
在大语言模型(LLMs)不断拓展能力边界的今天,长文本处理始终是道绕不开的坎——文本序列每增加一倍,计算量就可能翻四倍,像处理一本几十万字的书籍、一份上千页的金融报告时,内存溢出、推理卡顿成了常态。
但DeepSeek团队最近开源的DeepSeek-OCR模型,给出了一个全新解法:把文本“画”成图像,用视觉Token实现高效压缩。原本需要1000个文本Token存储的内容,现在100个视觉Token就能搞定,还能保持97%的OCR精度。这种“光学压缩”思路,不仅让长文本处理效率飙升,更给大模型的“记忆机制”研究打开了新窗口。
目前,DeepSeek-OCR的代码、模型权重、论文已经全部开源,大家可以直接上手试用:
- 论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
- 项目地址:https://github.com/deepseek-ai/DeepSeek-OCR
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR
01、为什么要给长文本“换一种存储方式”?
传统LLM处理长文本的痛点,本质是“文本Token的低效性”——一段文字里藏着大量冗余信息,却要靠一个个Token线性存储,导致计算量随长度呈平方级增长。比如要处理1万字的文档,可能需要上万个文本Token,模型光是建立这些Token间的关联,就要消耗大量算力。
DeepSeek团队的核心洞察是:视觉是更高效的信息压缩媒介。一张包含文字的图片,能比纯文本少用几十倍的Token来传递同样信息。就像我们看一页书时,眼睛能瞬间捕捉整页内容,而不是逐字逐句读取——这种“二维视觉优势”,正是解决长文本瓶颈的关键。
更巧的是,OCR(光学字符识别)任务成了绝佳的“试验场”。它既要把图像里的文字“解压缩”成文本(验证压缩效果),又能通过精度、压缩比等指标量化性能,完美契合“视觉-文本压缩”的研究需求。
