
大家好,我是肆〇柒。今天要和大家一起阅读一项来自北京大学、新加坡国立大学、东京科学研究所、南京大学、Google DeepMind、西湖大学与东南大学等机构联合发表的重要研究——《TrustJudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them》。这项工作首次系统揭示了当前主流大模型自动评估范式中存在的两类根本性逻辑矛盾,并提出了一套无需额外训练、即插即用的概率化评估框架,显著提升了评估的一致性与可靠性。
在大模型评估领域,一种日益普及的做法是让大型语言模型(LLM)扮演"裁判"角色,自动评估其他模型的输出质量。这种方法被称为LLM-as-a-Judge(大型语言模型作为评估者),因其可扩展性和成本效益而广受欢迎。然而,研究人员最近发现了一个令人困惑的现象:同一个LLM作为裁判时,其评估结果可能存在系统性逻辑矛盾。这种现象不仅影响评估结果的可靠性,更动摇了基于自动评估的模型开发与优化基础。本文将深入探讨这一问题的根源,并介绍TrustJudge这一创新框架如何系统性解决LLM-as-a-Judge的评估不一致性问题。
一个令人困惑的现象
想象这样一个场景:你是一家AI公司的评估工程师,正在使用LLM-as-a-Judge评估两个客服机器人的回复质量。在单分数评估中,模型给响应A打4分(优秀),给响应B打3分(良好),表明A优于B。然而,当客户实际面对这两个回复时,却更喜欢机器人B的回复。这种矛盾不仅让你难以向管理层解释评估结果,更可能导致错误的产品决策——将表现较差的机器人部署到生产环境。

成对比较评估示例
查看实际评估输出,可以看到模型对响应A的评分分布为:{"4": 0.3775, "3": 0.6224, ...},最终给出Score:[4];而在成对比较中,却输出Verdict:[B]。这意味着模型对响应A的评分分布显示3分概率更高(0.6224),但仍给出4分;而在直接比较时,又认为B优于A。
这种现象在实际应用中相当普遍。研究数据显示,当使用Llama-3.1-70B作为评估模型时,得分-比较不一致性(Score-Comparison Inconsistency)高达23.32%,这意味着近四分之一的评估案例中,单分数评估与成对比较结果相互矛盾。更令人担忧的是,这种不一致性并非评估模型能力不足所致,而是现有评估框架的系统性缺陷。
让我们分析下图中的具体评分过程:

单分数评估示例
评估模型对响应A的判断显示:3分概率为62.24%,4分概率为37.75%,其他分数概率可忽略。尽管3分概率更高,但传统离散评分仍选择最高概率分数(4分)。这种"非概率性"决策导致了信息损失——评估模型对响应A质量的判断不确定性(即"判断熵")被完全丢弃。而在成对比较中,这种细微差异被放大,导致最终判断B优于A。
