编辑 | 云昭
复刻 ChatGPT 有多难?
商业层面看,很难。但对于众多的开发者、甚至实验室的研究生而言,从今天起,可能就要有标准答案了。
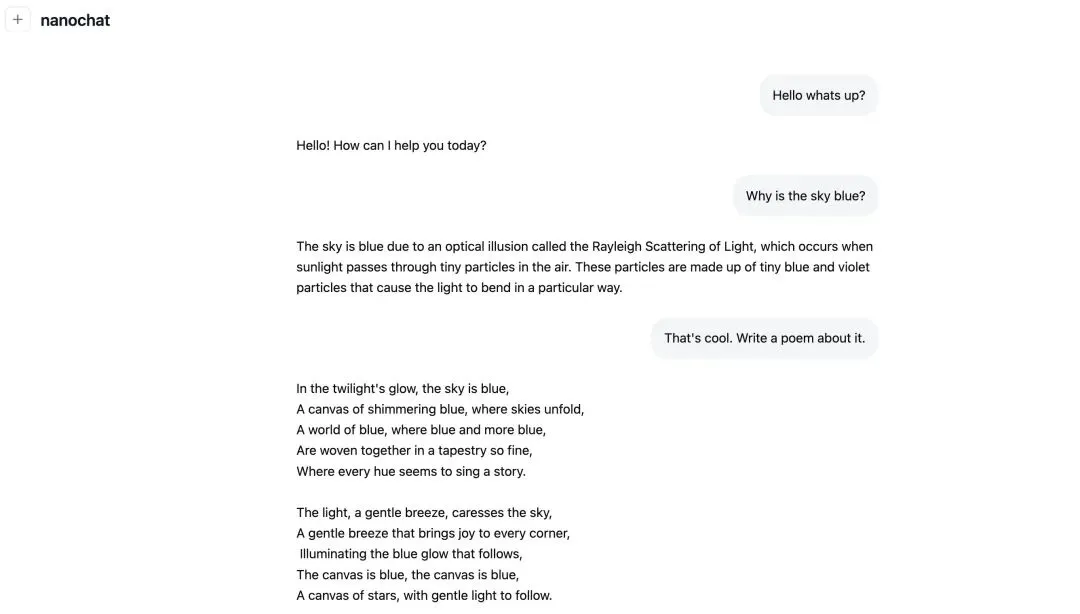
100美元,就能得到一个陪“幼儿园朋友”聊天,能写诗、讲故事,回答“天空为什么是蓝的”简单问题的模型。
300美元,就能让你得到一个可以超过GPT-2的模型:翻译、完形填空、阅读理解都可以处理。
800美元,理解和推理能力就可以做到GPT-3 Small的水准;
1000美元左右,这个模型就已经可以解决简单的数学和代码问题以及多项选择题了。(接近GPT4水平)
就在今天,知名大神Karpathy在X上宣布自己的新作:NanoChat!
 图片
图片
Karpathy:自己写的最疯狂项目之一
顾名思义,这个新项目炸裂之处,就在于他是一个类似 ChatGPT 的 LLM 的全栈实现。
 图像
图像
据卡神的在Github上的介绍,这套框架运行上,你只需要8个H100节点,关键在于,它的依懒性极低,安装非常简单。就连卡神自己都忍不住称“这是我写过的最疯狂、最放飞自我的项目之一!”
