我们或许能通过文本到图像的方法实现近 10 倍无损上下文压缩。
没想到吧,DeepSeek 刚刚开源了新模型,还是一款 OCR 模型。可以看到,该模型的参数量为 3B,刚上线不久就已经有 100 多次下载量了。
该项目由 DeepSeek 三位研究员 Haoran Wei、Yaofeng Sun、Yukun Li 共同完成。其中一作 Haoran Wei 曾在阶跃星辰工作过,曾主导开发了旨在实现「第二代 OCR」的 GOT-OCR2.0 系统(arXiv:2409.01704),该项目已在 GitHub 收获了超 7800 star。也因此,由其主导 DeepSeek 的 OCR 项目也在情理之中。

论文标题:DeepSeek-OCR: Contexts Optical Compression
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR
DeepSeek 表示,DeepSeek-OCR 模型是通过光学二维映射技术压缩长文本上下文可行性的初步探索。
该模型主要由 DeepEncoder 和 DeepSeek3B-MoE-A570M 解码器两大核心组件构成。其中 DeepEncoder 作为核心引擎,既能保持高分辨率输入下的低激活状态,又能实现高压缩比,从而生成数量适中的视觉 token。
实验数据显示,当文本 token 数量在视觉 token 的 10 倍以内(即压缩率 <10×)时,模型的解码(OCR)精度可达 97%;即使在压缩率达到 20× 的情况下,OCR 准确率仍保持在约 60%。
这一结果显示出该方法在长上下文压缩和 LLM 的记忆遗忘机制等研究方向上具有相当潜力。
