行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!

报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。
基于这些关键技术,MiniCPM-V 4.5在视频理解、图像理解、OCR、文档解析等多项任务上达到同级SOTA水平,不仅以8B的参数规模超越GPT-4o-latest和Qwen2.5-VL-72B,更在推理速度上具有显著优势。
模型一经开源,就广受社区好评,并直接登上HuggingFace Trending TOP2。
截至目前,MiniCPM-V 4.5在HuggingFace、ModelScope两大平台合计下载量超22万。
接下来,就和我们一起看看报告里讲了什么。
研究背景
随着多模态大模型的迅速发展,其在模型架构、数据工程和训练方法上的高昂成本和效率瓶颈,正成为其广泛应用和技术迭代的核心障碍。
而在移动设备和边缘计算场景中,如何在保持出色性能的同时实现高效推理,给多模态模型研究和应用提出了更加严峻的挑战。
总的来说,MiniCPM-V 4.5通过系统性的技术创新攻克三大效率难题:
- 针对模型架构:为解决处理图像与视频时产生的海量视觉Token,团队采用了统一3D-Resampler架构,大幅降低了视觉编码的Token开销,实现最高96倍的压缩率。在VideoMME上,团队以相比Qwen2.5-VL7B仅46.7%的显存和8.7%的时间开销,获得了30B以下参数量模型的最优性能。
- 针对训练数据:为解决多模态文档处理中对不可靠外部解析工具的依赖和OCR数据工程设计难题,团队提出了统一文档OCR与知识学习的新范式,使模型能直接从复杂文档图像中学习,显著降低了数据噪声和数据工程复杂度。最终在OmniDocBench上取得了通用MLLM中的最好表现。
- 针对训练方法:为平衡深度思考与日常即时使用两种需求,团队使用了混合强化学习策略。该策略在节省30%训练开销的同时实现了强大的思考能力,并且推理耗时仅为同规格深度思考模型的42.9%-68.2%,在快速响应与全面分析间取得了可控平衡。
