
在大模型技术飞速发展的今天,通用大模型在日常对话、内容创作等场景中已展现出卓越能力,但当面对医学、科学、计算机等专业领域时,却常常“力不从心”。分布偏移导致模型认知与领域数据脱节,高质量领域数据稀缺推高训练成本,传统RAG技术又难以精准捕捉领域信息——这些痛点成为大模型落地专业场景的关键阻碍。
而Amazon在2025年NAACL会议上发表的SimRAG(Self-Improving Retrieval-Augmented Generation) 框架,为解决这些问题提供了全新思路。它通过“自我改进”机制,让大模型无需依赖大规模标注领域数据,就能自主提升专业领域的检索增强问答能力,为大模型适配垂直领域开辟了高效路径。
论文地址:https://arxiv.org/pdf/2410.17952
01、为什么需要SimRAG?大模型适配专业领域的三大痛点
通用大模型在专业领域的“水土不服”,本质上源于三个核心矛盾,这也是SimRAG诞生的核心动机:
分布偏移:通用模型与专业领域的“认知鸿沟”
通用大模型的训练数据覆盖广泛但缺乏领域深度,当面对医学文献中的专业术语(如“免疫检查点抑制剂”)、计算机科学中的技术概念(如“分布式一致性算法”)时,模型难以理解领域特有的数据分布规律,导致回答准确性大幅下降。例如,通用模型可能将“肿瘤靶向治疗”与“常规化疗”混淆,而这类错误在专业场景中可能产生严重后果。
数据稀缺:专业领域的“标注困境”
高质量的专业领域问答数据(如医学问诊案例、科学实验问答)不仅获取成本极高(需领域专家参与标注),还可能涉及隐私问题(如患者病历数据)。以医学领域为例,一份符合训练标准的“病症-诊断-治疗”问答样本,可能需要医生花费数小时整理,且受限于隐私法规难以大规模公开,这让传统的监督训练方法举步维艰。
传统RAG的局限:“检索-生成”难以适配专业场景
尽管RAG技术通过“检索外部知识+生成答案”的模式缓解了大模型的知识滞后问题,但现有RAG系统多针对通用领域设计:一方面,检索器难以精准识别专业文档中的关键信息(如科研论文中的实验结论);另一方面,生成器无法将检索到的领域知识与问题深度融合,常出现“答非所问”或“知识堆砌”的情况。
02、SimRAG的核心思路:两阶段微调,让模型“自己教自己”
SimRAG的核心创新在于“自训练+两阶段微调” :先让模型在通用领域掌握“检索-问答”的基础能力,再利用专业领域的未标注语料,让模型自主生成高质量伪标注数据,实现“自我改进”。其整体框架如下图所示:
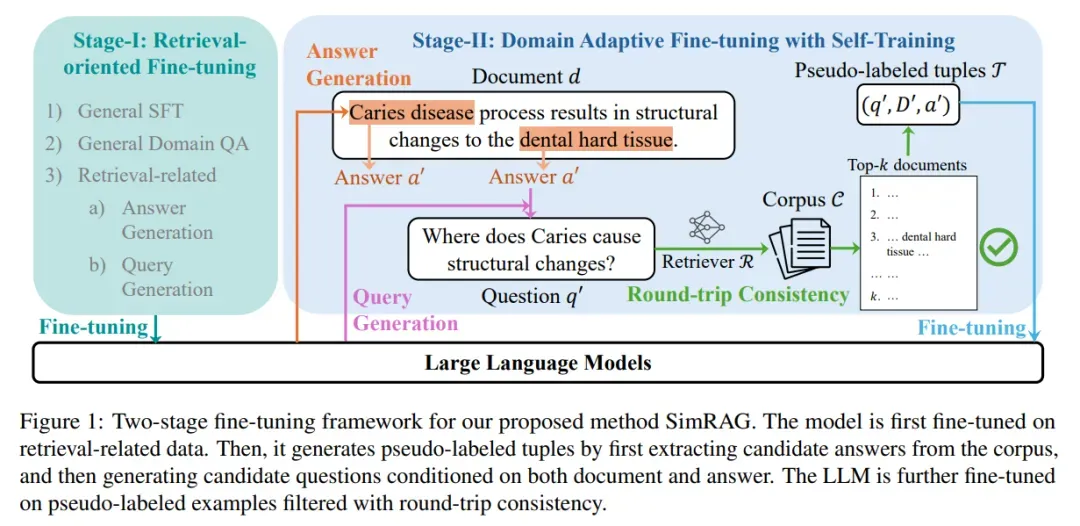
简单来说,SimRAG的工作流程可以拆解为“基础能力培养”和“领域能力进化”两个阶段:
阶段一:面向检索的基础微调——让模型学会“用检索答问题”