这种矛盾的核心在于:离散评分系统强制将概率分布压缩为单点估计,而这一压缩过程丢失了关键的质量差异信息。当两个响应的质量差异较小但方向明确时,离散评分可能将它们映射为相同分数,而在成对比较中却能区分出细微差异,从而产生逻辑矛盾。
两大根本性不一致问题的定义与实证
研究者将LLM-as-a-Judge中的评估不一致性归纳为两类根本问题:
得分-比较不一致:离散评分的陷阱
得分-比较不一致(Score-Comparison Inconsistency) 指单分数评估与成对比较结果之间的逻辑矛盾。形式化定义为:当

这种不一致的根源在于离散评分系统的信息损失。传统的5分制评分将丰富的质量差异压缩为有限的整数分数,导致不同质量的响应可能获得相同分数。例如,两个质量有细微差别的响应都可能得到4分,但它们的实际质量差异在后续成对比较中可能显现出来。
成对传递性不一致:模糊判断的代价
成对传递性不一致(Pairwise Transitivity Inconsistency) 指成对比较中出现的非理性偏好模式,包括两种类型:
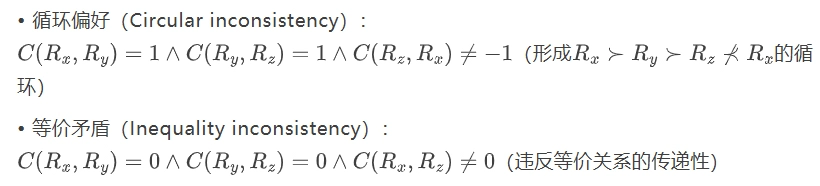
实证数据显示,当使用Llama-3.1-70B作为评估模型时,非传递率(NTRk=5)高达15.22%,这意味着在五元组比较中,约六分之一的案例存在逻辑矛盾。
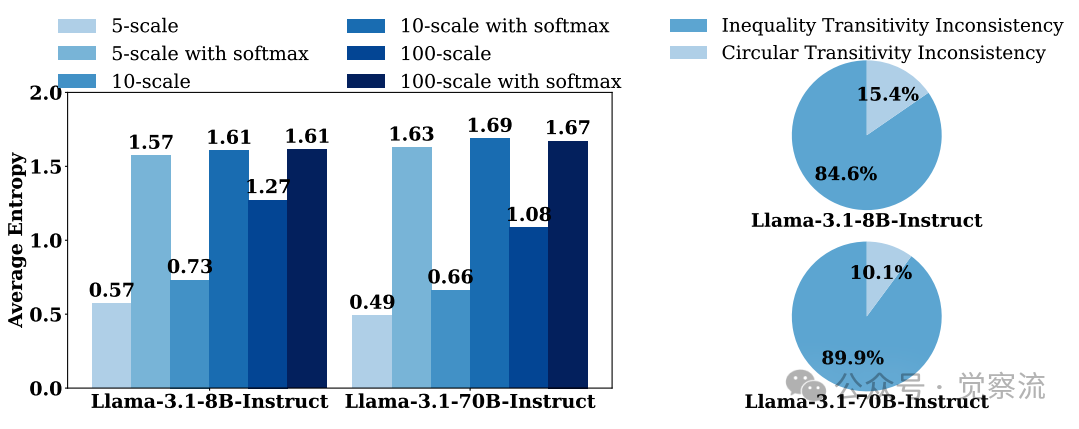
模型单分数输出的平均熵与成对比较不一致分解
上图左侧揭示了Llama-3系列模型在不同评分策略下的平均熵值。值得注意的是,评分粒度越细(5点→10点→100点),模型判断的熵值越高(Llama-3.1-8B从0.57提升至1.61),表明更细粒度评分保留了更多判断不确定性。这一现象直观解释了为什么增加评分粒度能减少不一致性——评估模型能够更精确地表达其判断置信度。
右侧数据显示,成对传递性不一致主要由等价矛盾(Inequality Transitivity Inconsistency)主导,而非循环偏好(Circular Transitivity Inconsistency)。例如,Llama-3.1-8B的等价矛盾占总不一致性的81.5%(16.54% vs 20.26%),这为后续Likelihood-aware Aggregation的设计提供了关键依据。
信息损失的理论证明

过保留完整的概率分布,TrustJudge避免了这种信息损失,从根本上解决了Score-Comparison不一致问题。
