DeepSeek

千万元年薪+DeepSeek核心加盟,小米AI大模型“踩油门”:卢伟冰称“效果已超预期”
12月5日,小米集团合伙人、总裁卢伟冰在社交媒体透露:公司AI大模型业务过去四个季度投入环比增速超50%,目前进展“已超出董事会预期”,并宣布将AI与“现实世界深度结合”列为未来十年核心战略。 同时,小米正式启动全球人才招募计划,单岗位薪酬上限开至千万元级别,目标“在最短时间内补齐大模型尖端人才缺口”。
12/5/2025 11:26:13 AM
AI在线

网易有道词典2025年度词汇揭晓——“DeepSeek”全年867万次搜索量登顶
网易有道词典今天发布2025年度热词,“DeepSeek”以全年867万次搜索量登顶,成为该平台历史上首位源自国产AI大模型的年度词汇。 搜索曲线显示,用户关注度在1月尚处低位,2月后随DeepSeek-R1推理模型发布迅速飙升,年内多次技术突破均带动新一轮查询高峰。 大学生和职场人群构成主要增量,查词后进一步浏览“大模型”“AI能力”等相关词条的比例显著提高,形成“查词—学概念—用模型”的完整学习链路。
12/2/2025 12:21:11 PM
AI在线

deepseek当选网易有道词典2025年度词汇,全年搜索量超867万次
12月1日,国内权威在线词典平台“网易有道词典”正式揭晓2025年度词汇——“deepseek”。 这个单词,以全年超过8,672,940次的搜索量强势登顶,成为无数用户在查词框里敲下的共同答案。 图源:有道词典微博.
12/1/2025 5:22:48 PM
一水

DeepSeek的新模型,让AI第一次学会了反思
前两天有一个有趣的事,真的太魔幻了,感觉剧本都不会写的这么巧。 就在前几天,DeepSeek 悄悄地上了一个新模型,DeepSeekMath-V2。 更多新模型动态:一个基于 DeepSeek-V3.2-Exp-Base 构建的 685B 的数学专用模型。
12/1/2025 12:12:47 AM
数字生命卡兹克
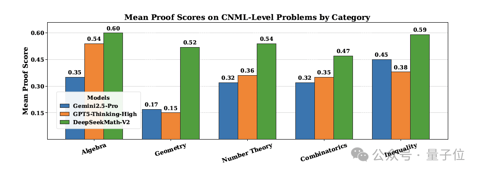
DeepSeek再破谷歌OpenAI垄断:开源IMO数学金牌大模型
henry 发自 凹非寺. 量子位 | 公众号AI界掌管开源的神——DeepSeek回来了! 刚刚,DeepSeek开源了全新的数学模型DeepSeekMath-V2,专注于可自验证的数学推理。
11/28/2025 12:43:20 PM
henry

中国已成为全球开源 AI 大模型的最大提供者
在北京举行的2025开放原子开发者大会上,中国工程院院士倪光南强调,中国已成为全球开源人工智能大模型的最大提供者,特别是如 Qwen、DeepSeek 和 Kimi 等模型在国际评估中表现突出。 他指出,开源技术正成为推动全球信息技术发展的重要力量,尤其是在快速发展的 AI 领域。 倪光南表示,开源的趋势顺应了时代的发展需求,体现了全球信息技术领域的创新活力。
11/21/2025 4:26:50 PM
AI在线

DeepSeek 高级研究员警告:人工智能十年内恐取代大部分人类工作
在中国世界互联网大会(WIC)乌镇峰会上,中国人工智能初创公司 DeepSeek 的高级研究员陈德利罕见地公开露面,发表了针对人工智能社会影响的严峻警告,敦促科技公司承担起**“人类守护者”**的角色。 陈德利的言论凸显了中国科技界对人工智能可能带来的社会颠覆日益增长的担忧。 陈德利在小组讨论中表示,人工智能目前正处于提高生产力但仍需要人类监督的**“蜜月期”。
11/12/2025 10:46:11 AM
AI在线

重磅消息回顾!2025年10月值得关注的10条AI资讯
上期回顾:一、DeepSeek R1研究论文登上Nature封面. 9月17日,属于中国人工智能的又一个高光时刻来到了:DeepSeek-AI团队梁文锋及其同事在《自然》杂志发表了关于开源模型 DeepSeek-R1的研究成果,并登上当期封面。 根据研究团队在论文补充材料披露的细节,DeepSeek-R1的推理成本仅为29.4万美元,低到惊人。
10/31/2025 12:41:46 AM
百度MEUX 团队

DeepSeek-OCR:用视觉模态给长文本“瘦身”,大模型处理效率再突破
在大语言模型(LLMs)不断拓展能力边界的今天,长文本处理始终是道绕不开的坎——文本序列每增加一倍,计算量就可能翻四倍,像处理一本几十万字的书籍、一份上千页的金融报告时,内存溢出、推理卡顿成了常态。 但DeepSeek团队最近开源的DeepSeek-OCR模型,给出了一个全新解法:把文本“画”成图像,用视觉Token实现高效压缩。 原本需要1000个文本Token存储的内容,现在100个视觉Token就能搞定,还能保持97%的OCR精度。
10/30/2025 7:00:00 AM
Goldma

