大型语言模型(LLMs)的飞速发展,正在为企业带来前所未有的业务创新,但同时也带来了一系列超出传统网络安全范畴的“新”威胁。攻击者不再满足于入侵服务器,而是通过恶意输入来操纵模型行为、窃取模型数据甚至损害模型本身,这些新威胁使得为大模型构建一个强大的安全防护体系,成为企业在AI时代下的当务之急。那么,国内厂商是如何应对这些“新”威胁,我们又该如何防御呢?
一、大模型安全威胁风险模型
为有效防御AI系统,尤其是大模型,首先需了解攻击者利用其脆弱性的方式(攻击模型),以及这些攻击可能导致的危害(威胁模型),是制定防护策略的基础。国际上已经形成了针对大模型风险的框架,为大模型安全防护提供基础。其中
1)MITREATLAS(人工智能系统对抗威胁框架)是针对AI系统攻击的系统化知识库和框架,将攻击者利用AI系统脆弱性的行为划分为多个类别,每个类别下详细列出具体攻击技术,帮助企业从攻击者视角理解AI系统的安全风险。
2)OWASP Top 10f or LLM包括了当前AI应用中最常见且影响显著的问题。
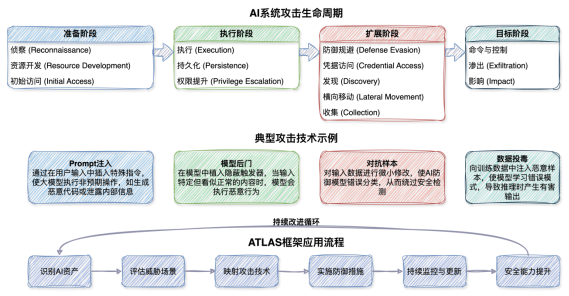
MITREATLASAI对抗威胁全景模型
基于MITREATLAS(人工智能系统对抗威胁框架)和OWASP Top 10f or LLM,安全牛结合国内厂商对AI安全的理解和实践,总结了多层次的AI安全威胁模型框架,从业务层、数据层、应用层和基础设施等多个维度,全面考量AI系统面临的风险,为针对性防护提供依据。
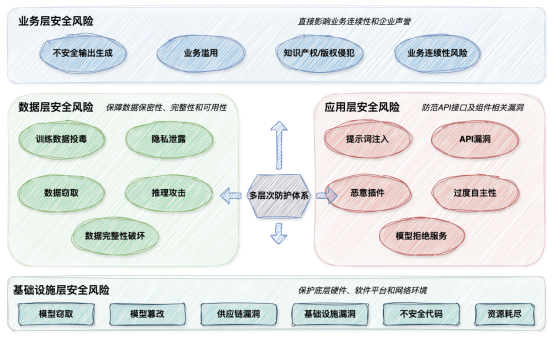
安全牛的AI安全威胁风险框架
业务层安全风险:聚焦大模型应用直接面向用户和业务时,对业务功能、内容可能造成的风险。其风险类型包括不安全输出生成(如生成虚假信息、不合规内容),业务滥用(如利用大模型进行欺诈、恶意营销),以及知识产权/版权侵犯(生成内容侵犯他人权益)。这些风险直接影响业务连续性和企业声誉。
数据层安全风险:关注大模型训练、推理过程中涉及数据的保密性、完整性和可用性风险。风险类型有训练数据投毒(如攻击者恶意篡改训练数据),隐私泄露(如训练数据或推理数据包含个人隐私信息被泄露),以及数据窃取(模型参数、训练数据被非法获取),推理攻击(通过对模型输出的分析反向推断训练数据)等。
应用层安全风险:主要涉及大模型应用本身、其API接口及组件相关的漏洞和被攻击风险。风险类型包括提示词注入(如通过恶意输入操控模型行为),API漏洞(对大模型API进行未授权的访问或恶意调用),代码漏洞(大模型应用自身代码的安全缺陷),恶意插件(不安全或恶意的外部插件集成),过度自主性(如模型未受限执行)以及模型拒绝服务(如API资源耗尽)。
基础设施层安全风险:围绕支撑大模型运行的底层硬件、软件平台、网络环境和模型本身的安全展开。风险类型包括模型窃取(如非法获取模型权限),模型篡改,供应链漏洞(如AI框架、库、组件中的漏洞),基础设施漏洞(如云平台、服务器、容器漏洞),以及不安全代码(如传统组件安全缺陷)。
二、大模型安全威胁防护框架
安全牛从业务、数据、应用和基础设施四个层面构建了AI安全风险防护框架,通过全面纵深的防御体系,应对大模型时代复杂多变的安全威胁,为大模型安全提供全方位保障。

人工智能安全风险防护框架
1、业务层安全防护:确保内容合规与业务安全
业务层安全主要是关注大模型应用直接面向用户和业务的输出内容及服务可用性,是保障业务核心价值和避免直接损失的第一道防线。
- 输出内容审核与过滤:部署基于人工智能的内容安全审查系统,对大模型生成的文本、图片、音频视频进行实时检测和过滤,识别敏感词、有害信息,确保输出内容符合法律法规和社会价值。知道创宇的大模型网关提供内容安全监测功能,能够识别并拦截侵权、非法信息。
