编辑 | 云昭
出品 | 51CTO技术栈(微信号:blog51cto)
在过去两年,大语言模型几乎定义了整个 AI 发展的节奏。但有个问题一直没变:模型再强,也不会自己学习。每次要让它掌握新知识,都必须人工投喂数据、重新训练。
MIT 的研究团队最近在 arXiv 上发布了一篇论文,提出并实测了一个框架 —— SEAL(Self-Adapting Language Models,自适应语言模型)。
 图片
图片
炸裂之处在于,它能让语言模型自己生成微调数据与更新指令,自行优化自己的权重。
这还没完,一位X用户还爆料这篇文章的部分作者,已经加入了OpenAI团队,暗示了未来的GPT-6的走向:冻结权重时代结束了,如果GPT-6真的融合了这套机制,一个随着世界变化而持续自我进化的模型,真的要来了!
部分 SEAL 论文的研究者目前已加入 OpenAI。这绝非巧合。
SEAL 的架构让模型具备以下能力:
• 从新数据中实时学习
• 自我修复退化的知识
• 在多次会话之间形成持久的“记忆”
如果 GPT-6 真的整合了这些机制,它将不只是“使用信息”,而是会吸收信息。
一个能随着世界变化而自我进化的模型,一个每天都在变得更好的系统。
这可能意味着——持续自学习 AI 的诞生,也是“冻结权重时代”的终结。
欢迎来到下一个时代。
 图片
图片
不过小编在此声明:此为推测,只代表一种可能。最终还是要看OpenAI如何出招。
论文地址:https://arxiv.org/abs/2506.10943
代码也在计划开源中:https://github.com/Continual-Intelligence
先来看看这套框架究竟厉害在哪里?
强如GPT-5,依旧是冻结模型
可能大家有一种错觉,就是很多许多人误以为GPT-5已实现连续学习,但事实并非如此。一位博主透露,自己每个月都需要为此解释2-3次,来澄清:当前模型权重都是静态的,无法实时更新。
 图片
图片
它们能理解世界,但无法真正“更新自己”。如果要让大模型每次适配新任务,都需要人工再微调一次。
而 SEAL 的目标,就是是让模型拥有持续吸收与整合知识的能力。
SEAL 框架厉害之处:让模型自我编辑指令
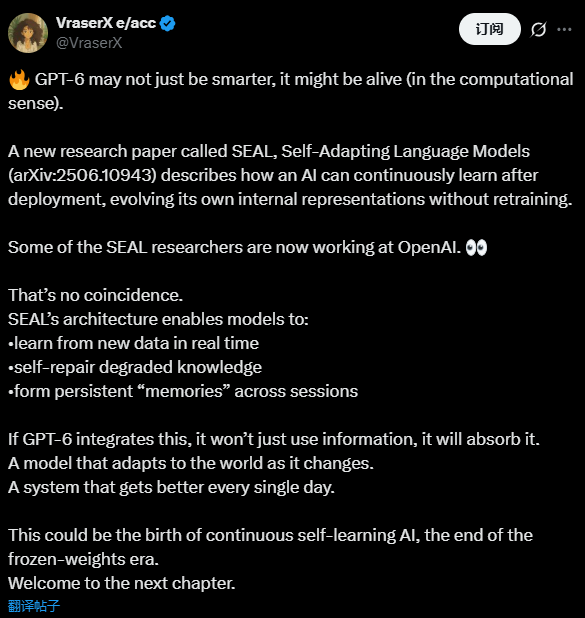
SEAL 的核心是「自我编辑(self-edit)」。
 图片
图片
给定新的输入,模型会产生自编辑——这一生成过程可能以不同的方式重构信息、指定优化超参数,或调用数据增强和基于梯度的更新工具。通过监督微调 (SFT),这些自编辑会产生持续的权重更新,从而实现持久的自适应。
简单讲,当模型遇到新信息时,它会自己生成一段“训练指令”,告诉自己:
- 如何重组信息;
- 用哪些超参数优化;
- 是否生成新的合成样本。
这些自我编辑会触发一次监督微调(SFT),模型再根据任务表现,强化成功的编辑策略。(没错,还是通过强化学习的方法生成这些指令,并且以更新后的模型表现作为奖励信号。)
 图片
图片
SEAL 框架概览:在每一次强化学习(RL)的外层循环中,模型会生成候选的“自我编辑”——也就是关于如何更新权重的指令。随后,模型根据这些指令执行相应的权重更新,在下游任务上评估性能,并利用得到的奖励信号来优化自我编辑的生成策略。
整个过程由一种轻量级强化学习算法 ReST-EM 控制,形成「生成 → 更新 → 评估 → 强化」的自学习闭环。
