过去几年,人工智能的浪潮一次又一次刷新人们的想象:模型变得更大、算力更强、应用更广。
但在光鲜的成果背后,一个更深层的问题被不断暴露 —— AI 真的“理解”世界了吗?它能记住对话,却常常忘记语境,能生成答案,却未必明白问题的由来。人们开始意识到,智能的边界,不在算法,而在语境。
正是在这样的背景下,上交大生成式人工智能实验室(GAIR Lab)提出了一个颠覆性的观点:人工智能的本质不是算力革命,而是“上下文革命”。 他们在最新论文中,把“上下文”从语言模型的附属概念,提升为智能系统的核心结构,认为系统理解世界的方式,取决于它如何吸收、组织并重构语境。
这项研究通过回溯上下文系统的演化历史,结合大量系统实验与理论建模,提出了“上下文工程”(Context Engineering)这一全新学科框架。团队发现,从早期依赖传感器和规则的 Context 1.0,到能够跨模态理解语义的智能体 2.0,AI 的每一次跃迁,都是一次对“语境吸收力”的升级。
在参数增长趋于极限的当下,这项研究像是在为人工智能指明新的出路:当机器不再只是记住语境,而能理解并创造语境,也许,那才是真正的智能时代的开始。

语境,才是智能的真正边界
这篇论文的实验结果揭示了一个重要规律:人工智能的进步,归根结底取决于系统对“上下文”的理解和利用能力,也就是它能多好地吸收、组织和重构语境。
作者通过比较不同代的智能系统,总结出了上下文工程的发展路径。他指出,从最早依赖传感器和规则运行的系统(比如 Context Toolkit、Cooltown),到如今能理解自然语言和多模态信息的智能体(如 ChatGPT、LangChain、Letta),智能的提升,其实就是系统能处理的语境越来越复杂。
早期的系统只能根据明确输入作出反应,而现在的系统已经能通过语义推理理解人类意图,做出更自然的互动,这标志着上下文工程正式进入了 2.0 阶段。
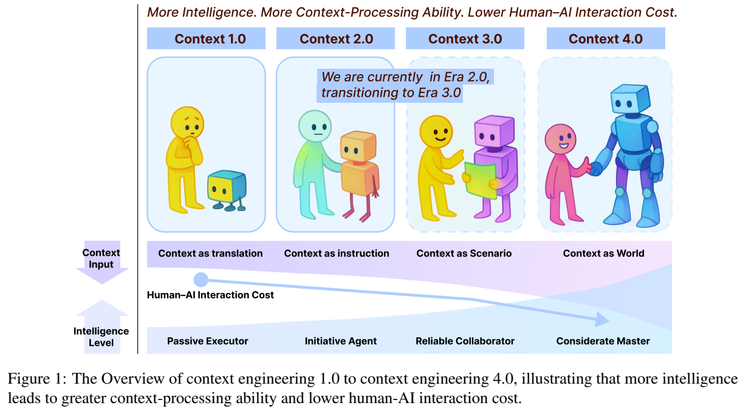
实验还进一步预测了智能的发展方向。随着系统理解语境的能力越来越强,它未来会逐步具备类似人类的思维方式,能理解社会语境甚至情感因素,最终可能进化成能主动创造语境的“超人智能”。
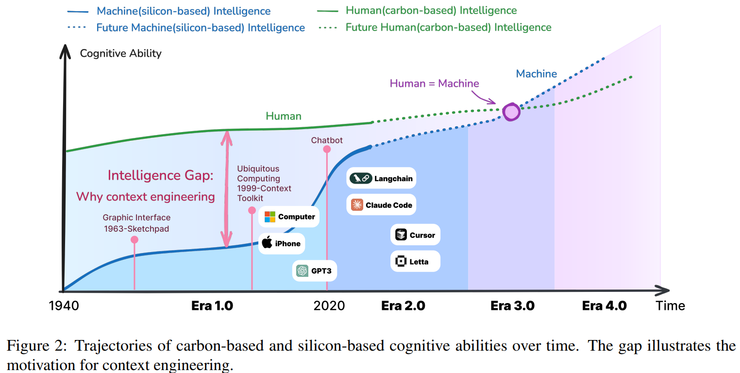
为了验证这种演化趋势,作者提出了上下文工程的函数定义:CE:(C,T)→f_context。这个定义的意义在于,它把提示工程、检索增强和记忆管理等不同方法都统一到了一个数学框架下,为上下文的工程化提供了理论基础。