此外,DeepSeek-OCR 还展现出很高的实用价值。在 OmniDocBench 基准测试中,它仅使用 100 个视觉 token 就超过了 GOT-OCR2.0(每页 256 个 token) 的表现;同时,使用不到 800 个视觉 token 就优于 MinerU2.0(平均每页超过 6000 个 token)。在实际生产环境中,单张 A100-40G GPU 每天可生成超过 20 万页(200k+) 的 LLM/VLM 训练数据。
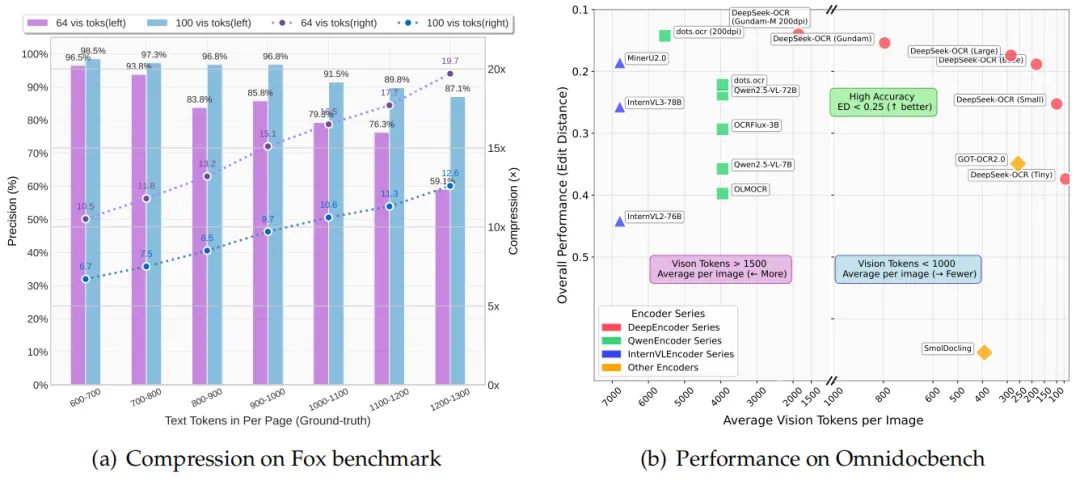
DeepSeek-OCR 在端到端模型测试中以最少的视觉 token 数达到了最先进的性能。
DeepSeek-OCR:上下文光学压缩
DeepSeek 探索的方法概括起来就是:利用视觉模态作为文本信息的高效压缩媒介。
什么意思呢?我们知道,一张包含文档文本的图像可以用比等效文本少得多的 Token 来表示丰富的信息,这表明:通过视觉 Token 进行光学压缩可以实现高得多的压缩率。
基于这一洞见,DeepSeek 从以 LLM 为中心的视角重新审视了视觉语言模型 (VLM),其中,他们的研究重点是:视觉编码器如何提升 LLM 处理文本信息的效率,而非人类已擅长的基本视觉问答 (VQA) 任务。
DeepSeek 表示,OCR 任务作为连接视觉和语言的中间模态,为这种视觉 - 文本压缩范式提供了理想的试验平台,因为它在视觉和文本表示之间建立了自然的压缩 - 解压缩映射,同时提供了可量化的评估指标。
DeepSeek-OCR 便由此而生。这是一个为实现高效视觉 - 文本压缩而设计的 VLM。
如下图所示,DeepSeek-OCR 采用了一个统一的端到端 VLM 架构,由一个编码器和一个解码器组成。