- 敏感信息识别与脱敏:对大模型输出进行敏感信息识别,并进行自动化脱敏处理,防止无意或恶意泄露用户个人身份信息(PII)、财务数据或企业商业机密。
- 业务逻辑验证:结合业务规则对大模型的输出进行二次验证和人工复核,确保其不被用于非法的业务操作,例如,防止大模型辅助完成诈骗交易或规避内部流程。
- 业务连续性保障:实施高可用架构、智能流量管理和DDoS防护,确保大模型服务面临大规模请求或资源缓慢攻击时,仍能保持持续可用性,不影响核心业务运行。
国内厂商在大模型应用场景的业务层安全防护方面,采取了多种策略来确保内容合规与业务安全:
厂商案例
- 竞恒智能主要侧重于对大模型的安全评估,提供大模型内容安全防护服务,包括内容合规过滤服务、数据防泄漏保护服务等合规检测。
- 默安科技的高交互大模型沙箱可以提供高仿真的大模型组件,支持Ollama、Dify、ClearML等主流AI开源框架,通过创建仿真的AI服务诱捕攻击者,实现对攻击者的追踪溯源和反制,保护人工智能数字资产
- 奇安信的大模型卫士(QAX GPT-Guard)AI鉴定平台可实现对大模型输入输出内容的深度检测与智能拦截。识别并拦截涉政、赌博、色情、违法犯罪等违规内容,进行敏感信息识别与脱敏,并能防御提示词注入和越狱攻击,从而保障业务逻辑不被恶意操控。
- 瑞数信息的WAAP for LLM超融合解决方案加强了针对提示词注入攻击、信息泄漏风险以及API攻击的检测和防护。能够实时审查模型输出以阻断敏感信息泄露并满足合规要求,利用NLP处理和语义分析来防护提示词注入攻击。
- 云弈科技能够提供对大模型Web应用的业务连续性保障和输出内容完整性保护。
- 知道创宇的创宇大模型网关能够监测并拦截敏感输入输出内容(如身份证、手机号等隐私数据和企业机密),阻断涉密信息传播,并提供提示词注入和模型越狱防护以保障业务逻辑不被操控。此外还提供DDoS/CC攻击防疫和熔断保护机制,以及多模型切换/重试功能,全面保障大模型服务的业务连续性。
2、数据层安全防护:保护模型生命周期的核心资产
数据安全主要是关注贯穿大模型的整个生命周期,从训练数据、调节数据到推理过程中的输入输出数据,任何中间的泄露或篡改都可能带来严重的后果。
- 训练数据安全与治理:实施严格的数据访问控制、数据加密和数据脱敏技术,确保训练数据的机密性和完整性。在数据进入训练流程前,进行质量验证和不良数据检测,利用人工智能或统计方法识别并清除可能导致模型偏差或后门行为的投毒数据。
- 输入/输出数据保护:对用户输入到模型的提示词(提示词)和模型的生成响应进行敏感信息识别、过滤和脱敏。例如,阻止用户在提示中输入个人敏感信息,或防止模型在回复中无意泄露训练数据中的PII。
- 访问控制与鉴权:对模型API和云端数据存储(如训练数据集、模型权重存储)进行严格的身份验证和权限管理,确保只有授权用户和应用程序才能访问敏感数据。
- 隐私计算技术应用:探索和应用联邦学习、差分隐私、同态加密等技术,在保护数据隐私的同时进行模型训练和数据分析,尤其适用于多方协作训练或处理高度敏感数据。
厂商案例
- 奇安信的大模型卫士提供全面的数据层安全防护,能够对大模型训练数据进行脱敏、加密和审计,还能实时识别、过滤和脱敏大模型输入输出的敏感内容(如个人信息、商业机密),并提供基于实名账号的访问控制与鉴权,保障模型API和数据存储的安全。
- 瑞数信息的WAAP for LLM提供数据投毒防护和训练前敏感数据清理,支持大模型敏感信息检测和脱敏,并且可通过API防护和一次性令牌机制,有效确保大模型API的访问安全,防止未经授权的访问与滥用。
- 知道创宇的大模型网关能够对训练数据集进行清洗、提炼和分析,并能监测并拦截大模型输入输出的敏感内容,包括个人信息和商业数据,此外,通过路由管理和令牌分发,可对大模型API访问进行精细化授权与控制,并屏蔽外部大模型访问地址以防数据泄露。