统一的3D-Resampler架构实现高密度视频压缩
Takeawys:
- 时间-空间 统一联合压缩可充分挖掘多模态数据的冗余性,实现更的高视觉压缩率。
- 统一的视觉架构可促进感知能力从图像到视频的无缝迁移。
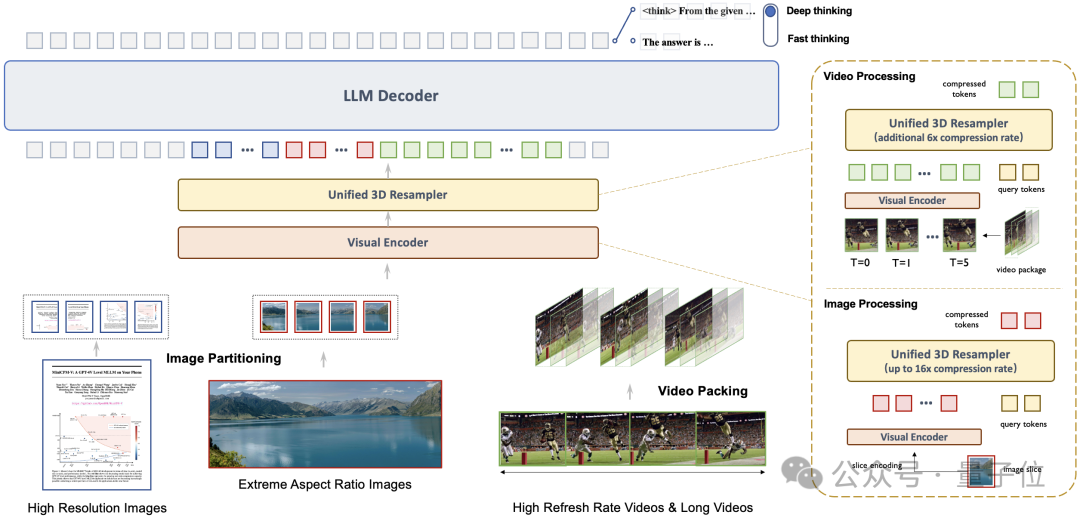
传统多模态模型在处理视频时面临的核心挑战是性能与效率的权衡。
为突破这一困境,MiniCPM-V 4.5引入了创新的3D-Resampler架构。它不再将视频视为独立的静态帧序列,而是同时在时空方向上压缩,利用连续帧间的高度冗余信息,实现了革命性的效率提升。
该架构能将6个连续的视频帧(448×448分辨率)高效压缩为仅64个视觉Token,实现了惊人的96倍视觉压缩率,而多数主流模型处理同等数据需消耗1,536Token。这一设计让模型在不增加语言模型计算成本的前提下,能够感知和处理更多视频帧,且能获得更好的视频理解能力。
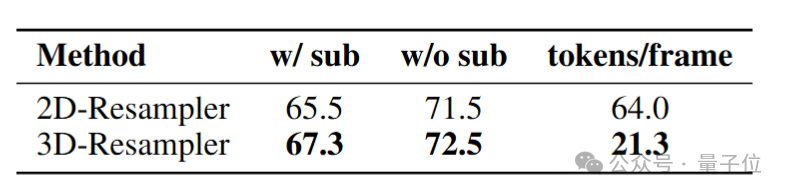
更重要的是,3D-Resampler实现了图像与视频处理的统一编码,确保了知识和能力的无缝迁移。
一个有力的证明是,尽管没有经过专门的视频OCR数据训练,模型依然展现出良好的视频OCR能力。
同时,由于统一的架构设计和参数共享,从2D扩展至3D-Resampler仅需一个轻量化的SFT阶段,极大地降低了训练成本。
高效知识学习:面向文档的统一OCR和知识学习范式
Takeawys:
对文档图像文本进行不同程度的可见性扰动,即可将知识学习、OCR 能力高效地统一到单个学习目标中。
多模态模型在处理文档时,普遍采用两种独立的低效方法。
一方面,文档知识学习高度依赖脆弱的外部解析工具,不仅效率低下,解析错误还常常引入噪声,需要大量数据工程进行修复。
另一方面,OCR能力学习虽受益于数据增强,但过度的图像扰动又会导致文字无法辨认,反而诱发模型产生幻觉。
对于以上困难,团队提出一条核心洞察:
文档知识获取和文字识别的关键区别,仅在于图像中文字的可见度。