与我之前类似的代码库 nanoGPT(仅涵盖预训练)不同,nanochat 是一个极简的、从零开始的全栈训练/推理流程,它基于一个单一且依赖性极低的代码库,是一个简单的 ChatGPT 克隆版本。
你只需启动一个云 GPU 设备,运行一个脚本,只需 4 小时,就可以在类似 ChatGPT 的 Web UI 中与你的 LLM 进行交流。
为什么说疯狂呢?不仅仅是因为这个“100美元就可以买到一个最好的LLM模型”这个想法疯狂,更关键的是,这个想法在实验过程中得到了验证。
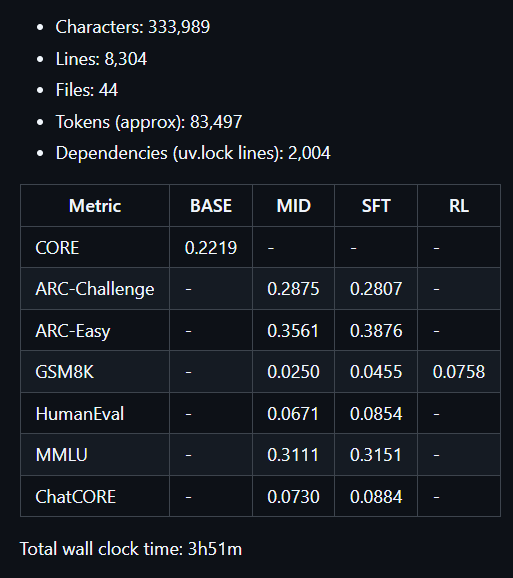
训练不到4个小时,8304行代码,只有44个文件,却击败了上亿参数规模的GPT-2,甚至在部分评估集上以微弱优势超过了GPT-4(预训练分词器的评估实验)。
 图片
图片
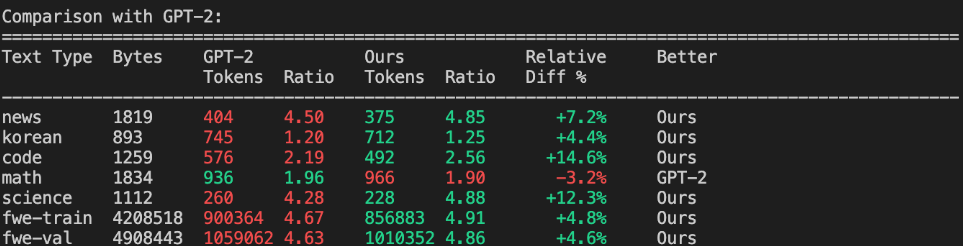
比如,在训练分词器方面,卡神实现了约 4.8 的压缩比(这意味着平均 4.8 个原文字符变成 1 个 token)。此外,还卡神将这个分词器与 GPT-2 和 GPT-4 分词器进行比较。与 GPT-2(拥有 50257 个 token)相比,NanoChat的分词器在文本压缩方面全面优于 GPT-2,而后者则在数学部分略胜一筹:
 图片
图片
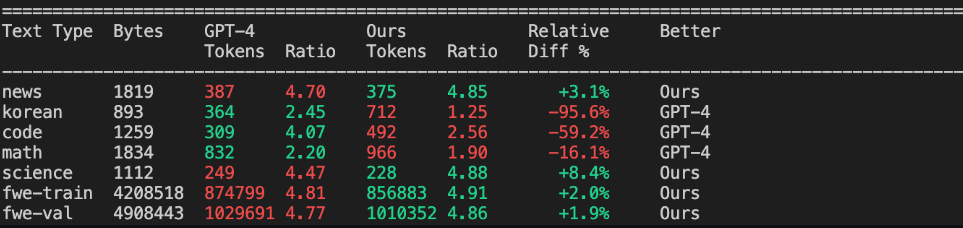
与GPT-4的分词器相比,NanoChat也有惊喜!
尽管我们在 fineweb 上的词汇量较小,但我们实际上还是以一点点优势击败了 GPT-4,因为那是我们实际训练的数据集,所以我们的标记器非常匹配该文档分布(例如,我们可能在压缩英语方面具有优势)。
 图片
图片
Github地址:https://github.com/karpathy/nanochat
讨论地址:https://github.com/karpathy/nanochat/discussions/1
价值太高!连OpenAI背后训练GPT的动作的曝出来了
大家之所以对于NanoChat项目呼声如此之高。
除了上面提到的成本便宜,还有一点就是极大地降低了大家认知ChatGPT底层原理的门槛。
根据卡神在项目自述文件的描述,整个项目的训练过程、使用到的技术都和OpenAI训练ChatGPT的方法基本相同。
那么,这8304行代码究竟是如何来复刻ChatGPT的?
- 预训练阶段,使用全新的Rust实现训练分词器;卡神特别提到,在FineWeb上对TransformerLLM进行预训练,评估多个指标下的CORE分数;
- 中期训练阶段,卡神在来自SmolTalk的用户-助手对话、多项选择题、工具使用数据上进行中期训练;
- 接下来是SFT阶段,在世界知识多项选择题(ARC-E/C、MMLU)、数学(GSM8K)、代码(HumanEval)上评估聊天模型
- 然后是训练的最后一个阶段,使用「GRPO」在GSM8K上对模型进行强化学习微调(RL)
- 推理方面,卡神选择在带有KV缓存的引擎中实现高效推理,只需要简单的prefill/decode,tool-use(在轻量级沙箱中的Python解释器),通过CLI或类ChatGPT的网页界面与其交互。
- 撰写一份单一的Markdown成绩单,总结并将整个过程游戏化。
最后一个酷似ChatGPT的Mini高级应用就跃然眼前了!
