
大家好,我是肆〇柒。今天要和大家分享的是一项来自腾讯大模型部门(LLM Department, Tencent) 与香港中文大学合作的前沿研究——RLPT(Reinforcement Learning on Pre-Training Data)。面对高质量数据增长见顶、计算资源持续膨胀的矛盾,这项工作提出了一种全新的训练范式:让大模型在原始预训练数据上通过强化学习自主探索推理路径,从而突破传统监督学习的泛化瓶颈。这不仅是一次技术升级,更是一场从“死记硬背”到“主动思考”的认知革命。
预训练范式的瓶颈与突破
想象一下:一个学生反复研读数学教材,却只能死记硬背例题答案,无法掌握解题精髓。如今的大语言模型(LLM)训练也遭遇类似瓶颈。计算资源呈指数级飙升,而优质文本数据的增长却极为有限,二者间差距日益显著,这严重制约了传统扩展方法的效能。传统依赖监督学习的预训练方式,正陷入“死记硬背”的困境,难以培育出深层次的推理能力。
研究表明,在NTP范式下的监督微调(SFT)往往促使模型进行表面级的记忆,而不是培养通过强化学习(RL)能够实现的更深层次的泛化能力。这意味着模型可能记住了“2+2=4”这样的事实,却无法理解加法的本质,更无法解决“2+3=?”这样的新问题。这种局限性在复杂推理任务中尤为明显——当面对需要多步推理的数学问题时,传统训练的模型往往只能给出最终答案,而无法展示解题过程。
RLPT(Reinforcement Learning on Pre-Training data)应运而生,它通过让模型"预测下一片段"而非"预测下一个token",引导模型主动探索数据中的隐含推理过程。这就像从让学生死记硬背答案,转变为要求学生展示解题步骤,从而培养真正的理解能力。RLPT不仅解决了数据稀缺问题,还为模型能力的持续提升开辟了新路径,使训练性能能够随着计算资源的增加而持续改善。
RLPT:超越监督学习的训练新范式
RLPT的核心思想是让模型像人类学习一样,通过预测"下一片段"来理解数据中的推理逻辑。考虑一个简单的数学问题:计算函数 在区间 上的傅里叶变换。传统预训练模型可能直接输出答案:"傅里叶变换为 ",但这种记忆式学习无法应对稍有变化的问题。
而RLPT则要求模型展示完整的推理过程。论文中提供了一个生动的思维过程示例:

这种"step by step"的思考方式,正是RLPT的核心价值所在——它迫使模型不仅知道"是什么",还要理解"为什么"和"怎么做"。
RLPT与现有方法的本质区别在于其自监督奖励机制。RLHF(Reinforcement Learning from Human Feedback)和RLVR(Reinforcement Learning with Verifiable Rewards)都需要人类标注或验证,而RLPT直接从原始预训练数据中获取奖励信号。这种设计使RLPT能够扩展到海量预训练数据,突破了人类标注的瓶颈。