基于此,MiniCPM-V 4.5使用了一种统一的OCR和知识学习范式:对文档图像中的文字区域施加不同程度的损坏,利用“从损坏图像中重建原文”这一学习目标同时学习两种任务。如下图所示,通过控制损坏程度,团队创造了三种任务:
- 轻微损坏(可靠OCR训练):文字尚可辨认,模型专注于学习准确、鲁棒的文字识别。
- 中度损坏(综合推理):字符变得模糊,模型可以结合框内视觉线索和上下文进行综合推理和重建原文。
- 高度损坏(知识学习):文字被完全抹除,模型被强制依赖上下文图表和文字以及模型内部知识来重建原文,从而实现真正的文档级理解。
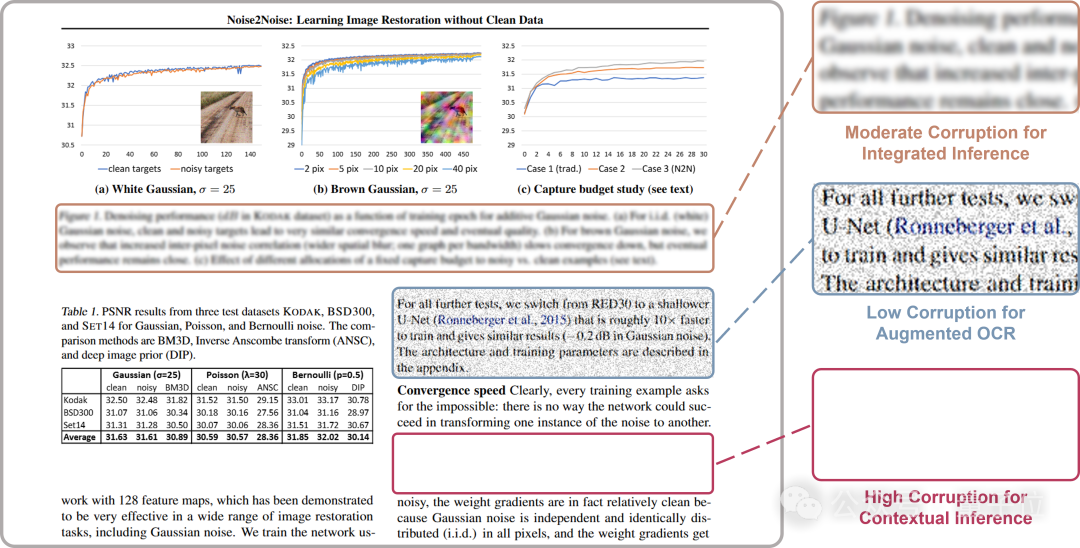
这一方法彻底摆脱了对外部解析器的依赖,杜绝了其引入的噪声和工程负担。
同时,它智能地将知识学习和OCR目标无缝融合在同一训练批次中,极大地提升了数据利用率和训练效率。
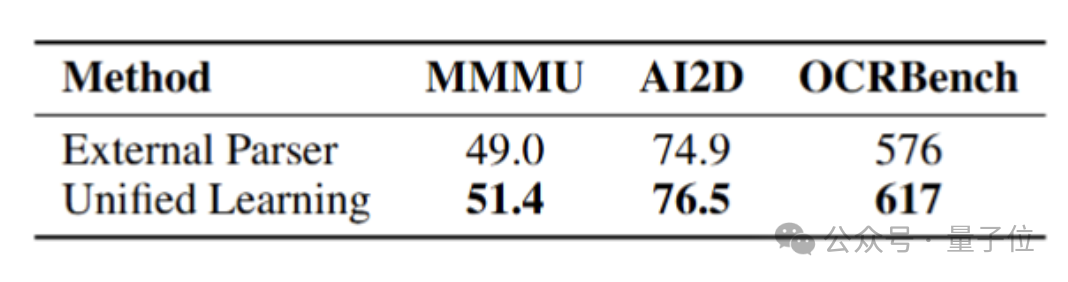
团队在轻量训练设置下对该学习范式进行了消融验证,结果说明面向文档的统一OCR和知识学习范式有效提升了模型在文档理解、知识推理、文字识别上的能力:
高效强化学习:可控混合快速/深度思考的多模态强化学习
MiniCPM-V 4.5通过混合强化学习方法,实现了快速思考和深度思考两种模式的平衡优化。
快速思考模式面向高频日常使用场景,提供高效的推理体验;深度思考模式则专注于复杂任务的深入分析。
模型通过少量高难度、高质量的推理样本进行冷启动,快速掌握深度思考所必需的反思与回溯能力。
进入强化学习阶段,两种模式被同时优化,不仅显著增强了深度思考模式的性能,更实现了两种模式间推理能力的交叉泛化。模型在节省约30%采样开销的前提下,仍能达到和仅深思考强化学习的模型相当的表现。

同时,团队引入了RLPR与RLAIF-V两项技术:
- RLPR解决了通用域问题的开放式回答(如答案表述相对复杂、含物理单位等)难以获得可靠奖励信号的痛点,从模型生成正确答案的概率中获得奖励信号(probability-based reward, PR)。
随着训练步数增加,结合PR训练相比常规训练方法的优势会逐渐扩大.