TrustJudge 的核心思想:用概率建模保留判断熵
判断熵:被忽视的关键信息
TrustJudge的核心洞见是:评估模型对响应质量的判断本质上是一个概率分布,而非单一确定值。传统的离散评分方法强制将这一分布压缩为单个整数分数,导致信息损失和评估不一致。
研究者引入了"判断熵"的概念,指评估模型对评分的不确定性。例如,当模型对一个响应可能给3分或4分时(如{"3": 0.6224, "4": 0.3775}),这种不确定性本身就是有价值的信息,不应被丢弃。可以类比为:就像天气预报不仅给出"明天会下雨"的判断,还提供"降雨概率70%"的信息,评估模型也应该报告其判断的置信度,而非仅给出一个确定分数。
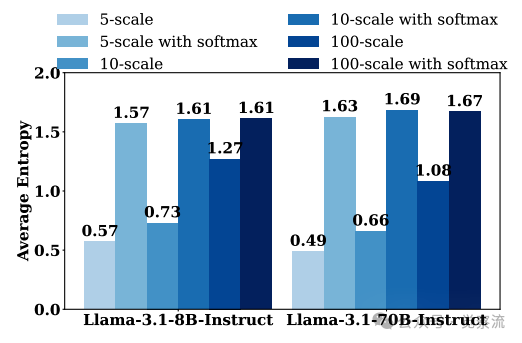
上图数据直观展示了这一问题:使用5分制评分时,Llama-3.1-8B的平均判断熵仅为0.57,这意味着评估模型对自己的判断非常"自信",但实际上这种"自信"是虚假的——它被迫将复杂的质量判断压缩为简单整数,丢失了关键的不确定性信息。
问题本质:信息损失 vs 信息保留
离散评分系统的问题在于,它忽略了这种不确定性,将复杂判断简化为一个点估计。TrustJudge的关键创新在于保留并利用这一判断熵,而非试图消除它。这与先前其他人的研究工作有本质区别——那些工作主要关注提升与人类评估的一致性,而TrustJudge聚焦于修复评估框架自身的逻辑缺陷。
Theorem 3.1从理论上证明了这一方法的有效性:当两个不同分布具有不同条件熵时,离散评分可能给出相同分数,而分布敏感评分则能区分它们。这为TrustJudge提供了坚实的理论基础。
TrustJudge 的两大技术创新
分布敏感评分:从整数到连续
TrustJudge首先摒弃了传统的离散评分方法,采用分布敏感评分机制:
1. 细粒度评分:要求评估模型在更精细的尺度上评分(如100分制而非5分制)
2. 概率归一化:使用softmax函数将原始概率转换为有效概率分布
3. 期望值计算:计算连续期望值作为最终分数
数学表达式为:
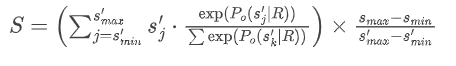
这种方法保留了评估模型判断的完整熵,避免了信息损失。随着评分尺度从5点扩展到100点,冲突率(CR)系统性下降,证明了评分粒度对减少不一致性的重要性。
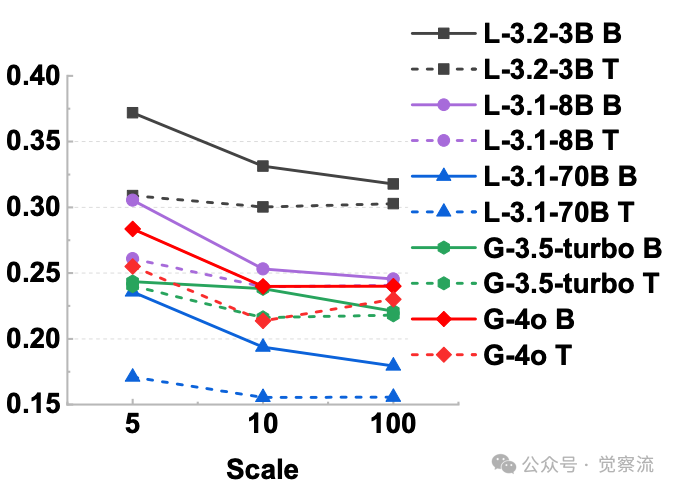
评分粒度对冲突率的影响
上图揭示了一个关键发现:当评分粒度从5点增加到100点时,Llama-3.1-70B的冲突率从23.32%降至14.89%。这表明更细的评分尺度让评估模型能更精确地表达质量差异。想象一下,如果考试只给'及格/不及格'两个选项,很多水平相近的学生会被错误归类;而采用百分制评分,我们能更准确地区分他们的能力差异。