第一阶段的目标是为模型打下“检索增强问答”的基础,避免后续领域微调时丢失通用能力。训练数据主要分为三类,覆盖“指令理解”“上下文问答”“检索相关任务”三大核心能力:
训练数据类型 | 具体数据集 | 训练目标 |
通用指令微调数据 | OpenAssistant、Dolly、SODA等 | 保持模型对指令的理解和遵循能力,避免“忘本” |
通用领域上下文QA数据 | SQuAD、NQ、DROP等13个数据集 | 让模型学会从给定上下文(如文档片段)中提取信息生成答案 |
检索相关任务数据 | 答案生成(SQuAD、WebQuestions)、问题生成(NQ、StrategyQA) | 培养模型“从文档抽答案”“从答案造问题”的能力,为后续伪数据生成铺垫 |
在训练过程中,模型仅对“答案部分”计算损失,确保优化目标聚焦于“生成准确回答”,而非冗余的指令或上下文表述。
阶段二:领域自适应微调——让模型“自己造数据练本事”
经过第一阶段的模型已具备基础的检索问答能力,但面对专业领域仍需“针对性进化”。SimRAG的关键创新就在于此阶段:无需人工标注,让模型利用专业领域的未标注语料,自主生成高质量伪标注QA对,具体步骤可概括为“生成-过滤-微调”三步:
1. 伪标注数据生成:从“无标注文档”到“高质量QA对”
SimRAG通过两次生成,将专业文档转化为可用的训练数据:
- 第一步:生成候选答案:对于专业语料库中的每篇文档(如医学论文、计算机教材),模型自动提取可能作为答案的片段(如“阿司匹林的主要副作用是胃肠道刺激”)。
- 第二步:生成对应问题:基于“文档+候选答案”,模型反向生成问题(如“阿司匹林的主要副作用是什么?”),形成初步的“问题-文档-答案”QA对。
为了避免模型“思维固化”,SimRAG还会生成多样化的QA类型,覆盖专业领域常见的问答形式:
- 短答案QA:如“Transformer的编码器有多少层?”(答案:6层)
- 多项选择QA:如“以下哪种药物属于抗生素?A.阿司匹林 B.青霉素 C.布洛芬”(答案:B)
- 声明验证:如“‘新冠病毒通过飞沫传播’这一说法是否正确?”(答案:正确,支持文档:XXX)
2. 往返一致性过滤——给伪数据“质量把关”
生成的伪数据可能存在“问题与答案不匹配”“答案与文档无关”等问题,SimRAG引入“往返一致性过滤”机制筛选高质量样本:
- 用生成的“问题”去检索专业语料库,得到前k篇相关文档;
- 若原始“候选答案”能在检索到的文档中找到(即“问题能检索回含答案的文档”),则保留该QA对;反之则丢弃。
这一过滤步骤相当于让“检索器”当“质检员”,确保留下的伪数据符合“检索增强”的逻辑,避免低质量数据污染训练。
3. 领域微调:用伪数据提升专业能力
将筛选后的高质量伪数据,与第一阶段的通用训练数据混合,对模型进行二次微调。此时模型的优化目标已从“通用问答”转向“专业领域问答”,逐步适应专业数据的分布规律。