 图片
图片
为什么可以训练如此之快?AI老鸟总结卡神的Trick
当然,成本能够如此之低,自然还是卡神的智慧。在上面各个环节都设计得非常巧妙。
比如你去从文件结构去看,会发现比较有意思的是:有 data loader、data set engine,还有个叫 GPT pi 的东西,看起来挺有趣。还有 muon optimizer,这里还有 distributed muon,细心地网友称:这估计是给 H100 GPU 用的。
另外,参数部分也挺吸引人。序列长度是 24,层数 12,768 维度,看起来是个中小型模型。因为我自己也在搭模型,所以看到这些配置挺有参考价值。
网友注意到一个trick的细节。他爆料到,一般来说,Karpathy 总喜欢让数字“好看”——比如用 2 的平方倍数。
但其实这次,上面这些参数都不是严格的 2 的平方,但可能能被分解成一些平方的倍数。比如上面的这三个参数:24、12、768,都不是。所以他猜测卡神肯定是发现最后这几个数字更合适。
“我本来预期 hidden size 会是 148,不知道他为什么选了 768。”
还有,正则方面,卡神没有采用 Pytorch自带的 RoPE(旋转位置编码),而是采用了自己写的版本。
实现特别简洁,简直是我见过最优雅的代码。他的思路是把向量一分为二,然后用旋转矩阵分别处理,再拼接回来。虽然我还没完全吃透旋转矩阵的部分,但能看出这是个非常轻量、教学导向的实现。
这还没完,在 自回归注意力(causal self-attention) 模块里,卡神把 query、key、value 的线性层分开实现。其实也可以优化成一次线性变换,然后再分割结果张量,这样可以减少内存读写。
激活函数方面,他使用了一个叫 ReLU²(ReLUSquared) 的激活函数,据说在一些实验中收敛更快。
卡神还提到了预计算 旋转嵌入(rotary embeddings) 的技巧:提前把 cos 和 sin 值算好放在 GPU 内存里,因为它们不依赖训练参数。
在优化器部分,他把参数拆成两组:embedding 和 LM head 用 AdamW,矩阵参数用 Muon Optimizer。这个优化器是最近新出的,据说在特征学习(feature learning)上表现不错。
当然,也有一些业界所公认的Trick,比如大框架还是经典的 Transformer 结构:自注意力 + MLP + 残差。
再比如采用 KV cache,来加速推理。代码里根据 cache 是否存在分支执行不同逻辑,这点和大多数 LLM 实现类似。
还有,MLP 部分,卡神没用 Mixture of Experts,理由很合理:MoE 更适合推理阶段,而不是研究阶段。MLP 更易于理解和调试。
下一步:发展成一个研究工具或基准
卡神在X上表示,项目还没完工,自己的目标是将完整的“强基线”堆栈整合到一个内聚、精简、可读、可修改且最大程度可分叉的仓库中。
而NanoChat 将成为 LLM101n(仍在开发中)的顶点项目。
我认为它也有潜力发展成为一个研究工具或基准,类似于之前的 nanoGPT。它远未完成、调整或优化(实际上我认为可能还有不少唾手可得的成果),但我认为它的整体框架已经足够完善,可以上传到 GitHub 上,以便所有部分都能得到改进。
写在最后
当然,这套复刻框架,肯定不能真正意义上直接帮各位得到一个ChatGPT 1:1的复刻版。
因为局限就摆在那里。性能上,如果想要运行流畅度,就可能需要自己上手微调。那这就需要用户得有点技术背景才能玩转它。
比如,如果你的 显存(VRAM) 比较小,就得调整超参数。这对新手来说可能是个门槛。
但小编看来,更多的意义,还是在于,让“高在天上”的 LLM产品,变得更加评价、可及。
也就是说,卡神的这个项目继续让 AI 开发更大众化了,让更多人,尤其是算力不够的学校、学生们能参与、实验动手了起来。
而这则会进一步带动AI应用的繁荣。
想一想,如果连大学学生、业余开发者都能低成本训练模型,也许能催生很多有创意的应用。
因为这个项目是开源的,所有人按照自己需求进行调整、修改,得到自己想要的结果。
使用 nanochat,你几乎可以调任何东西。无论是换 tokenizer、改训练数据、调整超参数,还是优化算法,都可以自由尝试——有很多潜在思路可以探索。
如果你希望训练更大的模型,也很容易做到。
代码库的设计是完全可扩展的:你只需要通过参数 --depth 来改变模型层数,其他相关参数都会自动按比例调整。
这意味着它的“复杂度”只靠这一个滑杆就能控制。
正如一位网友所说,看起来,NanoChat虽然只是小步前进,但它可能引发大波浪。
项目提供了详细的指导文档,它还支持把文件打包成可查询的数据块,很友好。这一点我挺欣赏——能看出作者是站在用户角度思考的。没错。
现在,大家都能理解Karpathy为什么会被称之为“卡神”了吧!太牛了!
 图片
图片
写完这篇稿子一看,哇塞,这个项目已经狂飙到了8.2K星!
参考链接:
https://www.youtube.com/watch?v=EFpDHdsITrg&t=419s
https://x.com/karpathy/status/1977755427569111362