似然感知聚合:解决传递性问题
针对成对比较中的传递性不一致问题,TrustJudge提出两种解决方案:
方案A:基于困惑度(PPL-based)打破平局
当评估模型难以区分两个响应时(即判断为平局),计算两种顺序的困惑度:
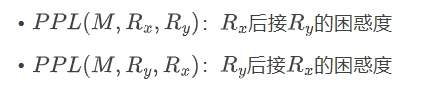
选择困惑度更低的顺序作为偏好结果:$$C(R_x, R_y) = \begin{cases}C_{order1} & \text{if } PPL(M, R_x, R_y) < PPL(M, R_y, R_x) \C_{order2} & \text{otherwise}\end{cases}$$
方案B:双向偏好概率聚合

最终选择概率最高的结果:A>B。这种方法系统性地消除了位置偏差,同时保留了评估模型的判断置信度,有效解决了Pairwise Transitivity Inconsistency问题。
下表的实验结果表明,likelihood-aware aggregation通常优于PPL-based方法。例如,使用Llama-3.1-70B时,NTRk=4从7.23%降至1.94%。
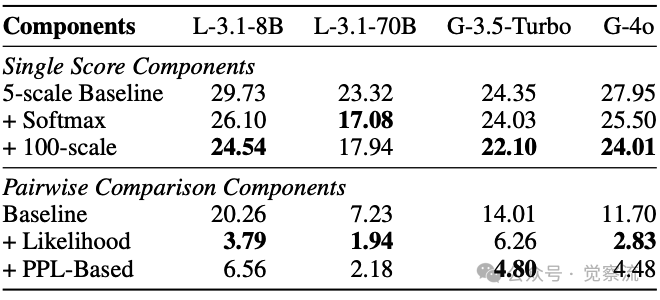
此外,TrustJudge引入了容忍度参数,允许用户根据应用场景灵活调整平局判定阈值。下图展示了不同值下的不一致性表现,证明TrustJudge在各种容忍度设置下都保持稳健。
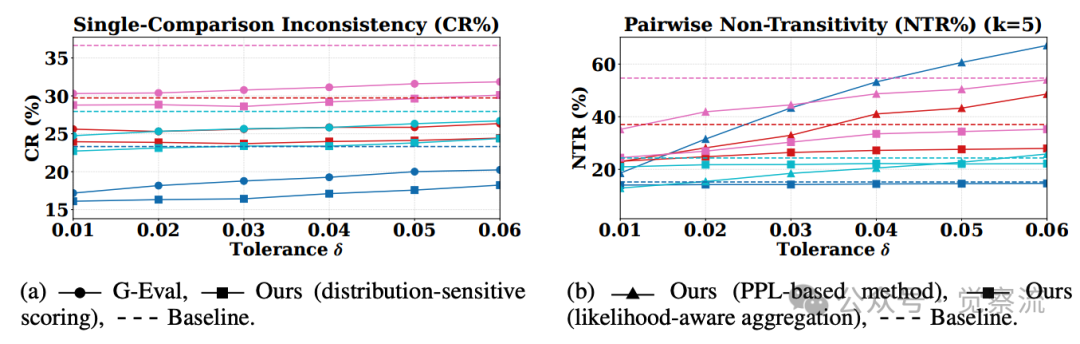

实验验证:一致性显著提升,且不牺牲准确性
核心发现:一致性与准确性的双赢
TrustJudge的实验效果令人印象深刻。当使用Llama-3.1-70B作为评估模型时:
- Score-Comparison不一致性下降8.43%(从23.32%降至14.89%)
- Pairwise Transitivity不一致性下降10.82%(从15.22%降至4.40%)
- Exact Match率提高6.85%(在小模型Llama-3.2-3B上)
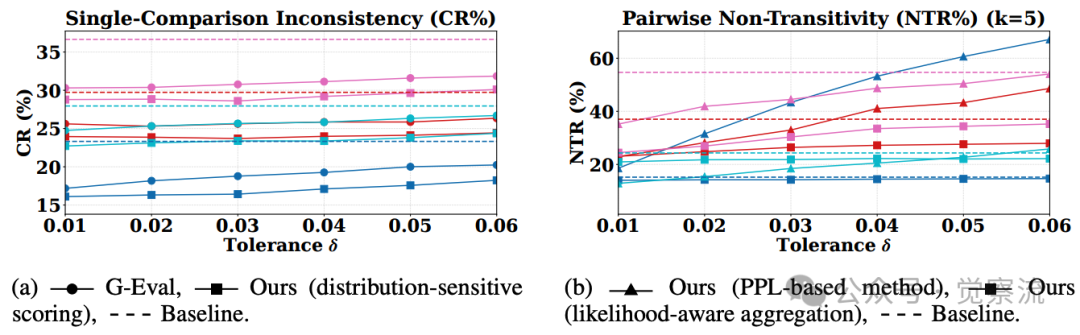
不同容忍度下的不一致性表现
更值得注意的是,这些改进是在不牺牲评估准确性的前提下实现的。TrustJudge 在保持或提高准确率的同时,显著降低了不一致性。这解决了先前方法面临的权衡困境——以往改进一致性往往以牺牲准确性为代价。
模型规模与性能的非线性关系
