
DeepSeek 近日发布了DeepSeek-OCR。这不仅仅是一个 OCR 模型,而是一个概念验证,它可能会从根本上改变我们在大型语言模型中对上下文的理解。
这个想法是这样的:如果不是向 LLM 输入数千个文本标记,而是将该文本压缩成图像,并用 100 个视觉标记来表示它,而不会损失准确性,那会怎样?
这正是 DeepSeek-OCR 所展现的。其潜力无限。
什么是 DeepSeek-OCR?
从本质上讲,DeepSeek-OCR 探索了一个有趣的假设:视觉模态能否作为文本信息的有效压缩媒介?
试想一下,一份文档的一页可能包含 1,000 个单词,大约有 1,300 个文本标记。但同样的页面,如果是一张图片呢?DeepSeek-OCR 只需 100 到 256 个视觉标记就能将其表示出来。
压缩率高达10 倍,准确率高达 97%。
即使压缩率达到 20 倍,该模型也能保持 60% 的准确率。虽然不算完美,但考虑到 token 的效率,这个成绩已经非常出色了。
使其发挥作用的架构
DeepSeek-OCR 由两个关键组件组成:
DeepEncoder(3.8亿个参数)——这是它的秘密武器。它是一款新颖的视觉编码器,结合了以下特点:
- 用于感知的 80M SAM 基础架构(以窗口注意力为主)
- 300M CLIP-large 用于知识(密集的全局注意力)
- 一个 16x 卷积压缩器将它们连接起来
这种巧妙的设计即使在高分辨率输入下也能保持较低的激活内存占用。一幅 1024×1024 的图像会被分割成 4,096 个块,但压缩器会将其压缩到仅 256 个标记,然后再进入代价高昂的全局注意力层。
DeepSeek-3B-MoE 解码器(570M 激活参数)——一种紧凑但功能强大的语言模型,可以从压缩的视觉标记中重建文本。
整个系统围绕一个原则进行设计:维持少量视觉标记、低激活内存和高压缩比。
按 Enter 键或单击即可查看完整尺寸的图像
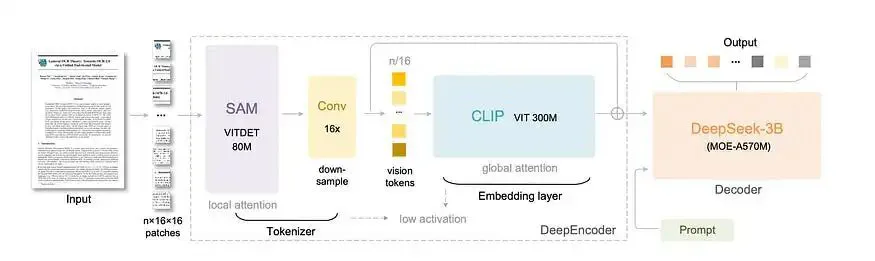
DeepSeek-OCR 架构。来源:官方文档
重要的数字
DeepSeek 在 Fox 基准测试中测试了他们的模型——真实文档包含 600-1300 个文本标记。结果清晰地说明了这一点:
按 Enter 键或单击即可查看完整尺寸的图像
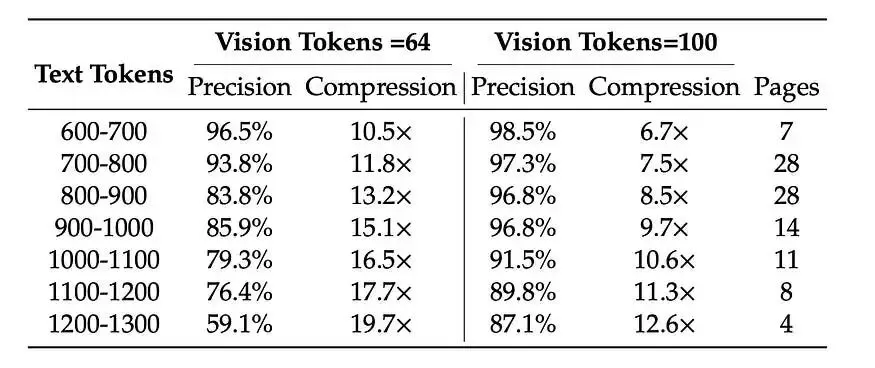
Fox Benchmark 上的 DeepSeek-OCR
最佳压缩点很明显:在 10 倍压缩下,该模型保持约 97% 的准确率。从实用角度来看,这基本上是无损压缩。
在 OmniDocBench(一个全面的文档解析基准测试)上,DeepSeek-OCR 的表现优于 GOT-OCR2.0(每页使用 256 个标记),而视觉标记数量仅为 100 个。它甚至击败了 MinerU2.0(每页需要 6,000 多个标记,而视觉标记数量不到 800 个)。
为什么这不仅仅与 OCR 有关