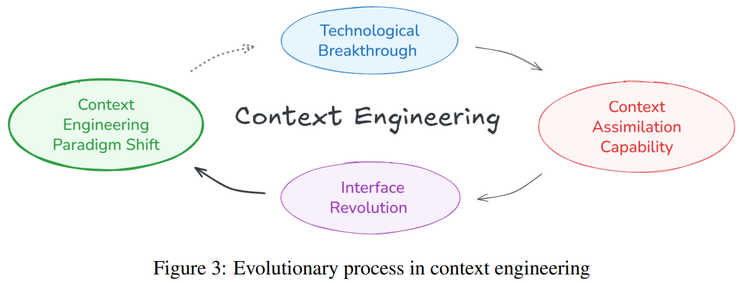
在系统对比实验中,研究发现现代智能体的上下文系统在输入容忍度、记忆层级化、多模态融合以及多智能体协作等方面都有明显进步。
值得一提的是,现在的系统不再只是简单地存储文本,而是能通过时间标记、语义压缩和层级摘要的方式构建结构化语境,不同任务或子智能体之间还能共享上下文。
实验结果表明,这种短期与长期记忆相结合的设计大大提高了系统的稳定性和扩展性,而所谓的“自烘焙”机制则通过语义压缩有效解决了超长对话带来的信息冗余和语境污染问题。
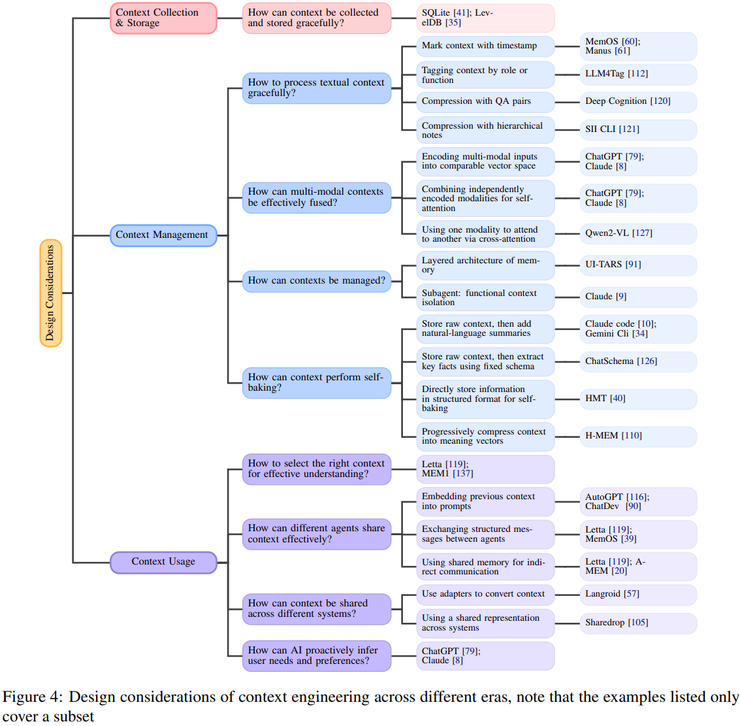
此外,检索机制的优化使系统能在语义相关性、逻辑依赖与时序一致性之间实现动态平衡,进一步增强了对用户隐性意图的捕捉能力。
实验还发现,Transformer 模型在处理长时语境时会出现注意力衰减和语义漂移等问题,这暴露出现有架构在“终身上下文”处理方面的不足。为了解决这些问题,作者提出了“Lifelong Context”的概念,认为要构建可持续、能不断进化的语境记忆系统,就必须使用新的语义压缩算法和一致性维护机制。
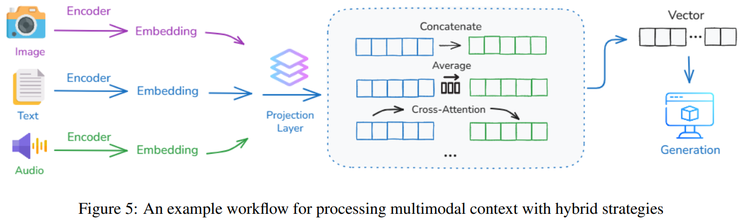
综合所有发现,论文得出的结论是:现代智能体的发展方向,正在从“被动响应”向“主动构建语境”转变。上下文工程的核心目标,就是让系统不仅能理解语境,还能组织、加工、甚至重写语境。这种能力,正是提升语言模型性能的根本,也是实现真正通用人工智能的关键。
从感知到自省
论文的实验经过大致可以分为三个阶段。研究从上下文工程的整体框架出发,目的是在大型语言模型和智能体快速发展的背景下,探索模型性能与上下文质量之间的关系。作者认为,模型越智能,就越依赖语境信息的完整性与组织方式,因此希望通过历史回顾和实证对比,建立一种系统化的上下文工程方法。
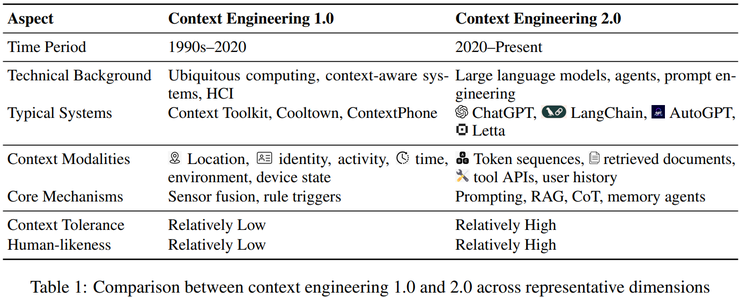
在第一阶段,研究采用历史比较的方式,分析了从 1990 年代到现在的两代上下文系统。早期的 Context 1.0 主要依赖传感器和固定规则来感知环境,属于结构化逻辑系统,而如今的 Context 2.0 已能理解自然语言,利用检索增强和长记忆机制来处理复杂语境,显著提升了理解与推理能力。
