AI圈最近被一颗重磅炸弹炸醒了。不是什么新的千亿参数大模型,而是一个由Andreij Karpathy,这位曾是特斯拉AI总监、OpenAI创始成员的大佬,亲手打造的开源项目——nanochat。它的宣传语大胆而诱人:“$100就能买到的最好的ChatGPT。”这不单单是一个代码仓库,更像是一份AI时代的《人人都能造AI》使用手册,以其惊人的简洁性、端到端的可复现性,迅速成为开发者和研究者的新宠。
 图片
图片
一场成本与效率的“极速挑战”
想象一下,从零开始搭建一个类ChatGPT模型,需要多少资源和知识?过去,这几乎是巨头们的专属游戏。但nanochat告诉你:一个脚本,一套流程,你就能窥其全貌。它的核心目标是提供一个极简、全栈的开源方案,让你在单台配备8个H100 GPU的服务器上,以极低的成本复现一套完整的LLM(大型语言模型)训练与部署流程。
这份“使用手册”的核心魅力在于:
- 极简主义的典范: 整个项目代码量惊人地少,区区约8000行代码,却覆盖了从数据处理、分词器训练、模型预训练、指令微调、强化学习(可选)、评估到最终Web交互界面的全流程。Karpathy甚至透露,这些代码几乎全部是他“纯手写”的成果,连AI编程助手都帮不上什么忙,足见其精巧。
- 端到端的流畅体验: 项目提供了 speedrun.sh这样的“一键复现”脚本。你只需准备好硬件环境,运行这个脚本,就能像看一场精彩的电影一样,目睹一个对话式AI从无到有的全过程。
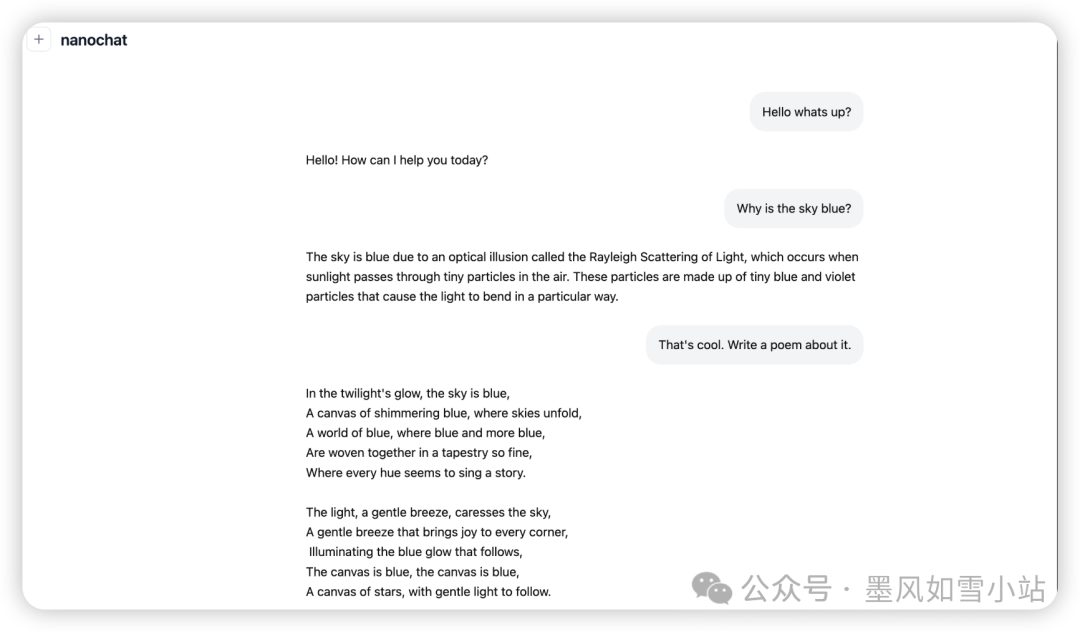
- 低成本的冲击波: “百元”之说并非空穴来风。据项目方估算,在8x H100节点上训练约4小时,成本约100美元,就能得到一个能进行基础对话、写诗和讲故事的模型。如果投入约1000美元(训练约41.6小时),模型的连贯性、解决数理/代码问题的能力将显著提升,甚至在MMLU等权威榜单上也能拿得出不错的成绩。
 图片
图片
拆解“百元ChatGPT”的秘密武器
那么,nanochat是如何做到这一切的呢?它的技术栈虽然极简,却不失精妙:
- 分词器: 这是模型理解人类语言的“耳朵”和“嘴巴”,nanochat为此打造了一个全新的Rust实现,追求极致的效率。
- 预训练: 在FineWeb数据集上,一个精简但稳健的Transformer模型(类似Meta的Llama架构,但做了简化,采用了旋转位置编码RoPE、多查询注意力MQA等技术)开始汲取海量互联网文本的知识。