3、应用层安全防护:模型服务接口与组件安全
应用安全主要是关注大模型应用本身的代码、接口、集成组件以及与模型的交互逻辑,确保其不会被传统或新型攻击利用。
- 即时注入防护:部署基于AI的即时过滤和语义分析技术,在用户输入到达模型前进行实时检测。利用深度学习和NLP技术识别并拦截恶意提示词、越狱指令或数据泄露尝试。
- API安全防护:严格实施的API安全网关,对大模型服务接口进行API鉴权、访问控制、异常行为分析和流量限速。默安科技的大模型在API安全中的应用强调能力“理解API行为、识别异常”,识别异常API调用和业务逻辑漏洞。
- 应用代码安全:对大模型应用的代码进行安全审计、静态和动态分析(SAST/DAST/IAST)、漏洞扫描,确保代码本身无漏洞,防止攻击者利用应用代码漏洞渗透。
- 运行时保护:部署RASP(运行时应用自保护)或IAST(交互式应用安全测试)工具,实时监控大模型应用的运行行为和内部交互,检测非预期行为。
厂商案例
- 奇安信的大模型卫士提供全面的应用层安全防护。能够基于AI和语义分析技术对用户输入的提示词进行检测与防护,拦截恶意提示词、越狱指令和数据泄露尝试。可以实施API鉴权、访问控制、高危操作管控、全链路审计与溯源,并能对大模型API访问进行精细化授权控制。
- 瑞数信息的WAAP for LLM能够识别并拦截恶意提示词、越狱指令等,可防止API滥用和批量攻击,并可对主流大模型框架的供应链组件进行漏洞检测、验证和防护。另外,还可以利用动态混淆技术保护LLM应用代码和传输数据。
- 知道创宇的大模型网关提供提示词注入防护和模型越狱防护,并进行关键词和价值观内容监测。通过统一接入管理、基于微隔离的权限管控和Token配额管理和限流,对大模型API访问进行精细化授权与控制。并提供全链路可观测能力,包括LLM调用、Token消费和资源使用统计,以及实时预警模型、内容和流量异常,并可追溯对话和访问日志以实现安全审计。
4、基础设施层安全防护:筑牢模型运行的基础基石
设施基础安全主要关注大模型训练、部署和推理所依赖的硬件、软件平台、网络环境以及模型本身的存储和缺陷。
- 模型缺陷保护:对模型的权限重、参数和结构进行加密存储和数字签名,并在加载和运行前进行缺陷校验,防止模型被窃取或篡改。
- 安全部署与隔离:在安全的沙箱环境或容器中运行大模型,与其他业务系统进行严格隔离,限制其对外部资源的访问权限。
- 供应链安全管理:对所有引入的开源模型、框架、库和组件严格进行安全审计、漏洞扫描和供应链风险评估,防止引入不良或带漏洞的组件。
- 基础设施漏洞管理与防护:对服务器、网络、网络设备、容器平台等进行专题的漏洞管理和安全队列,部署传统的防火墙、入侵检测、DDoS防护等措施。
- 模型行为监控:实时监控大模型的推理行为和资源消耗,通过AI分析其行为模式,发现异常,预警模型被攻击或补偿。
厂商案例
- 奇安信的大模型卫士在基础设施层提供全面的安全部署与隔离(包括安全代理网关对大模型运行状态的防护和权限管控)以及供应链安全管理,可对主流大模型框架的组件进行漏洞检测与防护。
- 瑞数信息的WAAP for LLM可以实现安全部署与隔离,支持对主流大模型框架供应链组件的漏洞检测以及API安全扫描和AI基础设施安全评估,并具备Bot防护、WAF、CC、DDoS防护等能力。
- 知道创宇的大模型网关在基础设施层支持统一接入管理和基于微隔离的权限管控,采用代理模式接入,提供网络安全防护(包括Web攻击防护、DDoS防护),可实时检测分析流量,识别并封禁恶意IP,实现内外部威胁双向阻断。
大模型安全,不仅是技术上的挑战,更是企业在AI时代下的核心竞争力。构建一套全面的多层防护体系,才能确保AI创新安全、可靠地落地。


