最近有个感觉特别强烈:AI正在从"识别文字"悄然进化成"理解文档"。当我看到百度飞桨团队刚刚发布的PaddleOCR-VL在全球权威评测中以92.6分位列第一时,第一反应是——这个0.9B的"小家伙",怎么就把那些动辄几十亿参数的巨无霸给比下去了?
说实话,刚开始我也有点半信半疑。毕竟传统OCR工具给人的印象就是"能用但不好用"——扫描个PDF经常把表格搞得乱七八糟,数学公式识别成天书,更别提那些复杂排版的古籍文档了。
但这次不一样。PaddleOCR-VL不再只是"看字识字",而是真的开始"读懂文档"了,社区一片惊叹!
从"识别"到"理解"的技术跃迁
传统OCR的问题其实很明显:它们就像一个只会逐字念书的小学生,看到什么字就读什么字,完全不理解整个文档的逻辑结构。你给它一个包含表格、公式、图表的复杂文档,它输出的往往是一堆杂乱无章的文本碎片。
PaddleOCR-VL的突破在于,它采用了一个很巧妙的两阶段架构。第一阶段用PP-DocLayoutV2快速扫描整个文档,就像人看书时先翻一遍了解大致结构一样,规划出"这里是标题,那里是表格,这块是正文"的整体布局。第二阶段再派PaddleOCR-VL-0.9B模型去"精读"每个区域的具体内容。
这种"先规划,再执行"的策略比那些试图一口吞下整个文档的端到端模型要聪明得多。就像你不会让一个人同时负责城市规划和具体施工一样,专业分工往往比大而全更高效。
0.9B参数的"以小博大"
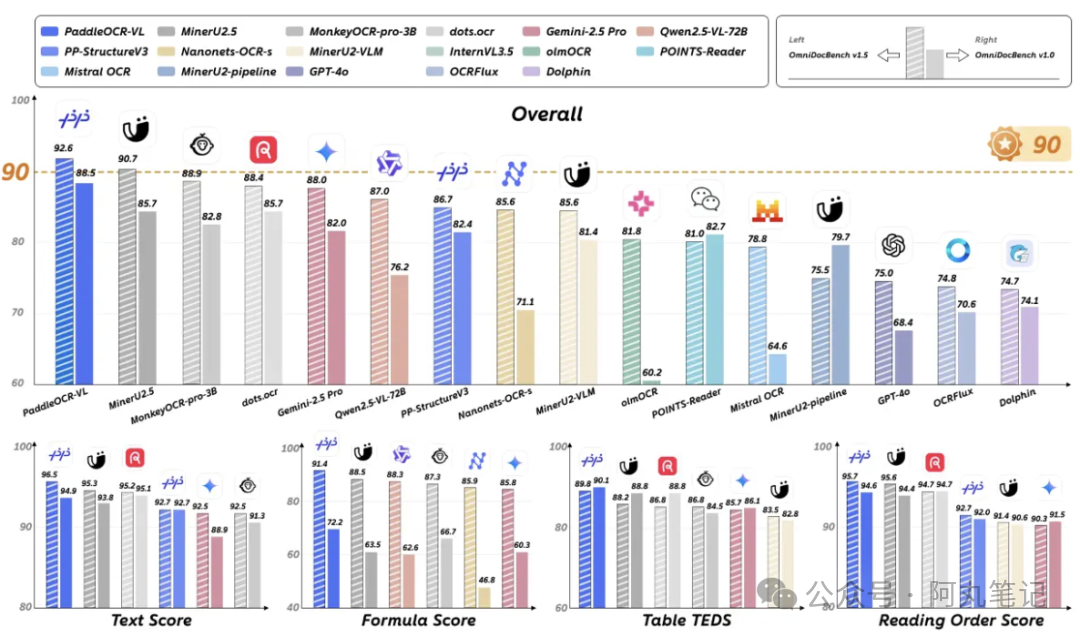
最让我意外的是参数规模。0.9B参数,这在当下动辄千亿参数的AI时代简直就是个"小不点"。但就是这个小模型,在OmniDocBench V1.5这个全球权威评测中拿到了92.6分的成绩,在文本、表格、公式、阅读顺序四大核心能力上全部达到SOTA水平。
更关键的是推理速度。在A100上每秒能处理1881个Token,这个速度意味着什么?一份20页的PDF文档,可能几秒钟就能完成高质量解析。而且由于模型轻量,完全可以部署在本地服务器甚至移动设备上。
我特意去GitHub看了看,发现它还支持109种语言的文档解析。这个覆盖面基本上涵盖了全球主要语言,对于跨国企业或者学术研究来说简直是福音。
实际应用场景让人兴奋
说了这么多技术细节,关键还是能用在哪里。我觉得最有价值的几个场景:
• 本地知识库建设 - 企业内部那些扫描版的技术文档、研究报告,终于可以高质量地转成结构化数据了。而且由于模型轻量,完全可以在内网环境部署,不用担心数据安全问题。
• 学术研究加速器 - 那些包含复杂数学公式的论文,现在可以直接转换成LaTeX格式。想象一下,几千篇文献的公式提取工作,从几个月缩短到几天。
• 移动端文档处理 - 0.9B的参数量意味着它有望在手机上运行。野外作业、现场办公时,直接用手机扫描文档就能得到高质量的结构化数据。
我还注意到一个细节:它能直接输出Markdown和JSON格式。这对开发者来说太友好了,不需要额外的格式转换,直接就能集成到现有的工作流程中。
开源策略的深层考量
百度选择完全开源这个模型,我觉得挺有意思的。在当前AI军备竞赛如此激烈的情况下,把这么强的技术直接开源,要么是技术储备足够深厚,要么就是在下一盘更大的棋。
从技术角度看,文档智能解析确实是一个相对垂直但需求巨大的领域。与其跟OpenAI、Google在通用大模型上正面硬刚,不如在这种专业领域建立技术护城河。而且开源能够快速建立生态,让更多开发者基于这个技术做创新。
想想看,如果PaddleOCR-VL成为文档解析的事实标准,那百度在这个垂直领域的话语权就建立起来了。这比闷头做一个封闭的商业产品要聪明得多。
亲身体验建议
如果你对这个技术感兴趣,建议从以下几个方面入手:
• 在线体验 - 先去百度AI Studio的官方Demo试试效果,上传几个不同类型的文档看看解析质量
• 本地部署 - 如果效果满意,可以从GitHub下载完整代码,在自己的环境中测试性能
• 集成开发 - 对于有具体业务需求的团队,可以考虑将其集成到现有的文档处理流程中
总的来说,PaddleOCR-VL代表了文档智能解析技术的一个重要里程碑。它证明了在垂直领域,精心设计的小模型完全可以击败参数更大的通用模型。这种"专业化胜过大而全"的思路,可能会成为未来AI应用的一个重要方向。
你们觉得这种专业化的小模型会不会成为趋势?