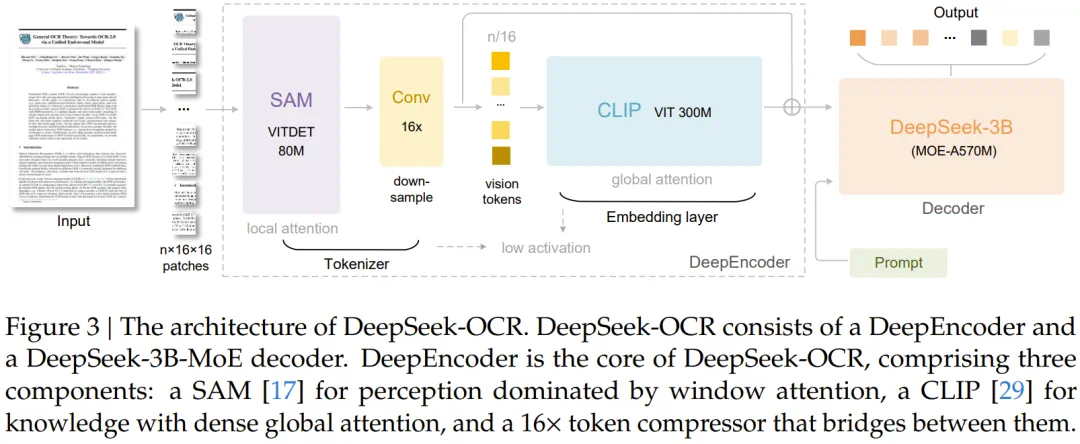
其中,编码器 (即 DeepEncoder) 负责提取图像特征,并将视觉表示进行 Token 化和压缩。解码器则用于根据图像 Token 和提示词 (prompt) 生成所需的结果。
DeepEncoder 的参数量约为 3.8 亿 (380M),主要由一个 80M 的 SAM-base 和一个 300M 的 CLIP-large 串联而成。解码器采用 3B MoE 架构,激活参数量为 5.7 亿 (570M)。
DeepEncoder
DeepSeek 研究发现,为了探索上下文光学压缩的可行性,我们需要一个具备以下特点的视觉编码器:
1. 能够处理高分辨率;
2. 在高分辨率下激活值低;
3. 视觉 Token 数量少;
4. 支持多分辨率输入;
5. 参数量适中。
然而,现有的开源编码器无法完全满足所有这些条件。因此,DeepSeek 自行设计了一款新颖的视觉编码器,命名为 DeepEncoder。
DeepEncoder 主要由两个组件构成:一个以窗口注意力为主的视觉感知特征提取组件,以及一个采用密集全局注意力的视觉知识特征提取组件。
基于之前相关研究的预训练成果,该团队分别使用 SAM-base (patch 大小为 16) 和 CLIP-large 作为这两个组件的主要架构。
对于 CLIP,他们移除了其第一个 patch 嵌入层,因为它的输入不再是图像,而是来自前一个流程的输出 Token。在两个组件之间,该团队借鉴了 Vary 的设计(参阅论文《Vary: Scaling up the vision vocabulary for large vision-language model》),使用了一个 2 层的卷积模块对视觉 Token 进行 16 倍的下采样。