03、实验验证:SimRAG在三大专业领域“全面碾压基线”
为了验证SimRAG的有效性,Amazon团队在医学、科学、计算机科学三大领域的11个数据集上进行了测试,对比了通用大模型、专业领域大模型、传统RAG模型等多类基线。
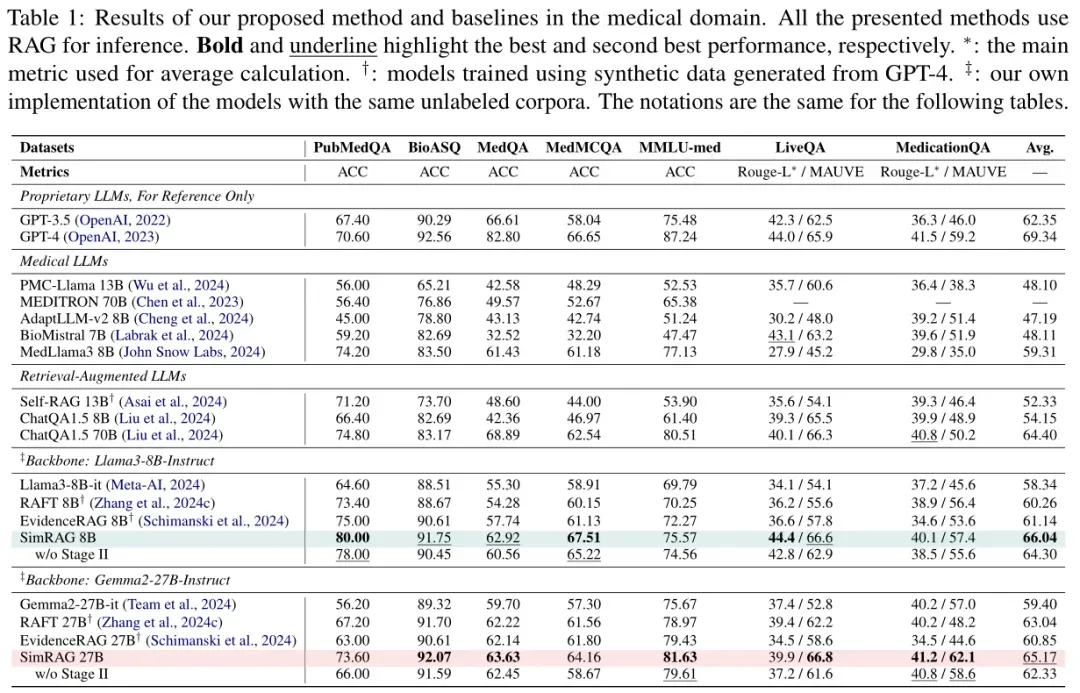
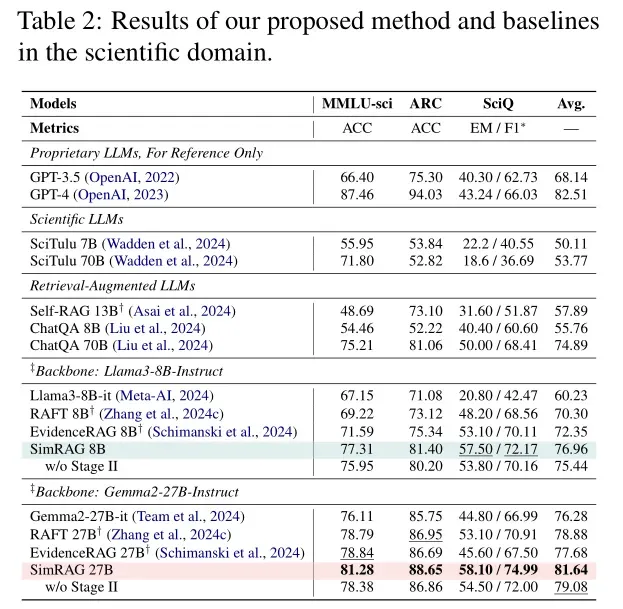
结果显示,SimRAG在三大领域均显著优于基线模型,核心原因可归结为两点:
比“专业领域模型”更懂“检索”
MedLlama、SciTulu等专业模型虽在领域数据上微调,但未针对“检索增强”优化——它们难以有效利用检索到的专业文档,常出现“凭记忆答题”而非“依文档答题”的情况。例如在PubMedQA任务中,MedLlama的准确率为78.2%,而SimRAG达到85.6%,差距主要源于“是否能利用检索到的医学文献修正记忆偏差”。
比“传统RAG模型”更懂“领域”
Self-RAG、RAFT等传统RAG模型虽具备检索能力,但未针对专业领域优化:一方面,检索器难以精准定位专业文档中的关键信息;另一方面,生成器无法理解领域术语的深层含义。例如在CS-Bench任务中,RAFT的平均准确率为62.3%,而SimRAG达到70.1%,优势在于“能生成更贴合计算机领域的伪数据,适配领域知识分布”。
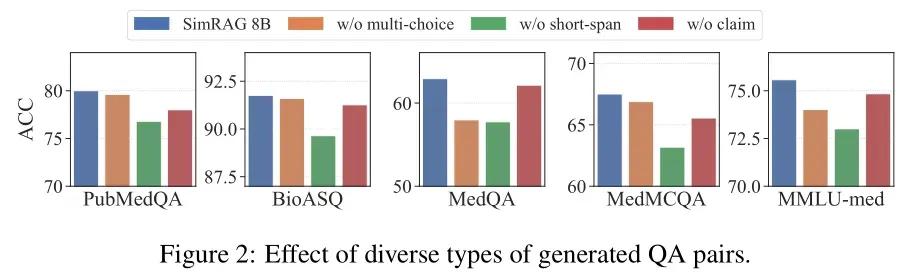
消融实验:验证关键模块的必要性
为了明确SimRAG各模块的作用,团队还进行了消融实验,结果进一步验证了核心设计的价值:
- 两阶段训练的必要性:由表1-3可以观察到,仅进行阶段一训练的模型,在专业领域的准确率比完整SimRAG低4.8%;仅进行阶段二训练的模型,因缺乏基础检索能力,准确率低6.2%。
- 数据过滤的价值:未经过滤的伪数据会导致模型准确率下降2.1%,且训练收敛速度变慢——证明“往返一致性过滤”有效剔除了低质量数据。
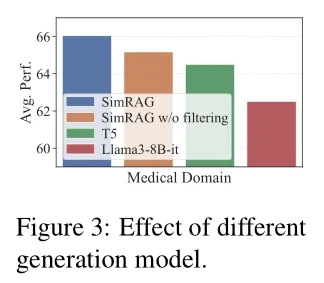
- 多样化问题的优势:仅生成单一类型QA对的模型,在跨任务泛化能力上比SimRAG低3.5%,说明多样化问题能帮助模型适应不同场景。
04、总结:SimRAG的价值与启示
SimRAG为大语言模型(LLM)适配专业领域提供了一种“低成本、高效率”的创新方案。它无需依赖大规模人工标注的专业数据,通过“自我生成伪数据+两阶段微调”,使通用大模型自主进化为专业领域的检索增强问答专家。
论文启示
- 降低专业领域大模型落地成本:无需投入大量资金聘请领域专家标注数据,仅需准备专业语料库,模型即可自主学习,显著降低了专业领域大模型的落地成本。
- 为小模型赋能:实验中基于Llama3-8B(80亿参数)的SimRAG,性能超过了Gemma2-27B(270亿参数)的传统RAG模型,证明“高效训练方法”比“单纯堆参数”更具性价比。