有趣的是,DeepSeek-OCR 并非试图成为世界上最好的 OCR 模型。它只是一个探索 AI 架构基本问题的研究工具。
其真正含义在于LLM 中的长上下文处理。
想象一下,在多轮对话中,超过特定点的对话历史记录会自动渲染为图像并压缩 10 倍。或者,代理系统通过将旧信息存储为压缩的视觉表示来维护庞大的上下文窗口。
DeepSeek 甚至提出了一种“遗忘机制”——逐步降低旧渲染图像的采样率,以进一步减少标记的消耗。近期内容在高分辨率下依然清晰可见。较旧的内容会变得更加模糊,消耗的标记也更少,这模仿了人类记忆自然消退的规律。
这就像在人工智能系统中实现生物记忆衰减曲线。
超越文档:隐藏的功能
虽然重点是文档 OCR,但由于训练数据组合,DeepSeek-OCR 还具有一些令人惊讶的附加功能:
OCR 2.0 任务:
- 图表解析(将图表转换为 HTML 表格)
- 化学式识别(SMILES格式)
- 平面几何解析
- 数学方程式识别
总体愿景:
- 图像字幕
- 物体检测
- 视觉接地
- 基本 VQA 任务
多种语言:
- 支持近100种语言
- 布局感知和无布局 OCR 模式
该模型并非通用的 VLM——它由 70% 的 OCR 数据、20% 的通用视觉数据和 10% 的纯文本数据组成。但这是有意为之。它针对压缩研究问题进行了优化。
示例 1:图表解析(将图表转换为 HTML 表格)
实际应用
这在实践中有什么重要意义?
- LLM 训练:将 3000 万页 PDF 文档转换为工业级训练数据。该模型可处理约 100 种语言,非常适合多语言预训练数据集。
- 对于代理系统:实现高效的上下文管理,其中旧的对话历史被光学压缩,释放令牌以进行主动推理。
- 对于文档处理:部署比现有解决方案更快、更高效的生产 OCR 系统,同时保持竞争准确性。
- 研究目的:使用 DeepSeek-OCR 作为探索上下文压缩、记忆机制和视觉语言权衡的试验台。
局限性
DeepSeek-OCR 是一个研究模型,该论文对其局限也坦诚相告:
- 压缩率超过 10 倍时性能会下降
- 拥有 1,000 多个代币的复杂布局可能会对模型造成挑战
- 该模型不是通用聊天机器人(没有 SFT/RLHF)
- 仍然需要真正的上下文压缩验证(大海捞针测试等)
作者明确将其定位为“初步探索”和“概念验证”。在一个充斥着夸大其词的领域,这种诚实令人耳目一新。
结论
DeepSeek-OCR 代表了从“我们如何扩展上下文窗口?”到“我们如何智能地压缩上下文?”的转变。
该模型证明,通过光学表示可以实现 10 倍无损压缩。这并非空穴来风——真实文档的验证准确率高达 97%。
更重要的是,它开辟了一个研究方向,或许可以重塑我们对长上下文人工智能系统的思考方式。与其与二次缩放作斗争,不如通过压缩来解决这个问题。
其影响远不止提高个人生产力或改进文档解析,而是要让人工智能系统在其基本任务——信息处理和推理——上更加高效。
与大多数向世界做出承诺并提供 API 端点的 AI 研究不同,DeepSeek-OCR 为我们提供了开放的权重、透明的基准和诚实的限制。