从token级预测到segment级推理的目标升级,是RLPT的革命性突破。传统预训练关注下一个token的预测(如预测"4"作为"2+2="的后续),而RLPT关注更高级别的语义单元——文本片段(segment),如完整的推理步骤:"首先,将积分范围限制在[-a, a]内;然后,将指数函数拆分为余弦和正弦部分;接下来,计算余弦积分..."。这种转变使模型能够捕捉文本中更丰富的语义结构,培养更深层次的推理能力。
强化学习为何能够促进模型挖掘数据背后的隐含推理过程?强化学习的关键优势在于它能够生成中间推理内容,揭示数据构建中潜在的思维过程。正如材料所述:“强化学习使模型能够揭示数据背后的潜在推理过程,这可以被视为在下游性能中反映出来的深思熟虑的思维的一种压缩形式。”同时,强化学习利用自身的探索轨迹进行训练,保持与原始策略分布的接近性,从而培养出更强的泛化能力。
从训练时扩展视角看,RLPT代表了一种全新的计算资源利用方式。传统方法通过扩大模型规模或扩展预训练数据来减少预测损失,而RLPT则让模型自主探索和学习大规模预训练语料库。这种从"被动记忆"到"主动思考"的转变,使模型能够从相同数据中提取更深层次的知识,实现训练效率的质的飞跃。
技术创新:RLPT的架构设计

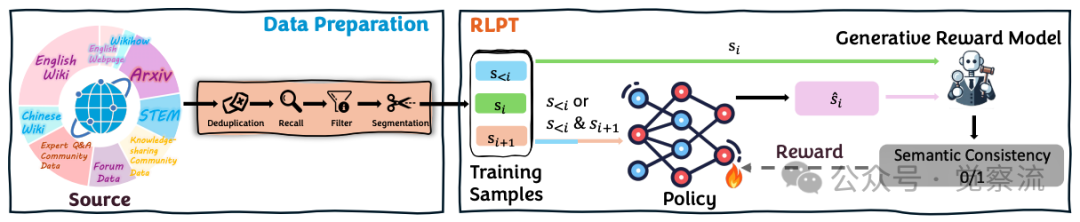
RLPT系统架构
上图清晰展示了RLPT的完整工作流程:从原始预训练数据出发,经过数据准备阶段,分割为语义连贯的片段序列,然后通过策略模型进行ASR和MSR任务的预测,最后由生成式奖励模型评估预测片段与参考文本的语义一致性。
RLPT包含两个关键任务:自回归片段推理(Autoregressive Segment Reasoning, ASR)和中间片段推理(Middle Segment Reasoning, MSR)。

Complete the text provided under### Context by predicting the next most probable sentence. Please reason step by step to determine the best possible continuation, and then enclose your final answer within<|startofprediction|> and<|endofprediction|> tags. ### Context{context}
这种设计不仅要求模型预测下一个句子,还强制其进行"step by step"的思考过程,模拟人类解题时的思维路径。例如,在解决傅里叶变换问题时,模型不会直接跳到最终答案,而是逐步推导:先定义积分范围,再拆分指数函数,然后分别计算余弦和正弦积分...

##Text Material##: {prompt}<MASK>{next_step} ## Task##: Fill in the<MASK> section of the material with appropriate sentences or a solution step. Carefully reason step by step to determine the most suitable completion.