02、核心架构:两大组件实现“压缩-解压”闭环
DeepSeek-OCR的架构特别简洁,就像一套“文本压缩工具包”,由编码器(DeepEncoder)和解码器(DeepSeek3B-MoE)组成,前者负责“压得小”,后者负责“解得出”。
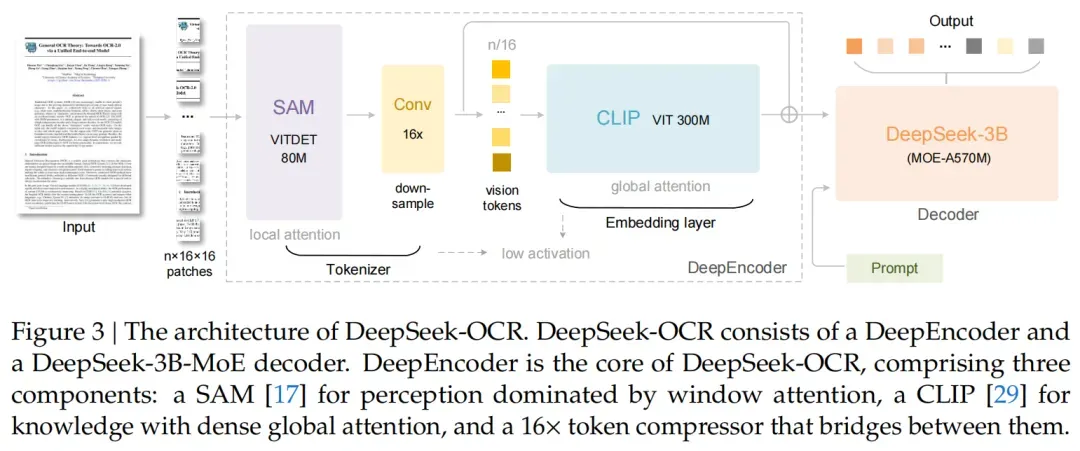
DeepEncoder:高分辨率下的“Token瘦身大师”
传统视觉编码器在应对高分辨率图像时,存在两个突出问题。一方面,处理高分辨率图像时会生成过多的 Token。以 1024×1024 的图像为例,会生成 4096 个 Token(1024/16×1024/16 = 4096),过多的 Token 会导致计算量大幅增加,给后续的处理带来沉重负担。另一方面,部分编码器在对图像进行压缩后,细节丢失严重,这对于需要精准识别文本的 OCR 任务来说是致命的,会极大影响识别的准确性和完整性。
DeepEncoder通过“局部+全局”的双阶段设计,完美平衡了“压缩比”和“保真度”:
- 第一步:局部感知(窗口注意力)采用 SAM-base 模型:DeepEncoder 使用参数为 8000 万的 SAM-base 模型 ,该模型将输入的图像分割成 16×16 的小 patch。这种方式就如同使用 “显微镜”,能够聚焦于图像的每一个细微部分,精确捕捉每个字符的细节信息。窗口注意力机制控制计算量:在生成较多 Token 的情况下,窗口注意力机制发挥了关键作用。它使得模型在处理这些 Token 时,计算量处于可控范围。窗口注意力机制会限定模型关注的区域,只对窗口内的 Token 进行计算,避免了对所有 Token 同时进行大规模计算带来的高复杂度,确保了模型在高分辨率图像局部处理时的高效性和稳定性。