每个卷积层的核大小为 3,步长为 2,填充为 1,通道数从 256 增加到 1024。假设我们输入一张 1024×1024 的图像,DeepEncoder 会将其分割成 1024/16 x 1024/16 = 4096 个 patch Token。
由于编码器的前半部分主要由窗口注意力构成,且参数量仅为 80M,因此其激活值是可接受的。在进入全局注意力之前,这 4096 个 Token 会经过压缩模块,数量变为 4096/16 = 256,从而使得整体的激活内存变得可控。
MoE 解码器
该模型的解码器使用了 DeepSeekMoE ,具体为 DeepSeek-3B-MoE。
在推理过程中,模型会激活 64 个路由专家中的 6 个以及 2 个共享专家,激活参数量约为 5.7 亿 (570M)。3B 的 DeepSeekMoE 非常适合以领域为中心 (这里即为 OCR) 的 VLM 研究,因为它在获得 3B 模型表达能力的同时,也享有了 5 亿 (500M) 参数量小模型的推理效率。
解码器从 DeepEncoder 压缩后的潜在视觉 Token 中重建原始文本表示,过程如下:
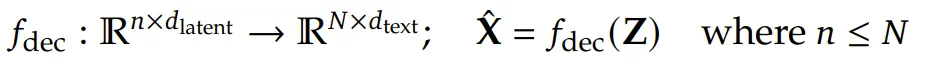
其中 Z 是来自 DeepEncoder 的压缩后潜在 (视觉) Token,而 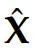 是重建的文本表示。函数 f_dec 代表一个非线性映射,紧凑的语言模型可以通过 OCR 风格的训练来有效地学习它。DeepSeek 推测认为:大语言模型通过专门的预训练优化,将能更自然地集成这类能力。