落地适用性局限
然而,结合现实RAG应用的实际需求与企业数据特点,SimRAG的落地适用性仍存在两方面显著局限:
- 与现实RAG应用“轻量化调用”需求相悖在当前主流的现实RAG应用中,“低门槛、高适配”是核心需求。多数企业或开发者倾向于直接调用成熟的闭源LLM(如GPT-4、文心一言)或已部署完成的大参数开源LLM(如Llama3-70B、Qwen-72B),通过搭建检索器(如Milvus、FAISS)、设计prompt工程等“非微调”方式实现知识增强,无需对LLM本身进行参数调整。这种模式的核心优势在于降低技术门槛与资源成本:一方面,闭源LLM的API调用无需关注模型训练细节,开源大模型的部署也多有成熟工具链支持,开发者可快速搭建RAG系统;另一方面,避免了微调所需的大规模计算资源(如多卡GPU集群)、专业算法人员投入,以及微调过程中可能出现的模型“灾难性遗忘”风险。而SimRAG的核心逻辑依赖“两阶段LLM微调”——不仅需要在通用领域数据上完成基础微调,还需基于领域伪标注数据进行二次微调。这种模式与现实RAG应用的“轻量化调用”需求相悖:对于缺乏大规模算力、算法团队的中小企业而言,微调LLM的技术成本与资源成本过高;对于依赖闭源LLM API的场景,微调更是无法实现,直接导致SimRAG在这类主流现实应用中适用性大幅降低。
- 难以应对企业数据低质量问题SimRAG的领域自适应能力高度依赖“高质量领域语料”——其第二阶段的伪标注数据生成、自我改进过程,均以“领域语料能提供有效知识”为前提。但在企业实际场景中,数据质量普遍偏低,难以满足SimRAG自主学习的基础要求,主要体现在以下三方面:
- 数据噪声多:企业数据常包含大量冗余信息(如重复文档、无关备注)、错误信息(如录入错误的产品参数、过时的业务流程)。模型基于这类数据生成伪标注时,易产生“问题与答案不匹配”“答案偏离事实”的低质量QA对,即便经过“往返一致性过滤”,也难以完全剔除噪声,反而可能因过滤机制误判优质数据,进一步影响训练效果。
- 数据结构化程度低:企业数据多以非结构化形式存在(如扫描件、语音转文字记录、非正式会议纪要),缺乏清晰的知识逻辑与关键信息标注。SimRAG的伪标注生成依赖“从文档中提取候选答案”,而低结构化数据中关键信息(如产品性能指标、客户需求痛点)难以被模型准确识别,导致生成的候选答案质量差,后续的问题生成与微调自然无法有效推进。
- 数据领域相关性弱:部分企业数据虽名义上属于“领域数据”,但实际包含大量通用内容(如行业通用新闻、基础操作指南),缺乏领域深度知识(如企业核心技术参数、专属业务流程)。模型基于这类数据自主学习时,无法接触到真正有价值的领域知识,微调后仍难以适配企业核心业务场景的问答需求,失去“领域自适应”的核心意义。