- 第二步:全局压缩(16×卷积+全局注意力)2 层卷积模块压缩 Token 数量:经过局部感知后,DeepEncoder 利用一个 2 层卷积模块对生成的 Token 进行压缩。这个卷积模块能够将 Token 数量大幅减少,例如把 4096 个 Token 压缩到 256 个,压缩比例达到 1/16 。CLIP-large 模型实现全局理解:压缩后的 Token 会被传输到 3 亿参数的 CLIP-large 模型。CLIP-large 模型具有强大的全局理解能力,它能将经过初步处理的 “零件”(压缩后的 Token)整合起来,形成对文档的整体认知,就像把一堆零件组装成完整机器。在这个过程中,不仅减少了 Token 数量,降低了后续处理的复杂度,还成功保留了文档的整体布局信息,使得模型在后续的文本解码中,能够更好地还原文档内容,提高 OCR 任务的准确性。
- 多分辨率输入与 “Gundam 模式”多分辨率输入支持:DeepEncoder 支持从 512×512(64 个 Token)到 1280×1280(400 个 Token)的多分辨率输入。不同分辨率适用于不同的场景和需求,较低分辨率在处理简单文档或对精度要求稍低的场景下,可以提高处理速度;较高分辨率则能在处理复杂文档或对细节要求严格的任务时,保证信息的完整性和准确性。“Gundam 模式” 处理大图像:对于像报纸这种超长篇幅的大图像,DeepEncoder 通过 “Gundam 模式” 将其拆分成小瓦片进行处理。这种方式进一步降低了处理大图像时的计算压力,同时保证了对大图像内容的有效处理。通过 “Gundam 模式”,DeepSeek-OCR 能够适应各种复杂的文档场景,真正实现了 “按需压缩”,在不同的应用场景下都能展现出良好的性能 。

