 tokens 下的验证损失结果显示,NVFP4 的损失曲线在整个训练过程中与 FP8(基线)的曲线高度吻合。
随后,英伟达使用 NVFP4 预训练 120 亿参数的 Hybrid Mamba-Transformer 模型,并与更高精度的 FP8 基线在多个下游任务与智能领域进行了对比。
如下图 4 所示,在所有领域中,NVFP4 的准确率表现均与 FP8 相当,甚至在代码领域实现了反超,展现了其有效性。该结果进一步强化了最初的假设:即使在万亿 token 规模下,NVFP4 依然是大语言模型预训练的稳健选择,验证了其在高效大规模前沿模型训练中的潜力。
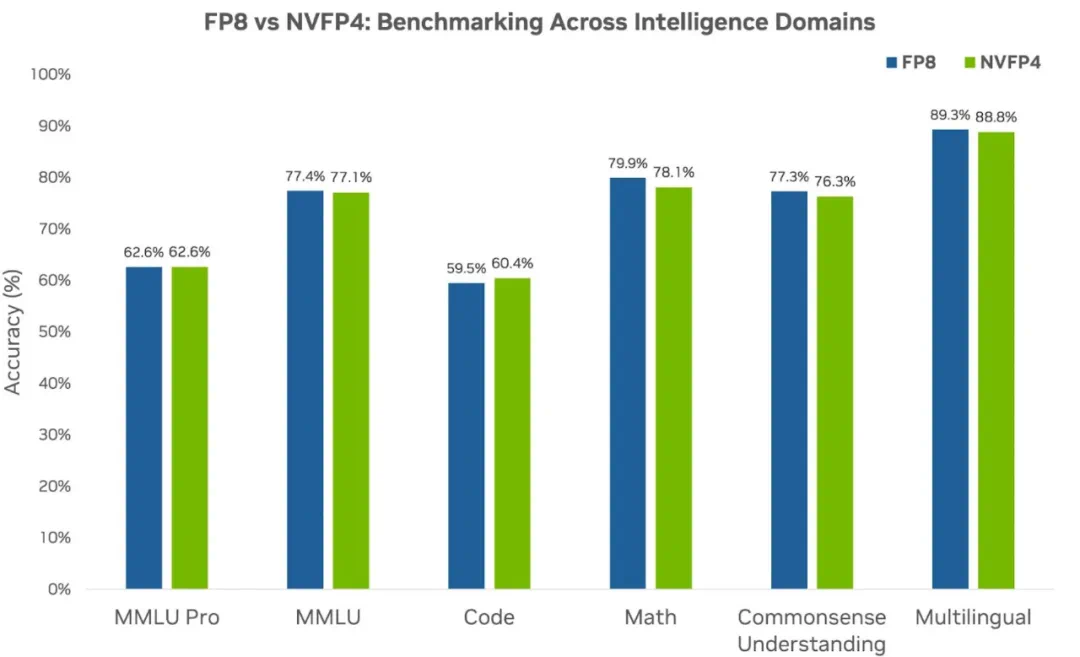
图 4:分别使用 FP8 精度(基线)和 NVFP4 精度,对 120 亿参数的 Hybrid Mamba-Transformer 模型进行预训练,此时的下游任务准确率对比。
聪明训练,而不是一味加码
根据英伟达的说法,NVFP4 格式正在重新定义 AI 训练的格局,并可以为实现速度、效率和有目的创新设立新的标杆。通过实现 4 比特预训练,NVFP4 让 AI 工厂更快、更可持续地扩展,为全新的生成式 AI 时代打下基础。
另外,作为一种动态且不断演进的技术,NVFP4 将持续为前沿模型团队创造新的机遇,推动节能高效和高性能的 AI 发展。凭借计算效率的突破,4 比特预训练将赋能更先进的架构、更大规模的训练和 token 处理,从而为未来的智能系统注入新的动力。
原文地址:https://developer.nvidia.com/blog/nvfp4-trains-with-precision-of-16-bit-and-speed-and-efficiency-of-4-bit/