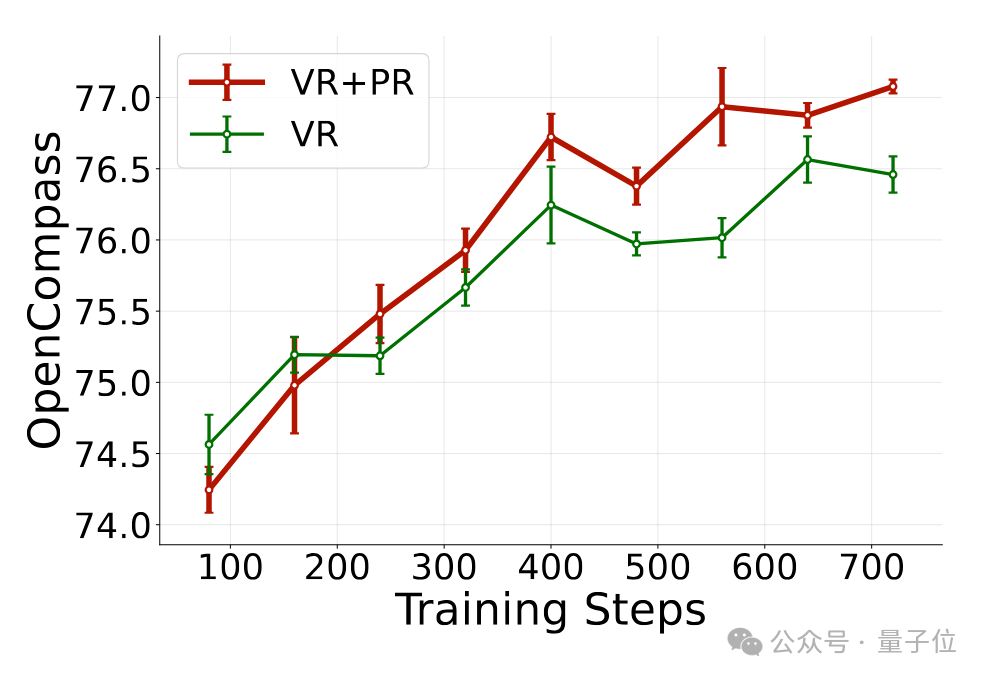
- RLAIF-V有效抑制了模型的幻觉现象,通过逐个检验模型输出答案中事实陈述的可靠度并构建偏好数据用于DPO,提升了多种多模态理解任务的可靠性。
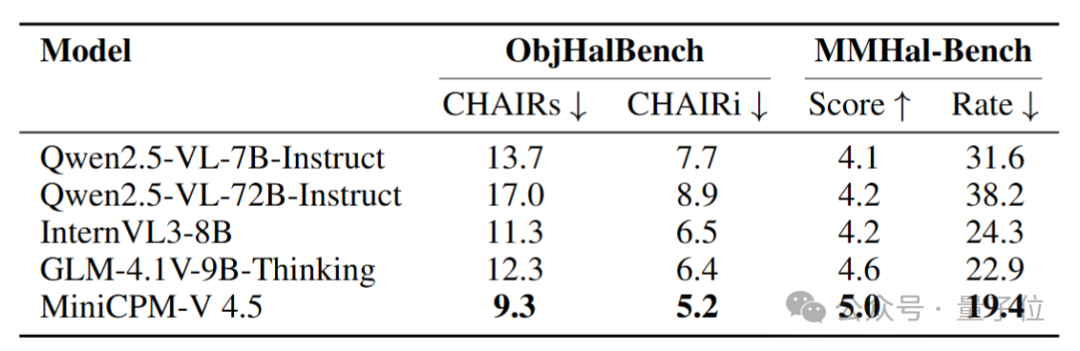
评测结果
MiniCPM-V 4.5在OpenCompass综合评测中取得了77.0的平均分。该评测涵盖了8个主流多模态基准的综合指标。
尽管仅有8B参数规模,模型在视觉语言能力上超越了GPT-4o-latest等广泛使用的专有模型,以及Qwen2.5-VL72B等强大的开源模型,成为30B参数以下性能最佳的开源多模态大模型。
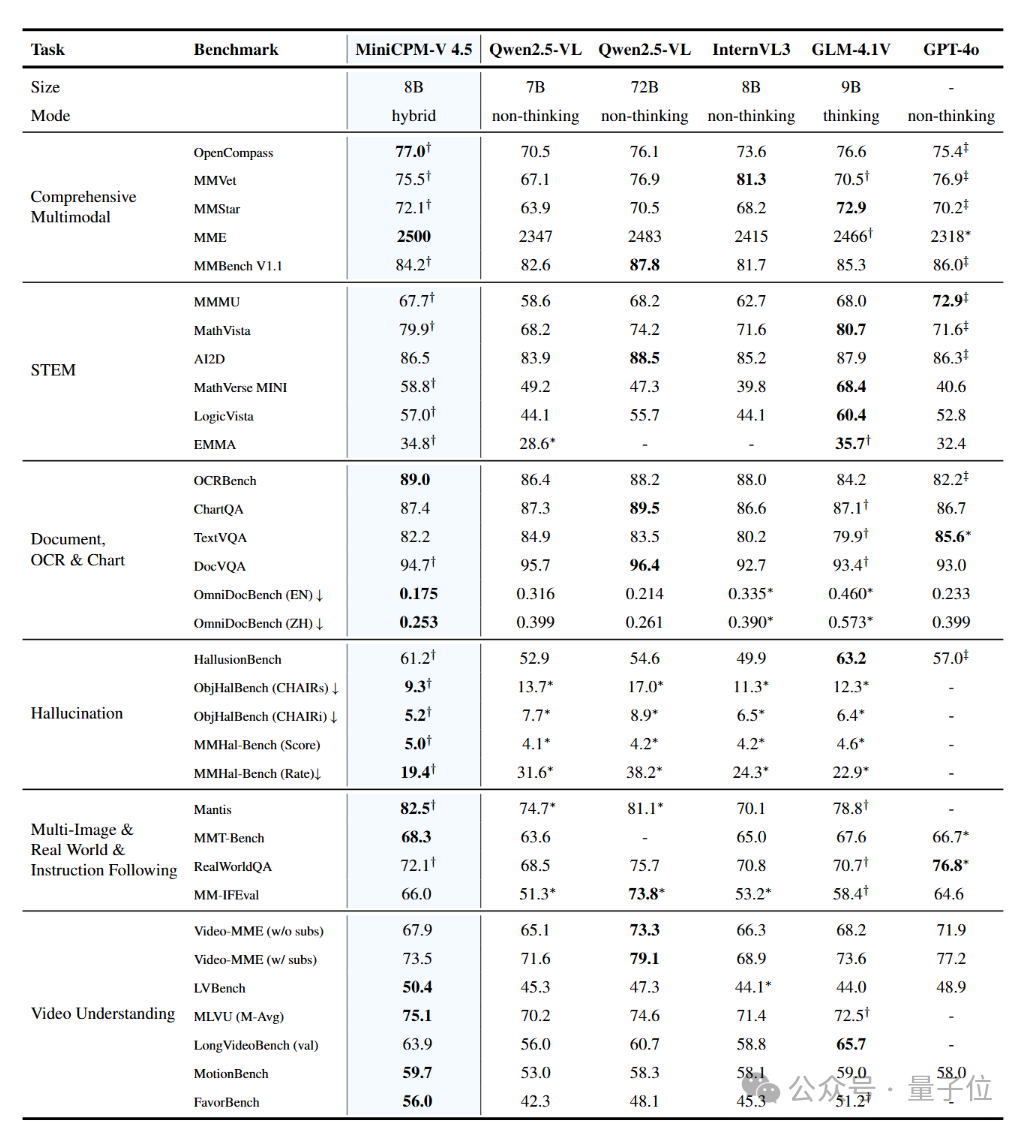