这种任务特别适用于代码补全或需要上下文理解的场景,如"已知三角形两边长分别为3和4,<MASK>,求第三边长度",模型需要根据后续提示"且夹角为90度"来推断中间缺失的推理步骤。
生成式奖励模型通过评估预测片段与参考文本的语义一致性来计算奖励。最初的严格奖励机制要求预测片段必须与真实片段传达完全相同的语义内容,但这种方法过于僵化。论文中指出:“我们观察到,该模型经常生成包含多个真实片段的输出,这主要是由于基于句子的分割导致信息分布不均匀:有些句子只包含一个公式,而另一些句子可能涵盖了子问题的完整解决方案。”
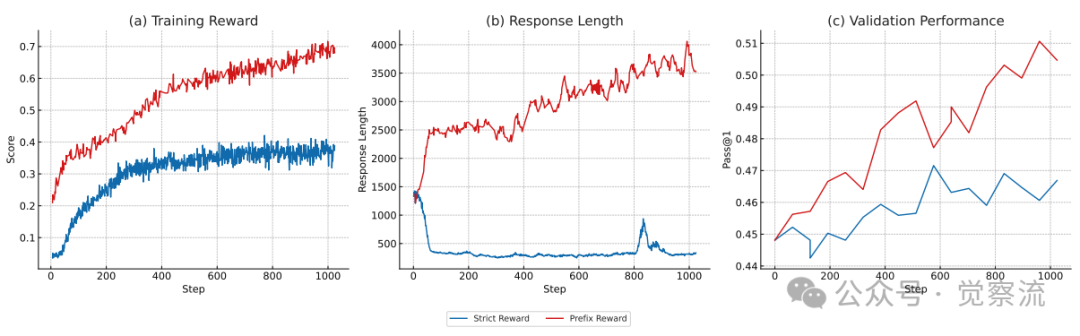
严格奖励与前缀奖励对比
上图直观展示了奖励机制演进的关键优势:(a)前缀奖励提供了更稳定、更高的训练奖励信号;(b)前缀奖励机制自然引导模型生成更长的响应(从约200 tokens增加到500+ tokens);(c)更重要的是,响应长度的增加直接转化为验证性能的提升(Pass@1从约0.45提升至0.50)。
让我们具体理解为什么前缀奖励如此关键。考虑一个数学问题的上下文:"已知圆的半径为r,面积公式为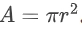 。"
。"
- 真实后续片段1:"首先,我们需要计算圆的面积。"
- 真实后续片段2:"然后,确定半径的值。"
如果模型预测:"首先,我们需要计算圆的面积,然后确定半径的值。",严格奖励会判定为失败,因为预测片段包含了两个真实片段的内容。但前缀奖励会识别出预测片段包含了正确前缀,从而给予正向反馈。
这种机制解决了句子间信息密度不均的挑战,使模型能够生成更连贯、更丰富的推理过程,而不是被强制切割成机械的单句预测。正如上图(c)所示,这种更自然的推理过程直接转化为下游任务性能的提升。
实现细节:从理论到实践的挑战
理解了RLPT的架构设计后,接下来将探讨如何将这一理论框架转化为实际可行的训练方案。实现RLPT面临多重技术挑战,其中冷启动问题和训练稳定性尤为关键。
RLPT的实施面临多个技术挑战,其中冷启动问题尤为关键。由于RLPT需要模型具备一定的指令遵循能力才能启动next-segment reasoning,研究者首先进行监督微调(SFT)阶段,使用批量大小1024、学习率2×10⁻⁵(余弦调度器)训练3个周期,为后续强化学习奠定基础。
数据准备流程包含三重保障机制:(i)基于MinHash的近似去重,(ii)个人身份信息(PII)检测与掩码,(iii)针对所有开发和评估集的污染去除。其中,基于规则的阶段消除明显不适合语言模型训练的内容,而基于模型的阶段则使用指令调优的语言模型进行更细粒度的质量评估。这种双重过滤机制确保了训练数据的高质量,为RLPT的有效性提供了坚实基础。
在训练策略上,RLPT通过超参数λ平衡ASR和MSR的贡献,训练目标定义为:
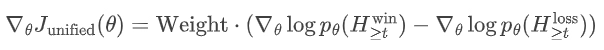
其中λ∈(0,1)可根据特定下游应用需求调整。实验中采用批量大小512、最大响应长度8192、恒定学习率1×10⁻⁶。对每个提示词,以温度1.0采样8个输出,使用on-policy GRPO(Generalized Reinforcement Policy Optimization)进行优化,无需KL正则化。