DeepEncoder 通过独特的 “局部 + 全局” 双阶段设计以及对多分辨率输入和 “Gundam 模式” 的支持,有效解决了传统视觉编码器的问题,在高分辨率图像的处理上实现了高效的 Token 压缩和信息保留,为 DeepSeek-OCR 在 OCR 任务中的出色表现奠定了坚实基础。
DeepSeek3B-MoE:小参数也能高效“解压”
解码器没有用传统的大模型,而是选了30亿参数的混合专家(MoE)架构,推理时从64 个路由专家中只激活6个专家模块(总激活参数5.7亿)。这种设计的好处很明显:
- 既有30亿参数模型的“理解能力”,能精准把视觉Token还原成文本;
- 又有小模型的“速度优势”,单张A100-40G显卡一天能处理20万页文档,比传统OCR工具快好几倍。
它的“解压逻辑”也很清晰:通过非线性映射,把DeepEncoder输出的压缩视觉Token(n个),还原成原始文本Token(N个,n≤N),就像把压缩包还原成完整文件一样。
03、性能有多能打?数据说话
压缩比与精度:10倍压缩近乎无损
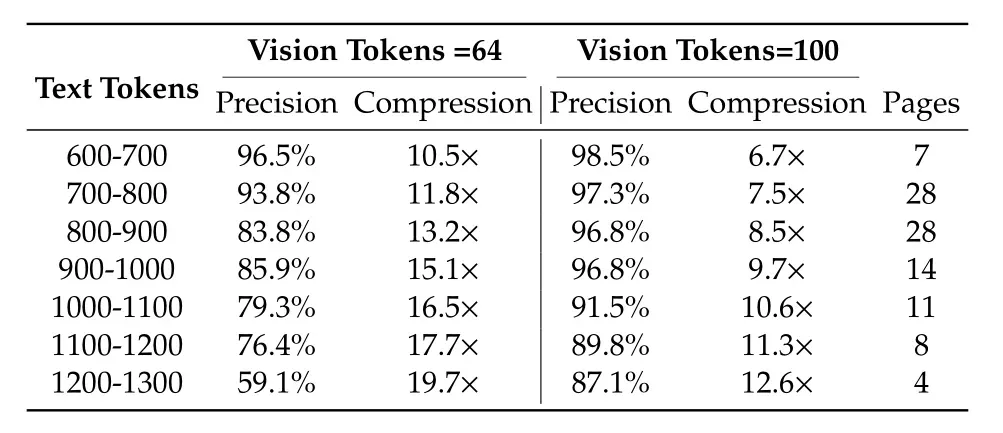
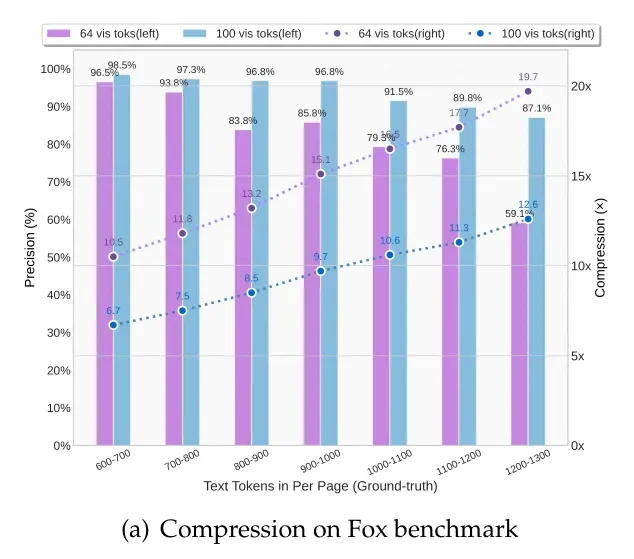
在Fox基准测试(包含多种文档布局)中,DeepSeek-OCR的表现超出预期:
- 当文本Token是视觉Token的10倍以内(压缩比<10×)时,OCR精度能到97%,相当于把1000字的文档压成100个视觉Token,还原后几乎没错字;
- 就算压缩到20倍(2000字对应100个视觉Token),精度仍有60%,核心信息基本能保留。
这个结果说明,未来用“文本转图像”实现“无损压缩”完全有可能——而且不用额外加算力,因为它能直接复用视觉语言模型(VLM)的基础设施。
实际任务:用更少Token赢过主流模型
在真实文档解析任务(OmniDocBench基准)中,它的“性价比”优势更明显:
- 仅用100个视觉Token,就超过了需要256个Token的GOT-OCR2.0;
- 使用 400 个视觉Token,性能与该基准测试上的当前最优模型持平。
- 用不到800个视觉Token,性能碾压了平均需要6000+个Token的MinerU2.0。
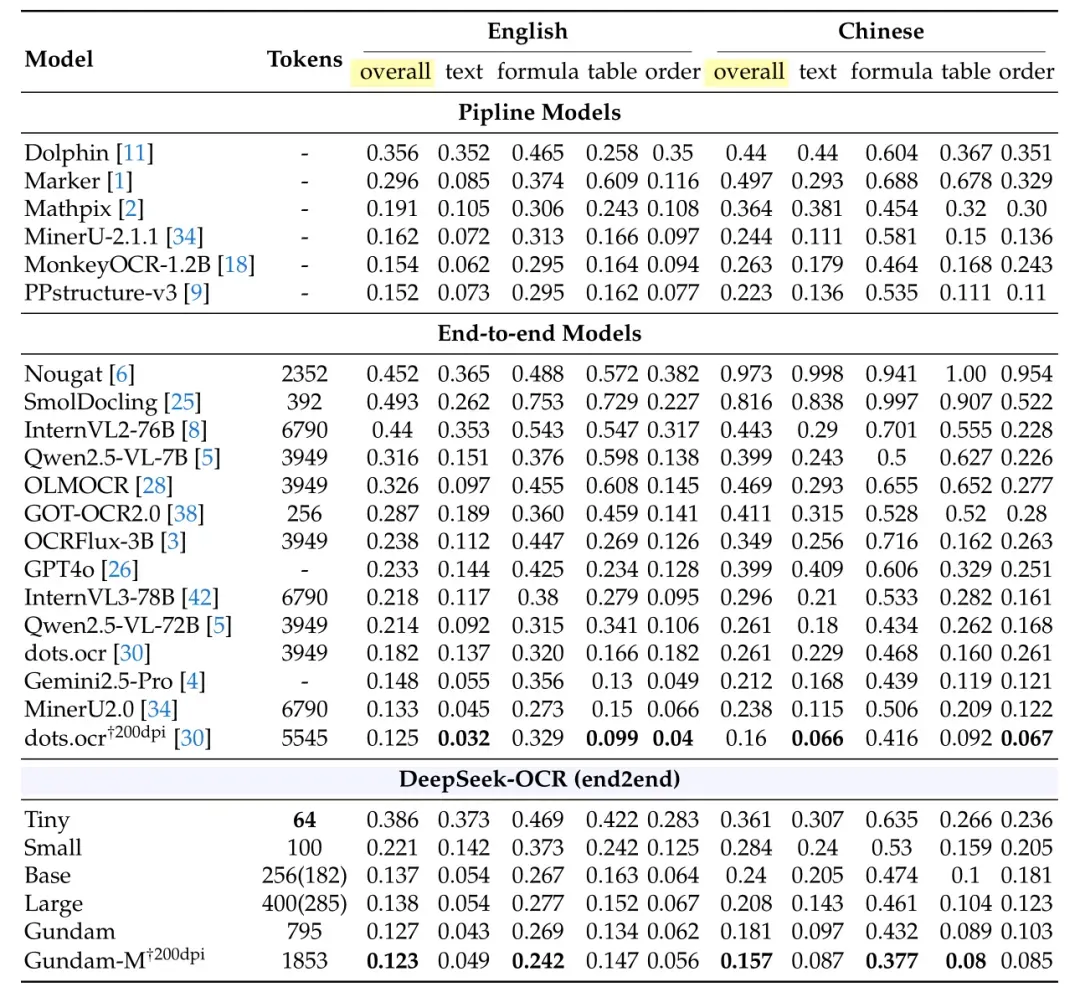
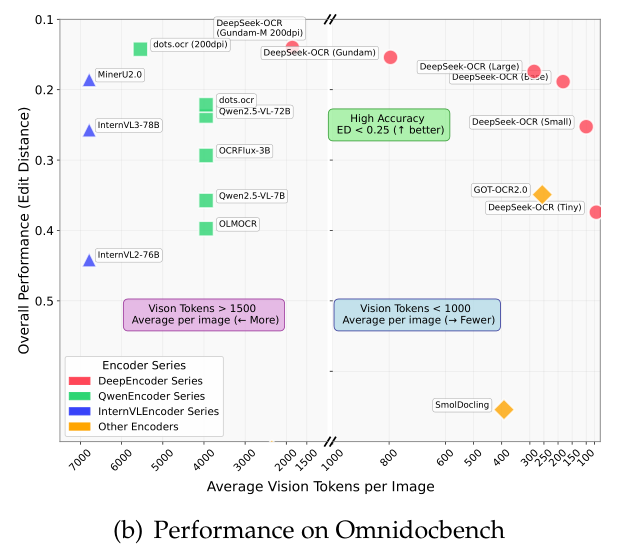
关键结论:
- 部分类别文档仅需极少数Token即可达到理想性能。例如,幻灯片(slides)仅需 64 个视觉Token;书籍(book)和报告(report)类文档使用 100 个视觉Token即可实现良好性能。这可能是因为这些文档中大多数文本Token数量在 1000 以内,视觉 - 文本压缩比未超过 10×。
- 对于报纸(newspaper)类文档,由于文本Token数量通常在 4000-5000 之间,远超其他模式 10× 压缩比的处理范围,需要使用 Gundam 模式甚至 Gundam-master 模式才能达到可接受的编辑距离(edit distance),为 VLMs 的视觉Token优化、LLMs 的上下文压缩及遗忘机制等研究提供了参考。
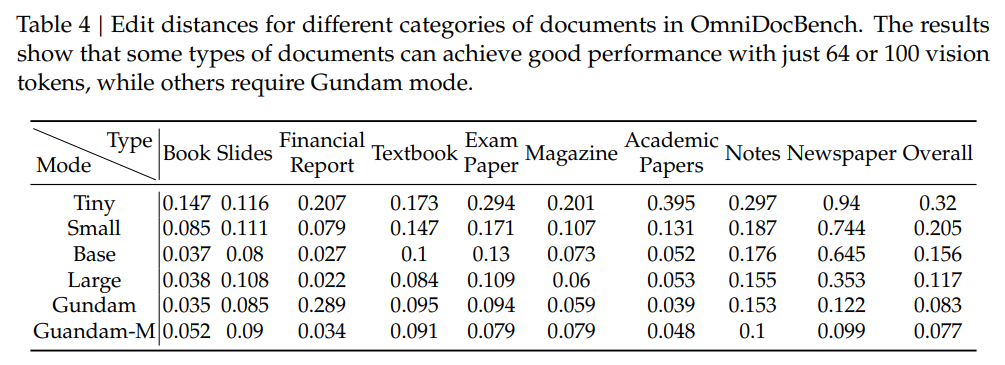
深度解析:不止能识字,还能解析图表、公式、多语言
DeepSeek-OCR 具备布局处理和 OCR 2.0 任务处理能力,可通过二次调用对文档中的图像进行进一步解析,称为“深度解析”(deep parsing)。只需统一提示词,模型就能对图表、几何图形、化学公式乃至自然图像进行深度解析。
- 图表:把金融报告里的折线图、柱状图,自动转成结构化的HTML表格;
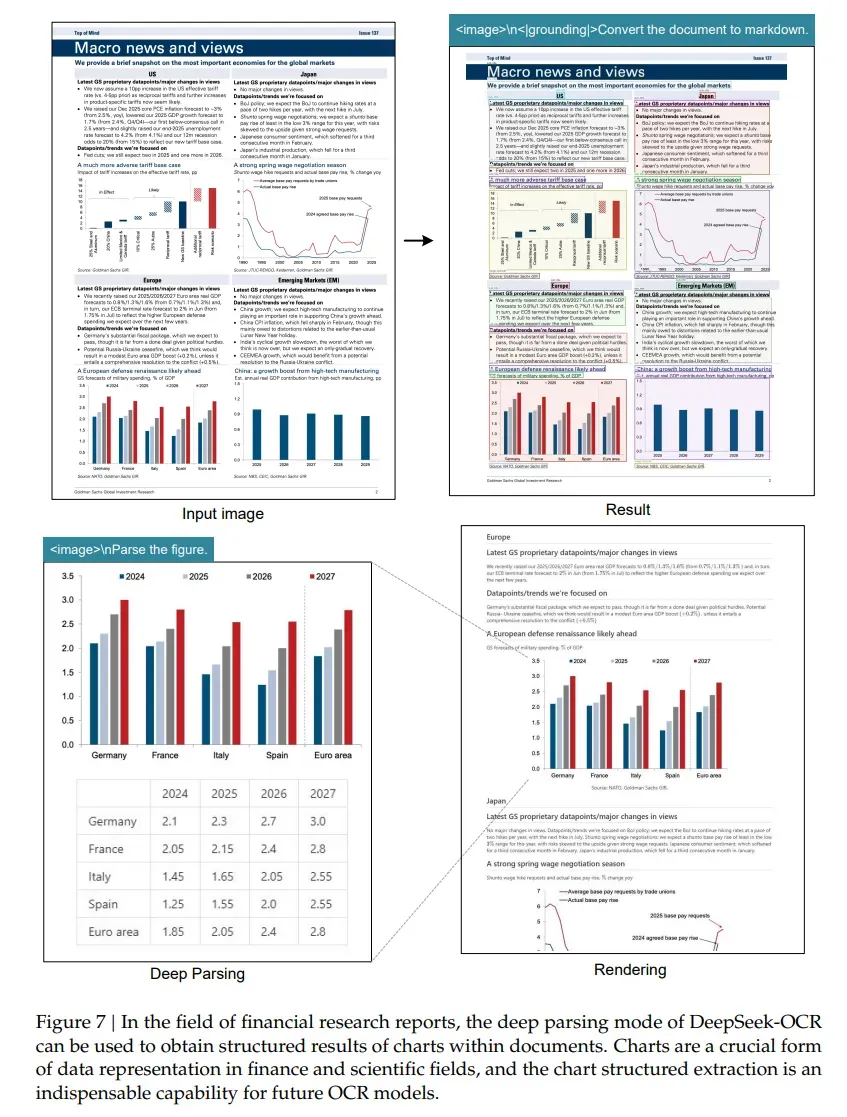