TrustJudge展现出卓越的跨模型泛化能力,但下图揭示了一个反直觉的发现:9B参数的Gemma模型不一致性低于其27B版本。这挑战了"更大模型总是更好"的直觉,表明模型规模与评估能力之间存在复杂的非线性关系。
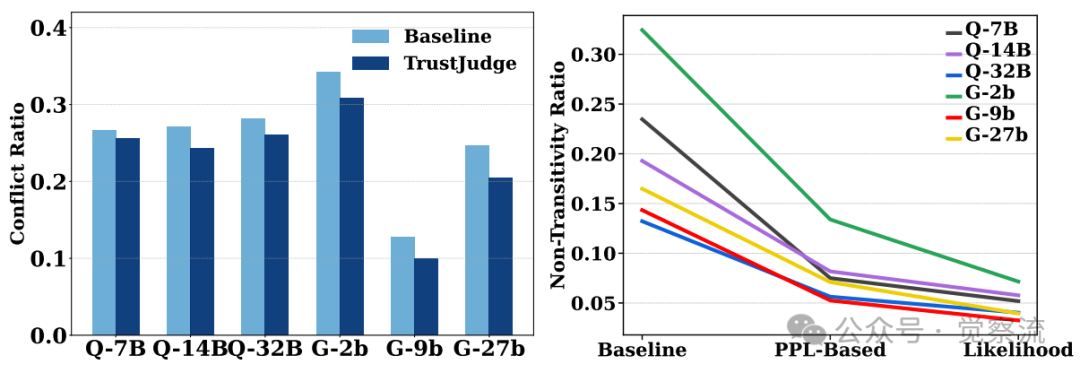
不同大小和结构的LLM的TrustJudge性能
上图揭示了三个关键发现:
1. 架构无关性:TrustJudge在所有测试架构上都实现了不一致性降低
2. 性能逆转:该方法有效逆转了传递性违规现象,使中等规模模型在受控评估设置下能超越更大规模的基线模型
3. 规模-性能解耦:TrustJudge显著缩小了小模型与大模型之间的性能差距
这一发现对资源受限场景具有重要启示:TrustJudge能够显著缩小小模型与大模型之间的性能差距,使资源效率模型在评估任务中更具实用性。例如,Gemma-2-9B+TrustJudge的不一致性可能低于Gemma-2-27B+传统方法,为实际应用提供了成本效益更高的选择。
任务导向的性能差异
任务类别分析(下表)揭示了一个重要现象:在开放生成类任务中,TrustJudge效果尤为显著:
- Coding:冲突率从27.74%降至21.78%(优于G-Eval的22.13%)
- Reasoning:冲突率从25.90%降至20.72%(优于G-Eval的21.17%)
- Writing:冲突率从30.97%降至23.93%(优于G-Eval的24.09%)
而在STEM等高度结构化任务中,G-Eval方法仍有轻微优势。
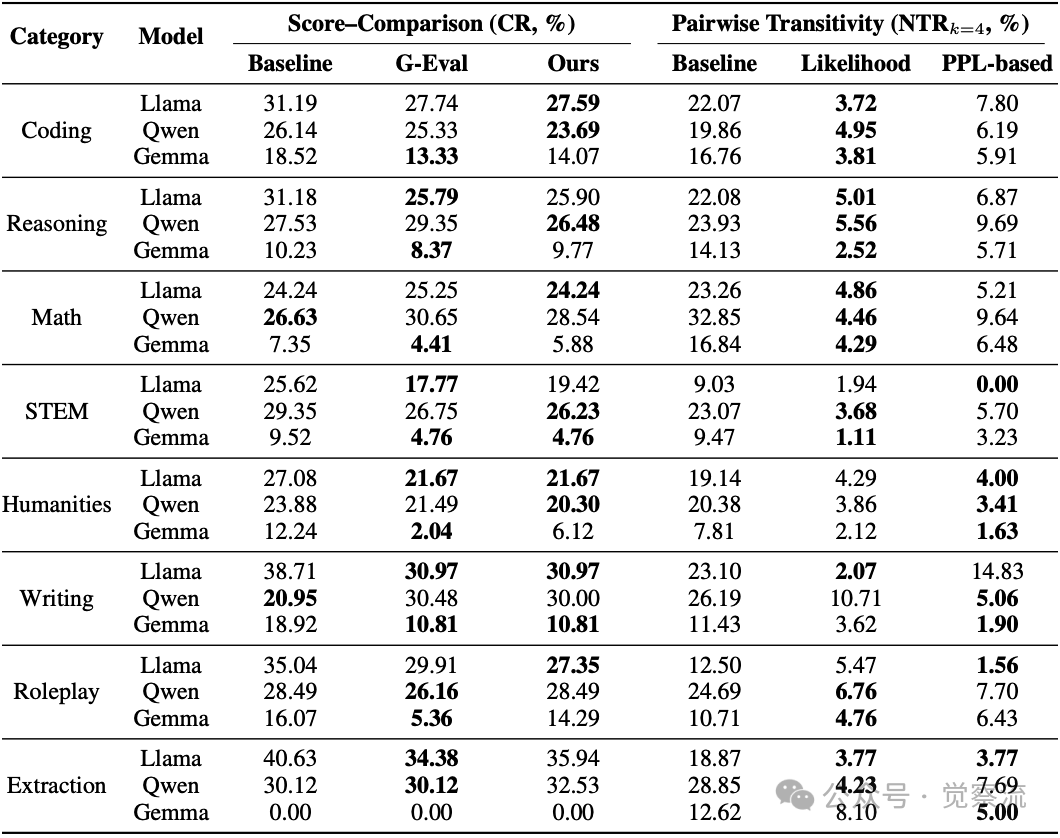
不同任务类别下的不一致性表现
上表清晰展示了TrustJudge在不同任务中的表现差异:
- 开放生成任务(Coding、Reasoning、Writing):TrustJudge显著优于G-Eval,冲突率(CR)降低明显
- 事实性任务(STEM、Extraction):G-Eval方法略有优势
这种差异反映了任务特性与评估方法的匹配关系:
- 开放生成任务中,响应质量差异更为连续和主观,需要更细粒度的评分系统
- 事实性任务中,正确性更为二元化(对/错),离散评分已足够区分质量差异
特别值得注意的是Math任务的特殊性:在Llama-3.1-8B评估中,原始Baseline(24.24%)略优于TrustJudge(24.24%)和G-Eval(25.25%)。这表明在高度结构化的数学问题中,简单的离散评分可能已足够有效,无需复杂的概率建模。
多维度评估的扩展
此外,TrustJudge成功扩展到多维度评估。在事实性、连贯性和有用性三个维度独立评估时:
- Llama-3.1-70B上NTRk=4从44.65%降至16.21%
- CR从52.20%降至41.47%
这一结果表明,当质量被分解为正交组件而非测量为单一未区分分数时,TrustJudge的改进仍然持续。机制上,标量通道受益于分布敏感评分,平滑离散化伪影并减少数字分数与成对偏好之间的冲突;成对通道受益于具有校准平局处理的可能性感知聚合,抑制位置偏差。
延伸价值:不止于评估,还可用于DPO奖励建模
细粒度偏好信号的价值
TrustJudge的价值不仅限于提升评估可靠性,还可直接应用于模型对齐训练。研究者将TrustJudge生成的细粒度评分用于DPO(Direct Preference Optimization)训练,结果令人鼓舞:
- Llama-3.1-8B:Win Rate从19.13%提升至20.52%(标准)和7.95%提升至24.16%(LC)
- Qwen2.5-7B:Win Rate从16.82%提升至18.54%(标准)和15.09%提升至18.76%(LC)
这些结果表明,TrustJudge提供的高质量偏好信号能有效指导模型优化,避免传统方法中因评估不一致导致的次优对齐。
推理模型的评估能力退化
下表揭示了一个重要现象:经过强化学习训练的推理模型(如DeepSeek-R1)可能存在"裁判能力退化"问题。这些模型在特定任务上表现优异,但作为评估者时却不一致性显著升高(DeepSeek-R1的CR高达58.75%)。
模型 | CR(%) | NTRk=4(%) | NTRk=5(%) |
Baseline | G-Eval | Ours | |
Llama-3.1-8B | 29.73 | 25.31 | 23.75 |
DeepSeek-R1 | 58.75 | 53.63 | 49.28 |
上表清晰展示了这种退化:Llama-3.1-8B的冲突率为29.73%,而DeepSeek-R1-Distill-Llama-8B高达58.75%;NTRk=5从37.03%飙升至63.98%。这一发现对模型训练具有重要启示:专门针对数学推理等任务的强化学习可能会损害模型的通用评估能力。尽管如此,TrustJudge仍能有效改善这类模型的评估表现(DeepSeek-R1的CR从58.75%降至49.28%),展现了其鲁棒性。
方法限制与适用边界
模型能力与不一致性的非线性关系
尽管TrustJudge效果显著,但其应用也存在一些限制:
首先,TrustJudge的效果依赖于评估模型的基本能力。如Appendix B所述,小型语言模型可能缺乏足够的指令遵循能力,无法正确执行评分任务。这意味着TrustJudge更适合应用于中等规模及以上的评估模型。