- 精心的“塑形”: 随后是指令微调(SFT)和可选的强化学习(RL),在这些阶段,模型被“塑造”成一个乐于助人的对话助手,学会如何与人类交互,理解指令,甚至尝试使用工具。
- 高效推理与交互: 项目自带一套高效的推理引擎,支持KV缓存和工具调用。训练完成后,你可以通过命令行或一个类ChatGPT的Web用户界面,立马与你的“新朋友”展开对话。
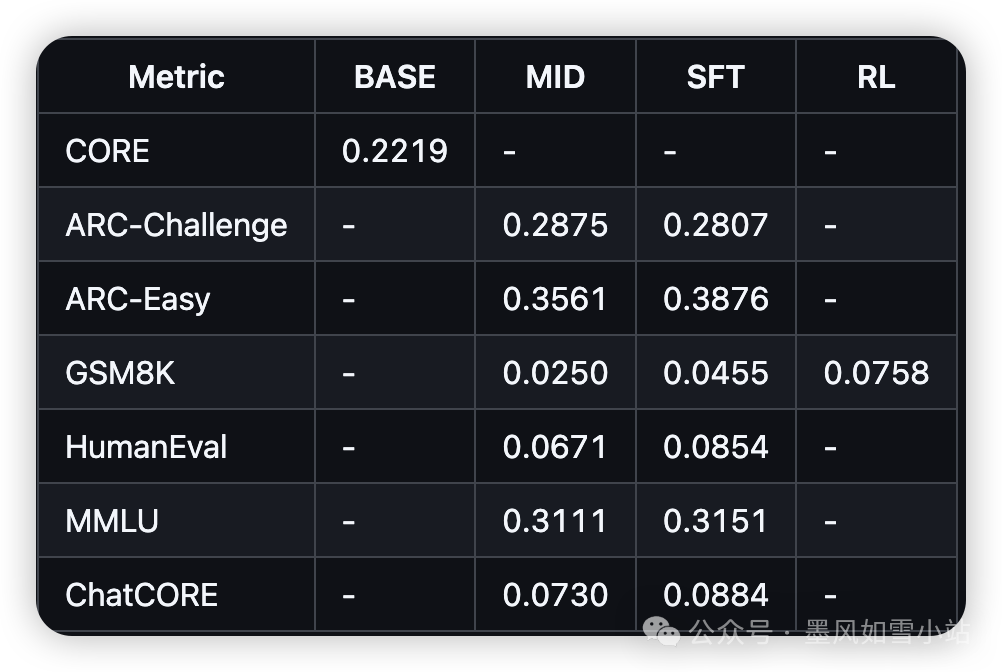
- 游戏化评估: 整个训练过程并非“盲盒”,nanochat会在训练中和训练后,在多个基准测试(如ARC-E、MMLU、GSM8K)上评估模型性能,并自动生成一份Markdown格式的“报告卡”,以“游戏化”的方式总结成果,让训练过程充满乐趣。
 图片
图片
它能做什么?又不能做什么?
nanochat的出现,无疑为AI研究和教育打开了一扇新的大门:
- 研究与教学的理想素材: 对于想深入了解大语言模型原理和实践的同学来说,这简直是教科书级的实战项目,是Karpathy正在开发的LLM101n课程的绝佳实践。
- 快速原型验证的利器: 开发者可以在有限预算下,快速搭建一个可交互的对话系统,验证自己的奇思妙想。
然而,作为AI圈的创作者,我必须负责任地指出其局限性:
- 非生产级工具: Karpathy本人就形容其智能水平为“幼儿园小孩”。别指望它能媲美OpenAI或Google的顶级模型,它更像是一个“强势基线”和学习起点,而非直接用于生产环境或严肃商业应用的方案。
- 个性化微调的“陷阱”: 最关键的是,如果你想用它来“私有化定制”一个只懂你的专属AI,基于你的个人笔记数据进行微调,恐怕会大失所望。Karpathy明确指出,小模型原始智能有限,直接微调很容易导致模型失去通用能力,变得只会“鹦鹉学舌”,逻辑混乱。实现高质量的个性化模型,目前仍属于前沿研究课题。
所以,那个“百元”更多的是一个引人注目的起点,而非终点。它让你看到了AI的潜力,提供了一个触手可及的实践平台,但距离构建一个真正强大、定制化的AI,我们还有很长的路要走。
尾声:AI民主化的新篇章?
nanochat项目一经发布,GitHub上星标如潮,社区里讨论热烈,许多开发者认为它极大地推动了AI技术的民主化。它打破了传统LLM训练的神秘面纱,以一种前所未有的简洁和透明,让更多人有机会参与到大语言模型的学习和实验中来。
总而言之,nanochat不仅仅是一个项目,它更像是一扇窗户,让更多人有机会窥探LLM的奥秘,理解其运作机制。无论你是AI的初学者,还是资深研究者,nanochat都值得你投入时间去探索。因为它展现的,是AI技术走向普惠的道路上,一次大胆而精妙的尝试。