是重建的文本表示。函数 f_dec 代表一个非线性映射,紧凑的语言模型可以通过 OCR 风格的训练来有效地学习它。DeepSeek 推测认为:大语言模型通过专门的预训练优化,将能更自然地集成这类能力。
数据引擎
DeepSeek 也为 DeepSeek-OCR 构建了复杂多样的训练数据,包括:
OCR 1.0 数据,主要包含传统 OCR 任务,如场景图像 OCR 和文档 OCR;
OCR 2.0 数据,主要包括复杂人造图像的解析任务,如常见图表、化学分子式和平面几何解析数据;
通用视觉数据,主要用于为 DeepSeek-OCR 注入一定的通用图像理解能力,并保留通用的视觉接口。
数据方面,DeepSeek 还进行了更多有利于 OCR 任务的设计,详情请参阅原论文。
训练流程
该模型的训练流程非常简单,主要包括两个阶段:
独立训练 DeepEncoder
训练 DeepSeek-OCR
DeepEncoder 的训练遵循 Vary 的方法,利用一个紧凑的语言模型并采用下一个 Token 预测的框架来训练 DeepEncoder。
在此阶段,DeepSeek 使用了前文提到的所有 OCR 1.0 和 2.0 数据,以及从 LAION 数据集中采样的 1 亿条通用数据。所有数据均使用 AdamW 优化器和余弦退火调度器进行训练,共训练 2 个 epoch,批处理大小为 1280,学习率为 5e-5。训练序列长度为 4096。
在 DeepEncoder 准备就绪后,再训练 DeepSeek-OCR。整个训练过程在 HAI-LLM 平台上进行。整个模型采用了流水线并行 (PP),并被分为 4 个部分,其中 DeepEncoder 占用两部分,解码器占用两部分。