DeepSeek-OCR:OCR 的新突破
DeepSeek 近日发布了DeepSeek-OCR。 这不仅仅是一个 OCR 模型,而是一个概念验证,它可能会从根本上改变我们在大型语言模型中对上下文的理解。 这个想法是这样的:如果不是向 LLM 输入数千个文本标记,而是将该文本压缩成图像,并用 100 个视觉标记来表示它,而不会损失准确性,那会怎样?
10/29/2025 4:42:06 PM
晓晓

AI大模型专栏正式开撸:DeepSeek本地部署+避坑指南
本文旨在提供一个全面且详细的DeepSeek本地部署指南,帮助大家在自己的设备上成功运行DeepSeek模型。 无论你是AI领域的初学者还是经验丰富的开发者,都能通过本文的指导,轻松完成DeepSeek的本地部署。 一、本地部署的适用场景DeepSeek本地部署适合以下场景:高性能硬件配置:如果你的电脑配置较高,特别是拥有独立显卡和足够的存储空间,那么本地部署将能充分利用这些硬件资源。
10/28/2025 2:00:00 AM
冰河

DeepSeek最会讨好,LLM太懂人情世故了,超人类50%
用过大模型的都知道,它们多多少少存在一些迎合人类的行为,但万万没想到,AI 模型的迎合性比人类高出 50%。 在一篇论文中,研究人员测试了 11 种 LLM 如何回应超过 11500 条寻求建议的查询,其中许多查询描述了不当行为或伤害。 结果发现 LLM 附和用户行为的频率比人类高出 50%,即便用户的提问涉及操纵、欺骗或其他人际伤害等情境,模型仍倾向于给予肯定回应。
10/27/2025 2:29:00 PM
机器之心

最强OCR竟然不是DeepSeek、Paddle!HuggingFace新作:六大顶尖开源OCR模型横评!继DS后又杀出匹黑马!
编辑 | 听雨在AI快速进化的浪潮中,文字和图像的界限正在被重新定义。 那些能“看懂”文件、理解图表、读出语义的视觉语言模型(VLM),正在让传统OCR(光学字符识别)进入一个全新的智能阶段。 如果你还以为OCR只是“识字”的工具,那你可能错过了它真正的革命性变化。
10/24/2025 4:42:09 PM
听雨

独立开源大佬的疯狂实验:Claude Code蛮力出奇迹!40 分钟跑通 DeepSeek-OCR,我一行代码都没写
编辑 | 听雨出品 | 51CTO技术栈(微信号:blog51cto)当 AI 不再只是“写代码”,而是开始自己装环境、跑模型、记笔记——那种感觉,像是它在学会独立思考。 最近,开源工具Datasette创建者、Django 框架联合创始人 Simon Willison 做了一个疯狂实验:他让 Claude Code 全权接管,把 DeepSeek-OCR 在 NVIDIA Spark 上跑了起来。 听起来像是“让 AI 去安装另一个 AI”,但结果却令人震惊——部署成功、过程全自动、连错误都能自我修复。
10/23/2025 4:19:29 PM
听雨

全新开源的DeepSeek-OCR,可能是最近最惊喜的模型!
AI圈虽然天天卷,但是很多的模型,真的越来越无聊了。 每天就是跑分又多了几个点。 直到昨天,DeepSeek久违的发了一个新模型。
10/22/2025 7:01:42 AM
数字生命卡兹克

DeepSeek的新模型很疯狂:整个AI圈都在研究视觉路线,Karpathy不装了
「我很喜欢新的 DeepSeek-OCR 论文…… 也许更合理的是,LLM 的所有输入都应该是图像。 即使碰巧有纯文本输入,你更应该先渲染它,然后再输入。 」一夜之间,大模型的范式仿佛被 DeepSeek 新推出的模型给打破了。
10/21/2025 12:07:00 PM
机器之心

DeepSeek新模型被硅谷夸疯了!用二维视觉压缩一维文字,单GPU能跑,“谷歌核心机密被开源”
DeepSeek最新开源的模型,已经被硅谷夸疯了! 因为实在太DeepSeek了。 3B规模、指数级效能变革、大道至简,甚至被认为把谷歌Gemini严防死守的商业机密开源了。
10/21/2025 8:03:21 AM

从重复抽卡到脑洞大开?一句话让AI更聪明!
只要你平时用多了AI,可能会发现一个问题? 比如你让AI帮优化个文章,它总是动不动就给你用上冒号(:)跟破折号(——),文字间还特别喜欢用成语,喜欢用自问自答,还喜欢用序号(1,2,3,4...),有时候套话还挺多,甚至有时候当你反复抽卡时结果却越来越相似。 明明是不同的,有时甚至是同一个模型换个会话,问同一个开放性问题,得到的答案却总是很相似。
10/21/2025 5:02:24 AM
彩云Sky
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
DeepSeek
谷歌
AI绘画
大模型
机器人
数据
AI新词
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
技术
智能体
马斯克
Gemini
Anthropic
英伟达
图像
AI创作
训练
LLM
论文
代码
算法
AI for Science
苹果
Agent
Claude
芯片
腾讯
Stable Diffusion
蛋白质
开发者
xAI
具身智能
生成式
神经网络
机器学习
3D
人形机器人
AI视频
RAG
大语言模型
研究
百度
Sora
生成
GPU
工具
华为
计算
字节跳动
AI设计
AGI
大型语言模型
搜索
生成式AI
视频生成
场景
DeepMind
特斯拉
深度学习
AI模型
架构
亚马逊
MCP
Transformer
编程
视觉
预测