- 书籍和文章:对于书籍和文章,深度解析模式可对自然图像输出密集型描述。

- 化学公式:识别文档里的分子式,输出科研常用的SMILES格式;

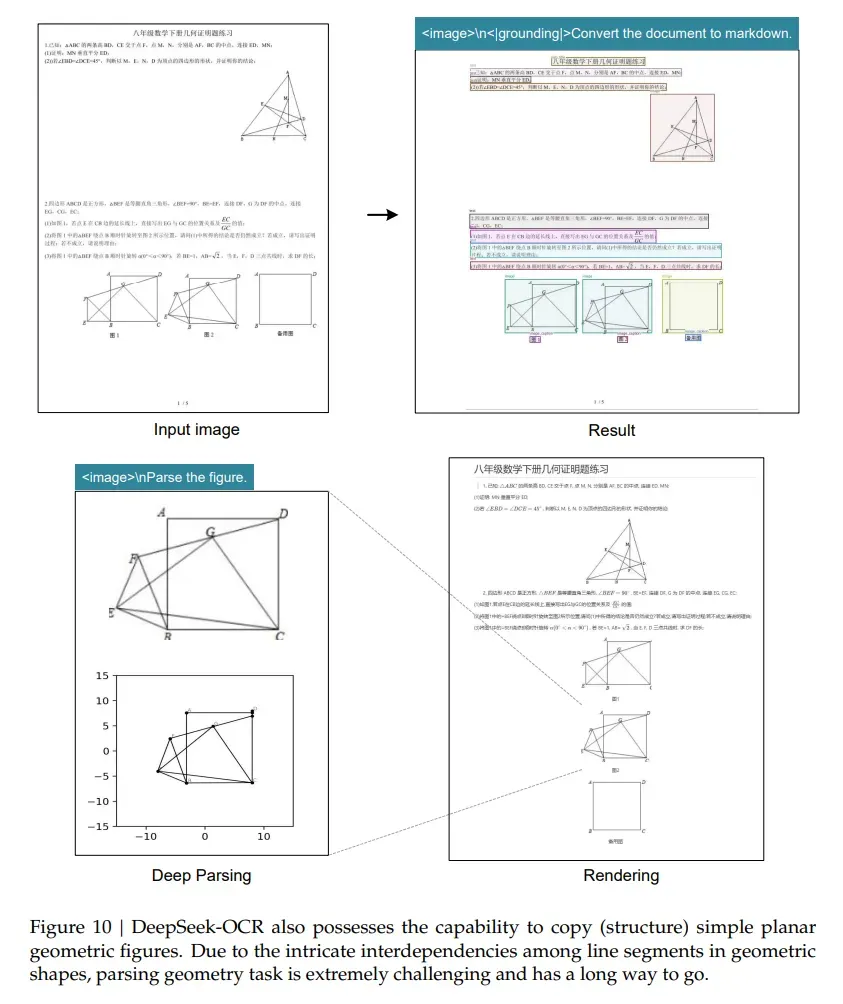
- 几何图形:还原平面几何题里的线段、角度,甚至能标注坐标;
- 多语言:支持近100种语言,从中文、英文到阿拉伯语、僧伽罗语都能搞定。

这些能力让它在金融、科研、教育等场景里“大有用武之地”——比如把几十年的历史病历压缩成图像存储,既能节省空间,又能快速检索关键信息。
通用视觉理解
DeepSeek-OCR 同样具备一定程度的通用图像理解能力,包括图像描述、目标检测、视觉定位等功能。同时,由于训练数据中包含纯文本数据,模型的语言能力也得以保留。但是,模型并非聊天机器人,部分功能需通过完整提示词激活。

04、更大的价值:给大模型装一个“视觉记忆库”
DeepSeek-OCR的意义,远不止是一个高效OCR工具——更在动摇“文本作为大模型核心输入”的固有认知,为LLM的“长上下文处理”提供了颠覆性新范式:视觉模块可以成为LLM的“核心记忆组件”。
传统LLM的“记忆”依赖文本Token存储,就像用一根“无限长的薯条”堆砌信息,不仅占用大量上下文窗口,还受制于分词器的诸多弊病。而DeepSeek-OCR的视觉模块将信息压成“一张小饼”,一举解决几大关键痛点:
- 突破容量瓶颈:依托强大的视觉压缩能力,100个视觉Token可对应上千个文本Token,在OmniDocBench基准测试中甚至能实现最高60倍的压缩比。这种效率提升相当于让LLM的“记忆容量”呈数倍增长,使其能轻松存下整本书、数天的多轮对话记录,从根本上缓解了上下文窗口的容量压力。