第二阶段,团队进行了系统性对比实验,选取了多个具有代表性的系统——从早期的 Context Toolkit 和 Cooltown,到现代的 ChatGPT、LangChain、Claude、Letta 等,重点比较它们在信息采集、管理和使用上的不同。实验发现,现代系统在语义压缩和上下文存储方式上都有显著改进,更擅长整合多源数据并保持语义连续。
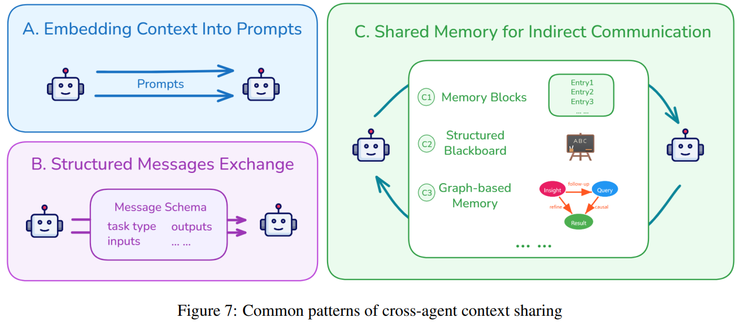
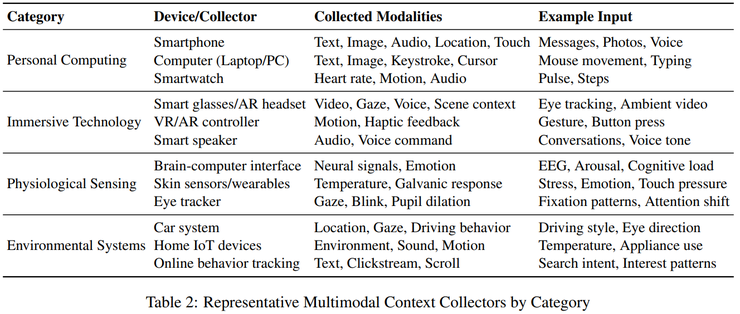
在实验中,系统通过多种设备采集数据,如手机、可穿戴设备、虚拟现实和物联网终端。在管理层面,系统建立了短期与长期记忆的层级结构,用时间标记、语义标签和摘要压缩来组织信息。而在使用层面,不同智能体能通过结构化消息共享语境,并根据语义相关性、逻辑关系和用户偏好动态筛选信息,甚至能主动推测用户意图。
最后,研究团队还进行了“持续性上下文”实验,测试系统在长期语境下的表现。结果发现,模型在长时间推理时容易出现注意力下降和语义漂移的问题。
为此,作者提出应通过语义压缩与一致性维护机制,构建一种能够长期保持稳定的记忆体系,使系统能在时间维度上保持上下文的连贯和可靠。
总体来看,这些实验构成了上下文工程的核心验证过程,证明了系统化的语境采集、管理和使用方法,能显著提升智能体的理解能力与交互一致性。
智能的下一次觉醒
整体看下来,这项研究的意义主要体现在三个方面。
首先,在理论上,它重新定义了“上下文工程”这门学科。作者第一次把它当作一门独立的工程领域来看待,并建立了一套比较完整的理论体系,把从早期的人机交互研究到如今的智能体技术都串联起来。
通过数学化的建模,他们发现人工智能的每一次进步,其实都与系统“理解和利用上下文”的能力提升有关。换句话说,智能的核心就在于能否真正读懂语境。
在工程实践上,这项研究推动了人工智能从“能感知”到“能理解”的转变,也就是从被动响应到主动协作。研究提出的“层级记忆结构”让系统能处理更长的任务和对话,还能在文本、图像、音频等不同模态之间建立统一的语义空间。
同时,通过子智能体机制和轻量级引用方式,系统在保持效率的同时也降低了出错和信息污染的风险。更重要的是,它还能根据用户的习惯和偏好进行自我学习,实现更个性化、更主动的交互体验。
最终,作者设想了一种全新的智能范式——“上下文即世界”,也就是说,未来的人工智能不只是理解人类提供的语境,而是能够主动创造新的语境,成为人类思维与社会活动的一部分。


