当大语言模型生成海量数据时,数据存储的难题也随之而来。
对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。
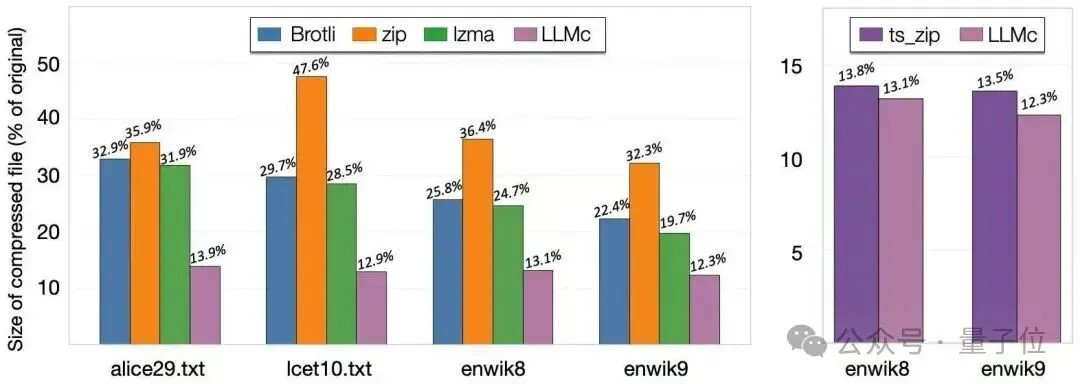
基准测试结果表明,无论是在维基百科、小说文本还是科学摘要等多种数据集上,LLMc的压缩率都优于传统的压缩工具(如ZIP和LZMA)。同时,与其他以LLM为基础的闭源压缩系统相比,LLMc也表现出同等甚至更优的性能。
值得一提的是,该项目已经开源,主要作者是来自上海交通大学ACM班的本科生Yi Pan,目前正在华盛顿大学实习。
LLMc的压缩机制
LLMc的灵感来源于实验室一年前的一次内部讨论。当时,研究者们面临一个核心挑战:LLM推理中涉及的内核操作具有高度的非确定性,这使得精确、可复现的压缩和解压变得困难。
但随着业界在确定性LLM推理方面取得突破,这一问题迎刃而解,也为新引擎的诞生铺平了道路。研究团队顺势快速构建了LLMc的原型,并成功证明用LLM进行高效压缩的可行性。
LLM与数据压缩之间的联系根植于信息论的基本原理。
香农的信源编码定理(source coding theorem)指出,一个符号的最优编码长度与其负对数似然(negative log-likelihood)成正比。简而言之,一个事件的概率越高,编码它所需的信息量就越少。
由于LLM的核心任务是预测下一个词元(token),一个优秀的LLM能够为真实序列中的下一个词元赋予极高的概率。
这意味着,LLM本质上就是一个强大的概率预测引擎,而这正是实现高效压缩的关键。LLMc正是利用了这一原理,将自然语言的高维分布转换为结构化的概率信息,从而实现前所未有的压缩效果。

LLMc的核心思想是一种名为“基于排序的编码”(rank-based encoding)的巧妙方法。
在压缩过程中,LLM会根据当前上下文预测下一个可能出现的词元,并生成一个完整的概率分布列表。在大多数情况下,真实出现的那个词元总是在这个预测列表的前几位。
LLMc并不直接存储词元本身(例如其ID),而是存储该词元在概率排序列表中的“排名”(rank)。这些排名通常是非常小的整数,因此占用的存储空间极小。
在解压时,系统使用完全相同的LLM和上下文来重现当时的概率分布。然后,它只需读取之前存储的“排名”,就能准确地从列表中选择对应的词元,从而无损地恢复原始文本。
在这个过程中,LLM本身就像一个压缩器和解压器之间共享的、容量巨大的“密码本”或参考系统。
挑战与局限性
尽管LLMc取得了突破性的成果,但研究团队也指出了当前版本存在的一些挑战和局限性。
效率问题:LLM推理的计算复杂度与序列长度成二次方关系,且长序列推理受到内存带宽的限制。为了缓解这一问题,LLMc采用了分块处理文本的策略,以提高GPU利用率并降低计算开销。
吞吐量:由于严重依赖大规模模型推理,LLMc目前的处理速度远低于传统压缩算法。
数值稳定性:为了保证解压过程的确定性,系统需要使用特殊的内核(batch_invariant_ops),并对词元排名进行整数编码,而非直接使用对数概率。
应用范围:当前实现主要针对自然语言。如何将其扩展到图像、视频或二进制数据等其他模态,是未来值得探索的方向。