实验结果:超过GPT4.1合成数据训练、小样本学习任务成功率高达72%
而且,这套框架已经成功在实验任务中得到有效验证。团队进行了两类任务的实验。
1. 知识整合:让模型从一段新文本中吸收事实性信息,使其在后续问答中无需原始文本也能正确回答相关问题。
 图片
图片
2. 小样本学习(Few-Shot Learning):在 ARC 基准测试的子集上,模型需从极少量示例中泛化,通过自主生成数据增强与训练配置来解决抽象推理问题。
 图片
图片
这两项实验任务表明,SEAL框架确实取得了最佳性能表现。
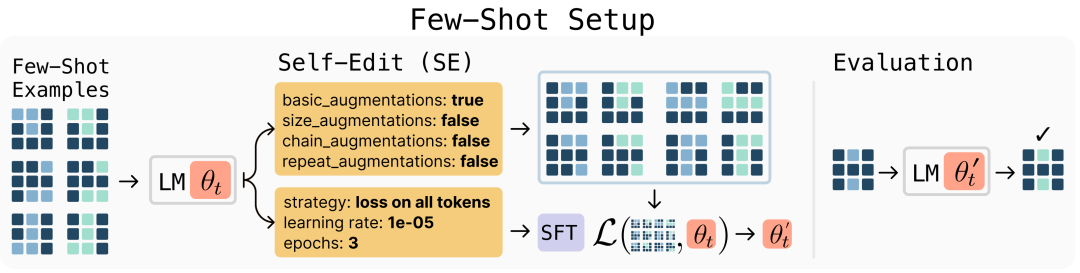
- 知识整合:两轮自学后,准确率从 32.7% → 47.0%,甚至超过了 GPT-4.1 合成数据微调的模型。
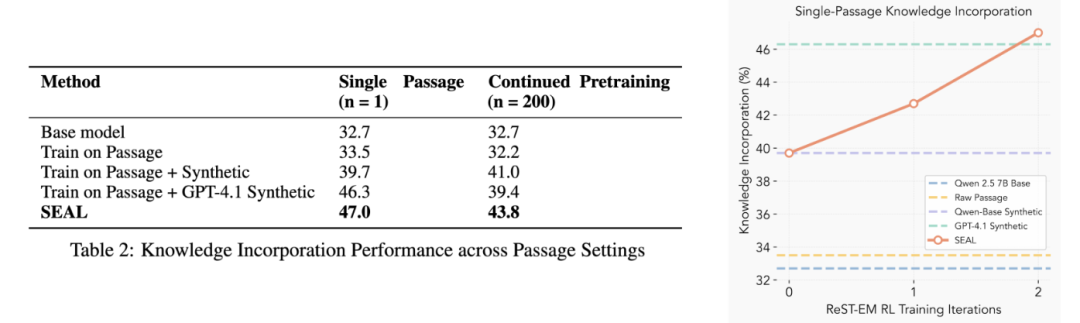 图片
图片
- 小样本学习:从 0% → 72.5%,模型学会自己选增强方式和超参。
 图片
图片
这个任务的对比最为明显。无自我编辑:0% 成功率,而未训练自编辑:20%,而SEAL 完整训练后:成功率竟然高达 72.5%。
很显然,这套“自我编辑指令”的框架,奇迹般地让模型真的学会了如何自我改进。
局限:灾难性遗忘
新成果往往伴生着新问题。
论文中,团队发现一个了一个棘手的问题,即反复自我编辑会导致灾难性遗忘:学新任务的同时,旧知识可能被覆盖。对此,研究者提出几种潜在方案,如经验回放、受限更新、表征叠加等。
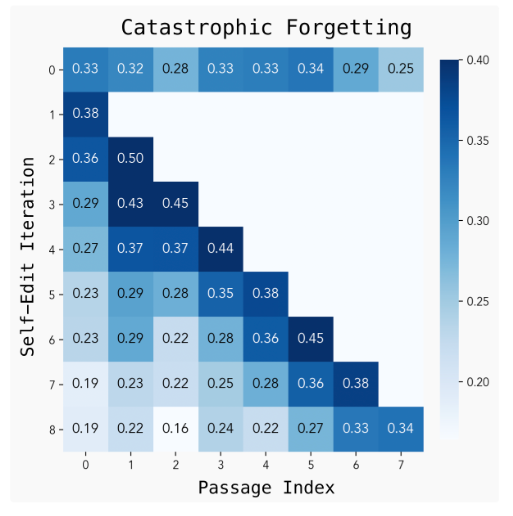 图片
图片
下一步:自我演化智能体
MIT 团队希望未来的模型能学会判断:
“什么时候该更新,什么时候不该动。”
也就是说,模型会在推理中决定是否执行自我编辑,把临时推理转化为持久能力,为“会自己演化的智能体”铺路。
写在最后:GPT-6大概率会是什么样?
大家希望AI可以自我进化,可以说是一个很古老的愿望了。而本文中,MIT的SEAL框架可以说让这个愿望又向前推进了一步:模型可以自行根据外界变化自我编辑SFT指令,想想都有点恐怖。
模型直接从“被训练的工具”化身“能自我训练的系统”。怎么说呢?这是要抢“AI工程师”的饭碗吗?
那么,OpenAI下一款的GPT-6什么进度呢?
按照OpenAI的发布节奏来看,大概率GPT-6至少也得明年一季度了。(今年夏天刚发的GPT-5。大版本的发布至少半年起。)
虽然,我们还不能确定,OpenAI最终会如何定义GPT-6的走向,但按照去年奥特曼的5级规划来看,小编认为有两种可能。
保守的结果,则是L3级别。即自主智能体。
AI 不只是回答问题,而是能在指令下自主行动(agent),处理一系列任务,可以调整策略、寻求帮助、完成较复杂/跨步骤的工作
激进点的话,GPT-6 可能的主打方向,就是奥特曼最近在采访中时不时提到的:AI创造新知识。即“L4 Innovators”,创新者/发明者的角色。创新与创造性输出,是这一阶段的典型特征:
在没有人类持续监督或指导的情况下,能提出新想法、发明新事物、解决未知领域的问题,能超出已有知识/训练数据的范畴。
而这种超出已有知识/训练数据的创造与创新已经跟本文讨论的“自我演进”的SEAL框架了。
总之,拭目以待吧。AI全面超越人类的未来已经不远了!