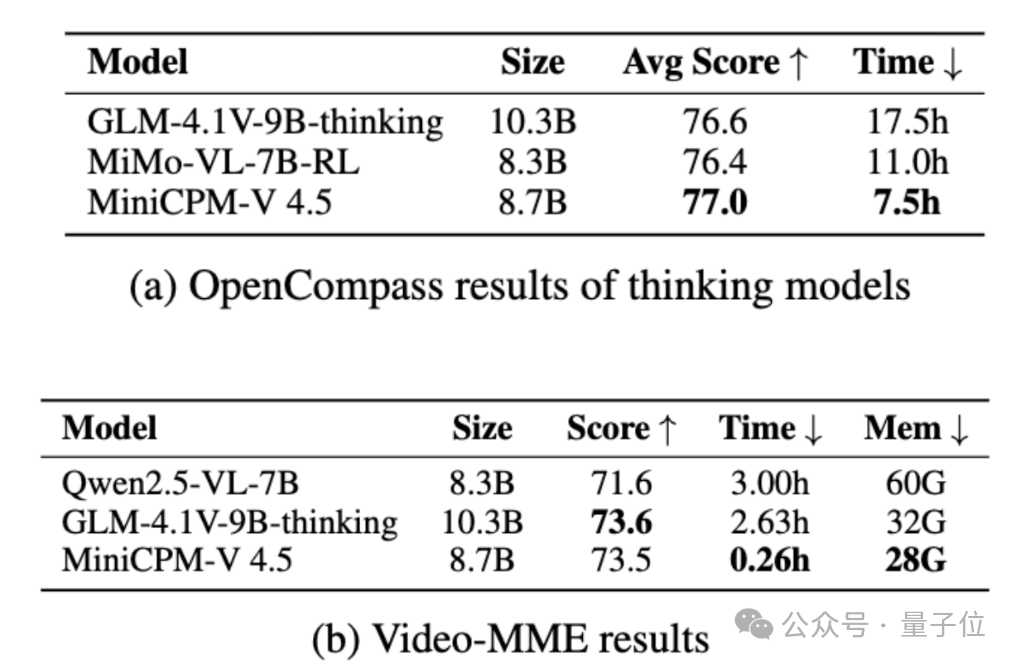
MiniCPM-V 4.5在提供SOTA级多模态表现的同时,具有最佳的推理效率和最低的推理开销。
在混合思考模式下,MiniCPM-V 4.5在推理耗时仅为同规格深度思考模型的42.9%-68.2%的同时获得了更好的OpenCompass分数。
同时,得益于高密度视频压缩技术,在覆盖短、中、长三种类型的视频理解评测集Video-MME上,MiniCPM-V 4.5时间开销(未计算模型抽帧时间)仅为同级模型的1/10。
模型实测效果展示


One more thing
作为MiniCPM-V系列的最新成果,MiniCPM-V 4.5系统性地从架构、数据和训练三大维度为解决多模态大模型的效率瓶颈提供了一条可行路径。