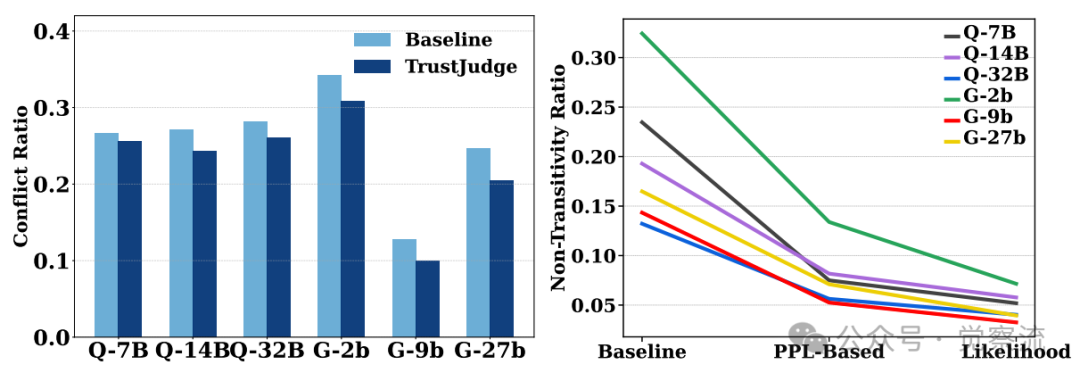
特别值得注意的是,模型能力与不一致性之间存在非线性关系。上图显示,9B参数的Gemma模型不一致性低于其27B版本,这表明单纯增加模型规模不一定能改善评估一致性。在资源受限场景下,TrustJudge能够显著缩小小模型与大模型之间的性能差距,使资源效率模型在评估任务中更具实用性。
任务类型的影响
其次,任务类型会影响改进幅度。在高度结构化、事实性强的任务(如STEM、Extraction)中,TrustJudge的改进可能不如开放性任务明显。数据显示,在STEM任务中,G-Eval方法的CR为17.77%,优于TrustJudge的19.42%;在人文任务中,G-Eval的CR为21.67%,与TrustJudge持平。这提示研究者应根据任务特性选择合适的评估策略。
实用价值:即插即用的评估增强
值得强调的是,TrustJudge的最大优势在于其即插即用特性——无需额外训练或人工标注,只需调整评估协议即可显著提升评估一致性。这一特点使其易于集成到现有评估流程中,为研究者和工程师提供即时价值。
总结:迈向更可信的自动评估
TrustJudge代表了LLM-as-a-Judge范式的重大进步。作为首个系统性分析并解决评估框架不一致性的研究,它不仅揭示了现有方法的理论局限,还提供了切实可行的解决方案。
这项工作的价值在于:它使自动评估更加可靠,而无需牺牲评估效率或准确性。在模型规模不断扩大、评估需求日益增长的背景下,TrustJudge为构建更可信的评估基础设施提供了关键组件。
从实际应用角度看,TrustJudge为不同场景提供了灵活选择:
- 资源受限场景:小型团队可使用Llama-3.2-3B+TrustJudge替代GPT-4o+传统方法,将冲突率从36.65%降至29.15%,同时大幅降低成本
- 多维度评估:TrustJudge在事实性、连贯性、有用性三个维度均能显著降低不一致性,适用于需要全面评估的场景
- DPO训练:TrustJudge生成的细粒度评分可直接用于DPO训练,将Llama-3.1-8B的Win Rate从19.13%提升至20.52%,为模型对齐提供更可靠的偏好信号
这项工作提醒我们:评估系统本身的质量,是衡量模型进步的基石。只有建立在稳固评估基础之上的比较和优化,才能真正推动大模型技术的健康发展。TrustJudge通过保留评估模型的判断熵,修复了现有评估框架的内在逻辑缺陷。目前,TrustJudge已在GitHub开源(https://github.com/TrustJudge/TrustJudge),大家可以尝试使用。