- 重构记忆效率:通过分辨率调节实现“按需存储”——近期的重要信息用高分辨率图像保留细节(精准解码),远期的次要信息用低分辨率压缩核心(语义蒸馏),这种“近清远模糊”的模式既贴合人类记忆规律,又大幅降低了算力消耗,完美契合视觉输入的高效特性。
- 实现多模态兼容:视觉输入让信息流更通用,不仅能存纯文本,更能自然融合加粗、彩色文字、图表、图片等丰富格式。例如把带数据图表的财报渲染为图像压缩存储,后续调用时既能读取文字数据,又能还原图表逻辑——这是受限于文本形式的传统记忆完全无法实现的。
- 摆脱分词器桎梏:视觉模块通过像素处理信息,彻底绕开了“丑陋、独立”的分词器,避免了其带来的Unicode兼容、字节编码遗留问题,以及“肉眼相同字符却生成不同Token”的荒谬情况,更消除了由此引发的安全与越狱风险,让记忆存储更纯粹、更可靠。
05、写在最后
DeepSeek-OCR的探索仅仅是个开始,正如Karpathy看完论文后甚至“想立马搞一个只有图像输入的nanochat版本”,这个方向还有无数值得深挖的可能:如何将“视觉压缩”的短期记忆转化为模型的参数化长期记忆?能否基于这种模态转换实现真正的“无限长上下文”对话?视觉输入的双向注意力机制如何与LLM的生成逻辑更高效地衔接?
但无论如何,DeepSeek-OCR已经用事实证明了Karpathy的判断:通过模态转换优化效率,远比单纯堆参数、扩窗口更聪明。它所实践的“文本转视觉”路径,不仅是技术层面的优化,更是对大模型输入范式的重新思考——毕竟“所有‘文本到文本’任务都能转化为‘视觉到文本’任务,反之则不行”。
对于开发者而言,现在就能用它批量处理多格式文档、生成高质量训练数据,享受高压缩率与高准确率带来的效率提升;对于研究人员,它更是验证“视觉输入优越性”的绝佳“试验田”。或许不久后,我们就能看到能“记住一整本书、看懂所有格式”的大模型,而这一切的起点,正如Karpathy所展望的,就是把文本“渲染”成一张图。