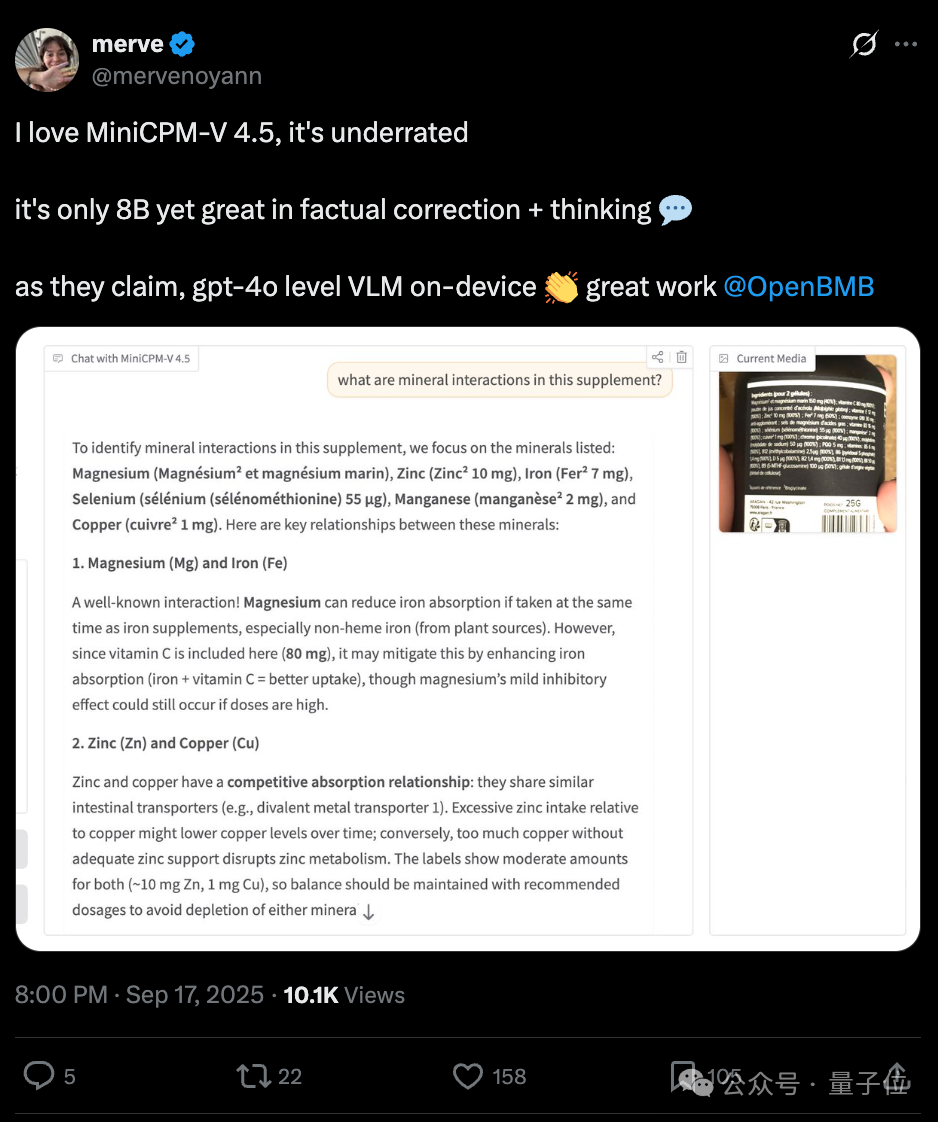
HuggingFace 大佬表示,仅有8B参数的模型也能擅长事实纠正和思考,确实值得更多的关注。
作为清华大学自然语言处理实验室和面壁智能联合开发的系列模型,MiniCPM-V和MiniCPM-o系列已经获得了广泛的学术和产业认可。
系列模型下载量超过1300万次,GitHub星标超过2万次,相关技术论文发表在国际著名期刊Nature Communications上,谷歌学术引用超过600次。
系列模型曾连续多天在Hugging Face Trending、GitHub Trending和Papers With Code Trending Research榜单排名第一,入选HuggingFace2024年度最受欢迎和下载开源模型榜单、中关村论坛年会10项重大科技成果、英特尔中国学术成就奖。
技术报告地址:https://github.com/OpenBMB/MiniCPM-V/blob/main/docs/MiniCPM_V_4_5_Technical_Report.pdf
GitHub:https://github.com/OpenBMB/MiniCPM-o
HuggingFace:https://huggingface.co/openbmb/MiniCPM-V-4_5
ModelScope:https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-4_5


