 图片
图片
最近你要是混迹在 AI 圈,或者经常玩 Hugging Face、CSDN、GitHub 上的开源模型,肯定会碰到一个后缀:
👉 .gguf
比如:qwen2-7b-instruct.Q4_K_M.gguf
很多人第一次见到就一头雾水:这是模型吗?压缩包吗?还是量化格式?今天我就用白话跟你聊聊 GGUF 是什么、为什么大家都在用、它到底解决了什么问题。
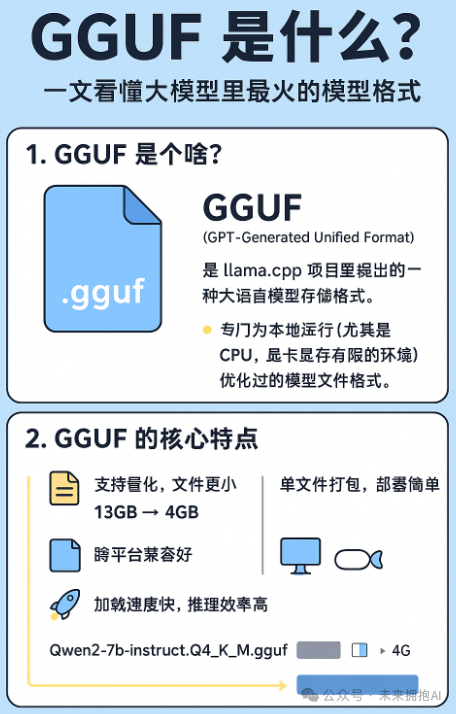
1. GGUF 是个啥?
GGUF 全称是 “GPT-Generated Unified Format”,是 llama.cpp 项目里提出的一种 大语言模型存储格式。
一句话总结:
GGUF 是专门为本地运行(尤其是 CPU、显卡显存有限的环境)优化过的模型文件格式。
它的目标很直接:让你能更方便、更高效地在各种设备上运行大模型,不论是笔记本电脑、手机,还是带消费级 GPU 的 PC。
2. GGUF 之前的问题
在 GGUF 出现之前,很多人用过 GGML / GGJT 这些格式,那时的问题主要有:
- 兼容性差:不同项目用不同的格式,模型文件互不兼容,很难“一处下载,到处运行”。
- 模型太大:原始的 PyTorch .bin 或者 Hugging Face safetensors 格式,参数是 FP16/FP32,动不动几十 G,普通人电脑跑不动。
- 量化支持不统一:大家都在搞量化(比如 int4、int8),但是文件怎么存、参数怎么读,每个库都自己搞一套,开发者和用户都头疼。
GGUF 就是在这种背景下被设计出来的,它的目标是统一、轻量、跨平台。
3. GGUF 的核心特点
我用大白话总结成 5 点:
(1)支持量化,文件更小
- 量化就是把模型参数从高精度(FP16/FP32)“压缩”成低精度(INT4、INT8 等),减少体积和显存占用。
- GGUF 原生支持多种量化方式,比如 Q4_K_M, Q5_1, Q8_0 等。
- 举个例子:一个 7B 参数的模型,原始可能要 13GB,量化后 GGUF 文件能降到 4GB 左右。
就好比一部蓝光电影 30GB,压成 MP4 之后只剩 5GB,你手机也能流畅播放。
(2)单文件打包,部署简单
- GGUF 把模型参数、元信息(词表、超参数、量化信息)都存在一个文件里。
- 下载下来就是一个 .gguf,直接丢给 llama.cpp、ollama、LM Studio、KoboldAI 之类的工具就能用。
不用像以前一样东拼西凑,还要改配置。
(3)跨平台兼容好
GGUF 是专门为 llama.cpp 生态设计的,而 llama.cpp 已经支持:
- Windows / Mac / Linux
- CPU / GPU / Apple Metal / Vulkan / CUDA
- 甚至手机(安卓、iOS 通过移植)
所以 GGUF 格式的模型几乎可以“一处下载,多端运行”。
(4)加载速度快、推理效率高
因为它的存储布局(比如权重排列、缓存方式)是专门为高效推理设计的。尤其是在量化 + llama.cpp 的优化下,可以做到:
- CPU 也能跑大模型(虽然速度有限)
- 消费级 GPU 更友好(比如 6GB 显存的显卡,也能跑 7B 模型)
(5)社区支持广
Hugging Face 上很多热门模型(LLaMA、Mistral、Qwen、Baichuan、Yi 等)都已经有人转好了 GGUF 格式,直接下载就能用。
4. GGUF 命名规则怎么看?
很多人第一次看到 GGUF 文件名会懵,比如:
复制拆开来解读:
- qwen2-7b-instruct → 模型名字 + 大小 + 是否微调
- Q4_K_M → 量化类型(Q 表示 quantization,数字代表精度,后面是具体方案,比如 K_M)
- .gguf → 文件格式
所以一眼就能看出:这是 Qwen2 的 7B 指令微调版,用 Q4_K_M 的量化,存储成 GGUF 格式。
5. GGUF 的适用场景
哪些人特别适合用 GGUF?
- 想在本地电脑跑大模型的人 → 不用云 API,保护隐私、避免高额调用费用
- 显存不大但想玩 LLM 的人 → 量化模型让小显存也能跑
- 开发者 / 爱好者 → 可以快速测试不同模型,不用折腾复杂环境
- 移动端 / 边缘设备部署 → GGUF 的轻量特性非常适合
6. GGUF 的局限
说了优点,也得说缺点:
- 量化会带来 精度损失:虽然一般对日常对话没大影响,但在数学、编程等高精度任务上可能差一点。
- 主要还是围绕 llama.cpp 生态,虽然现在已经很广了,但在部分专用框架里不一定支持。
- 更新迭代快:社区很活跃,格式规范可能会随版本更新,所以要注意工具和模型的兼容性。
7. 总结
一句话概括:
GGUF 是一个统一、轻量、跨平台的大模型存储格式,特别适合本地运行和低资源环境。
它的出现,让“人人都能在自己电脑上跑大模型”变得更现实。就像当年 MP3 让音乐文件普及一样,GGUF 可能会是大模型走向大众化的关键一步。