对于 DeepEncoder,DeepSeek 将 SAM 和压缩器视为视觉 Tokenizer,放置在 PP0 上并冻结其参数;同时将 CLIP 部分视为输入嵌入层,放置在 PP1 上,其权重不冻结并参与训练。对于语言模型部分,由于 DeepSeek3B-MoE 有 12 层,他们在 PP2 和 PP3 上各放置 6 层。
他们使用 20 个节点 (每个节点配备 8 个 A100-40G GPU) 进行训练,数据并行 (DP) 度为 40,全局批处理大小为 640。优化器为 AdamW,配合基于步数 (step-based) 的调度器,初始学习率为 3e-5。对于纯文本数据,训练速度为每天 900 亿 Token;对于多模态数据,训练速度为每天 700 亿 Token。
实验结果
视觉 - 文本压缩
研究选用了 Fox 基准数据集来验证 DeepSeek-OCR 在文本密集型文档上的压缩与解压能力。
如表 2 所示,在 10× 压缩比的情况下,模型的解码精度可达约 97%。
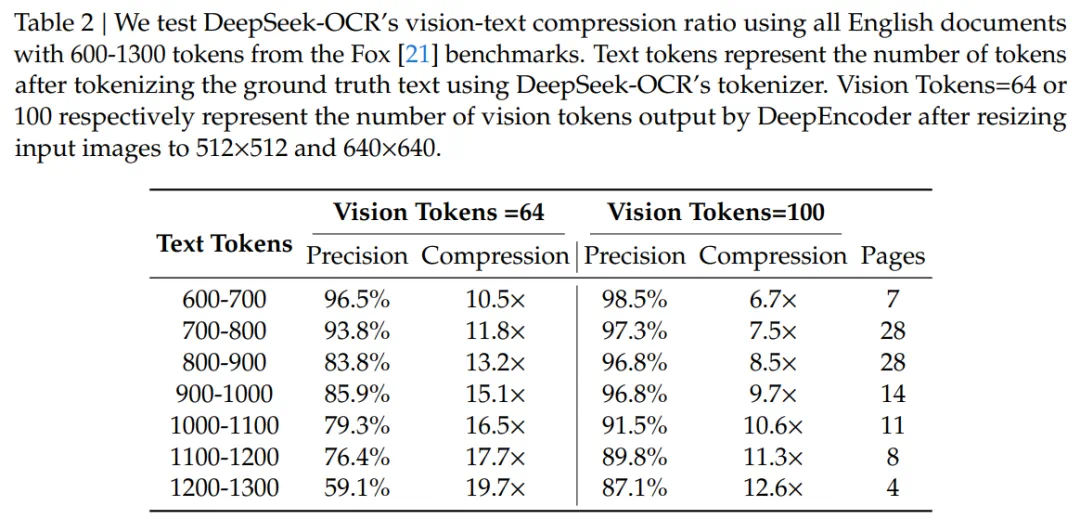
当压缩比超过 10× 时,性能开始下降,他们猜测可能有两个原因:
长文档的版面布局更复杂,导致信息分布不均;
在 512×512 或 640×640 分辨率下,长文本会变得模糊。
当压缩比接近 20× 时,作者发现模型的精度仍可达到约 60%。
OCR 实际性能
DeepSeek-OCR 不仅是一个实验性模型,还具备很强的实用能力。结果如表 3 所示。
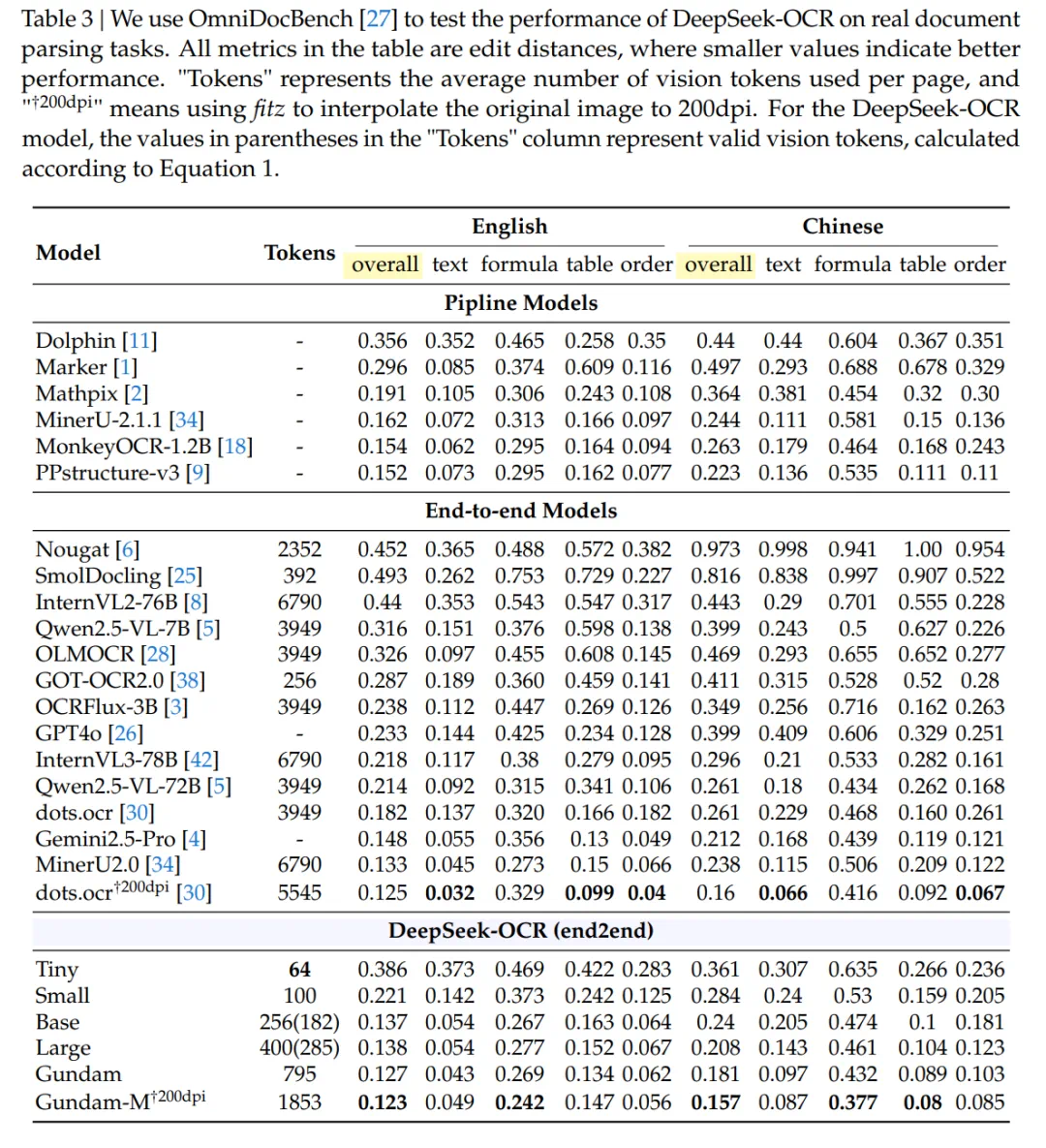
具体而言:
在仅使用 100 个视觉 token(分辨率 640×640) 的情况下,DeepSeek-OCR 的表现超越了使用 256 个 token 的 GOT-OCR2.0 ;
当使用 400 个视觉 token(其中有效 token 为 285,分辨率 1280×1280) 时,其性能已可与当前 SOTA 模型相当;
进一步地,在使用不到 800 个视觉 token(即 Gundam 模式) 时,DeepSeek-OCR 的性能超过了 MinerU2.0 ,后者需要近 7,000 个视觉 token。
这些结果表明,DeepSeek-OCR 在实际应用中表现出极强的性能与效率,并且由于其更高的 token 压缩率,具有更高的研究潜力与扩展空间。
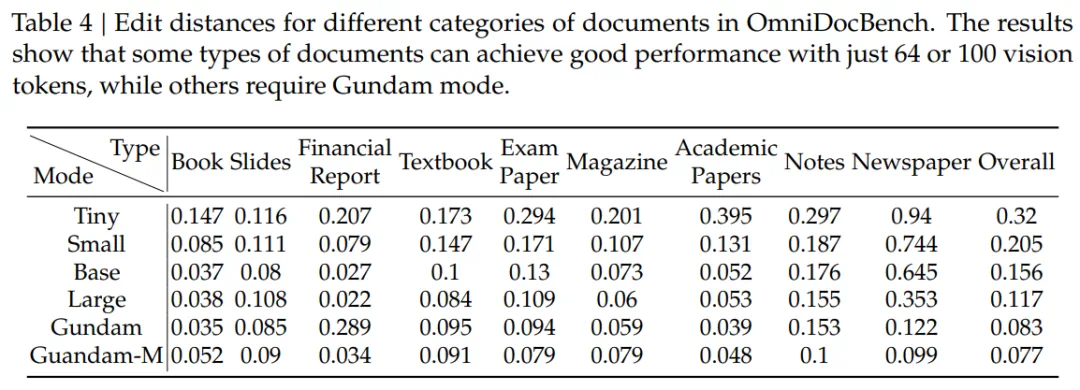
表 4 结果表明,不同类型文档对视觉 token 的需求差异较大:
对于幻灯片类文档,仅需 64 个视觉 token 即可达到令人满意的识别效果;
对于书籍和报告类文档,100 个视觉 token 即可取得较好表现。
定性研究
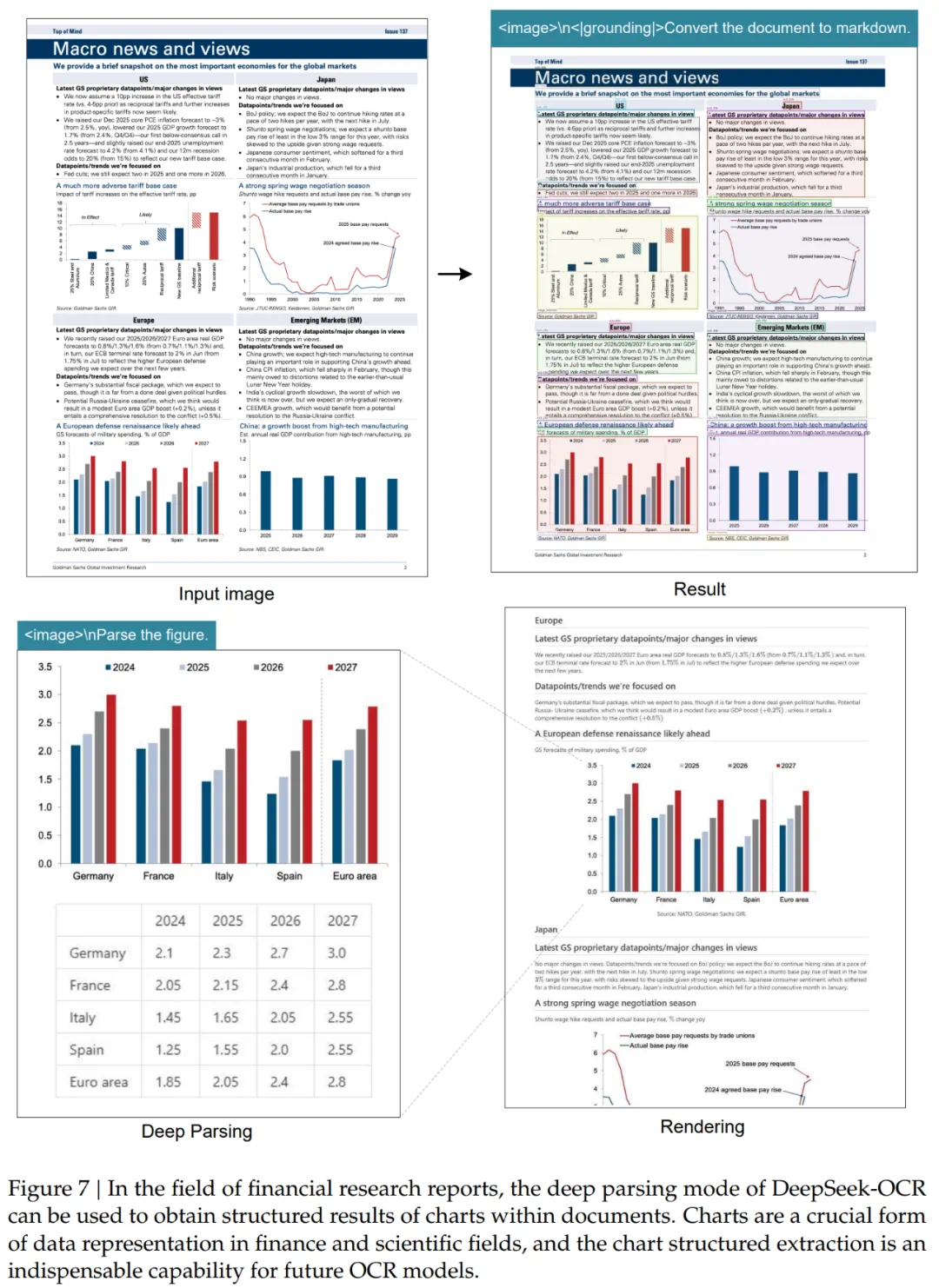
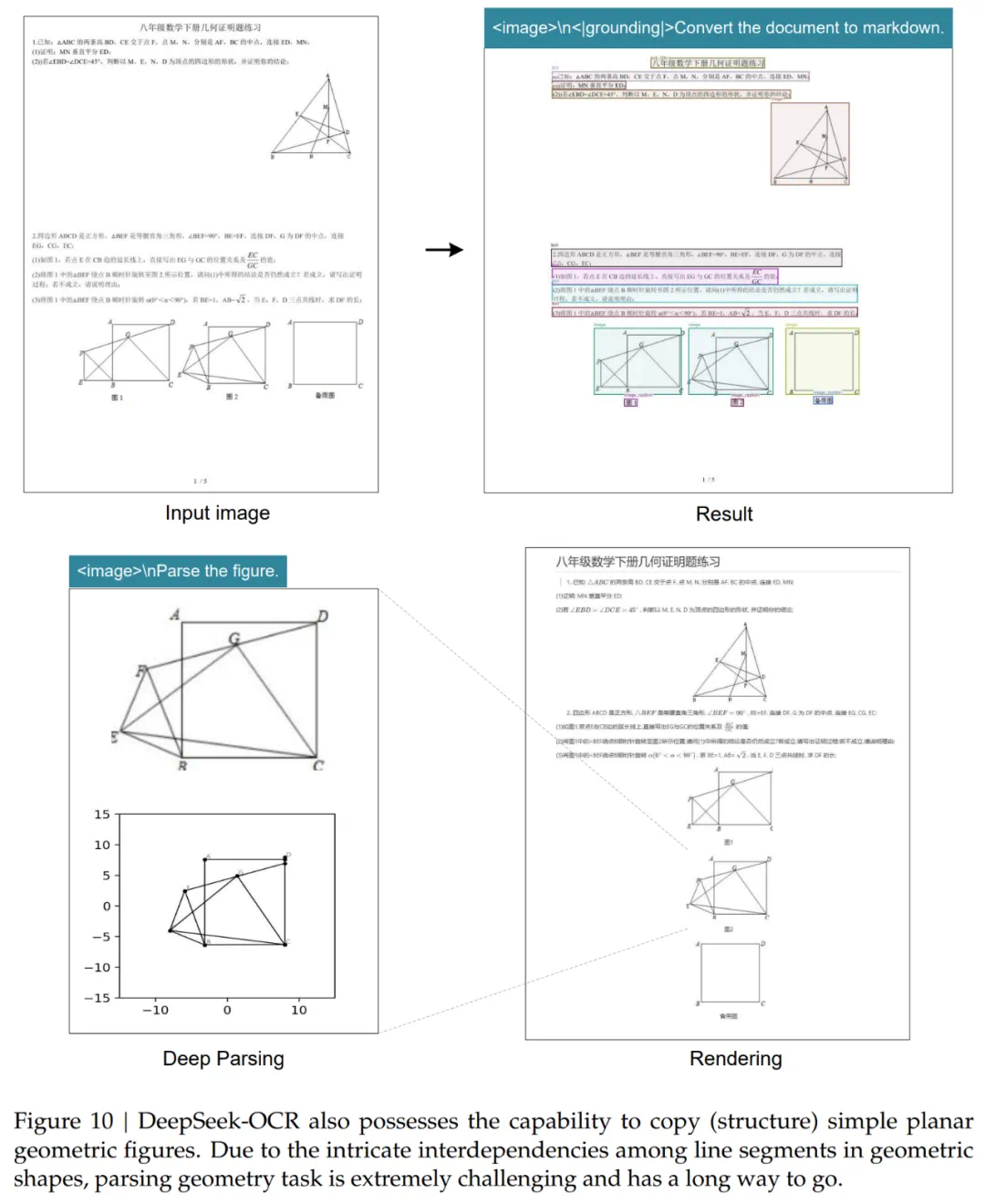
图 7、图 8、图 9、图 10 所示,模型能够对图表、几何图形、化学公式,甚至自然图像进行深度解析,只需使用一个统一的提示词(prompt)即可完成。


多语言识别:针对 PDF 文档,DeepSeek-OCR 支持近 100 种语言的识别。
如图 11 所示展示了 DeepSeek-OCR 在阿拉伯语(Arabic) 与僧伽罗语(Sinhala) 的可视化识别结果。

通用视觉理解:此外,DeepSeek-OCR 还具备一定程度的通用图像理解能力,相关的可视化结果如图 12 所示。