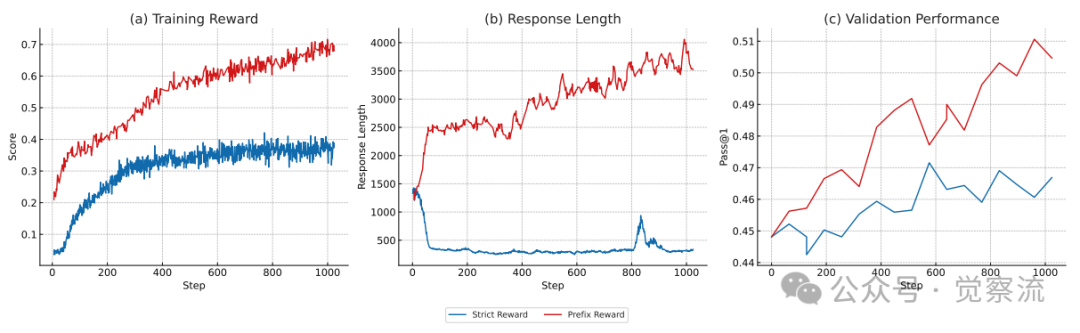
奖励机制的演进是解决训练稳定性问题的关键。从严格匹配到前缀奖励的转变,不仅避免了因句子信息密度不均导致的训练中断,还自然引导模型生成更长、信息更丰富的响应。上图(b)显示,前缀奖励促使模型生成的响应长度显著增加,这与上图(c)中验证性能的提升密切相关,表明更丰富的推理过程确实带来了更好的下游任务表现。
值得一提的是,RLPT在实现中定义片段单元默认为句子级别,虽然研究者也尝试了使用LLM提取文本中集成的原子步骤作为分割单元,但初步研究表明句子级分割已能有效工作。这种实用主义的设计选择避免了过度复杂化,使RLPT能够在保持效果的同时易于实现。
实验验证:量化分析与洞见
RLPT在通用领域和数学推理任务上均展现出显著优势。在通用领域任务中,研究者使用MMLU、MMLU-Pro、GPQA-Diamond、SuperGPQA和KOR-Bench等基准进行评估。结果显示,当应用于Qwen3-4B-Base模型时,RLPT在MMLU、MMLU-Pro、GPQA-Diamond、KOR-Bench上分别带来3.0、5.1、8.1和6.0的绝对提升。
这些数字背后的实际意义是什么?以MMLU为例,它包含57个学科领域的多项选择题,涵盖STEM、人文、社会科学等。3.0的提升意味着模型在这些广泛领域的知识应用能力显著增强——原本100道题能答对65道,现在能答对68道。在专业领域如GPQA-Diamond(研究生级物理、化学和生物学问题)上8.1的提升更为惊人,这相当于将模型从"勉强通过资格考试"提升到"能够进行独立研究"的水平。
在数学推理任务方面,RLPT在MATH-500、AMC23、Minerva Math和AIME24/25等挑战性数据集上取得突破性进展。表中展示了基于Qwen3-4B-Base模型的详细结果,使用64个样本每提示词的设置。
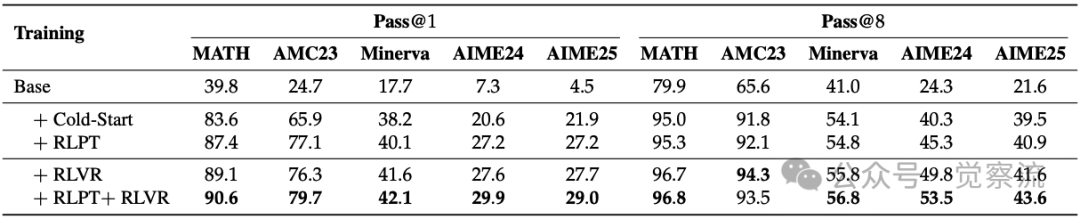
数学推理基准上的性能表现
上表展示了RLPT在多个数学推理基准上的显著提升。特别值得注意的是AIME24和AIME25数据集上的表现:Pass@1指标分别提升了6.6和5.3个百分点,而Pass@8指标的提升更为显著(分别提升10.9和9.1个百分点)。
AIME(美国数学邀请赛)是高中数学竞赛的最高水平之一,难度远超普通数学课程。Pass@1提升6.6个百分点意味着:原本在15道题中只能正确解答约2.3道(15.3%),现在能解答约3.3道(21.9%)。虽然绝对数量看似不大,但在这种高难度竞赛中,每多解对一道题都可能决定能否进入下一轮比赛。Pass@8指标的更大提升(10.9个百分点)表明RLPT不仅提高了模型生成正确答案的概率,还增强了其探索多种解题路径的能力,这对解决复杂问题至关重要。
扩展性分析揭示了RLPT的另一大优势:训练性能与计算资源之间存在明显的幂律关系。图1展示了随着训练token数量增加,模型在多个基准上的性能提升。
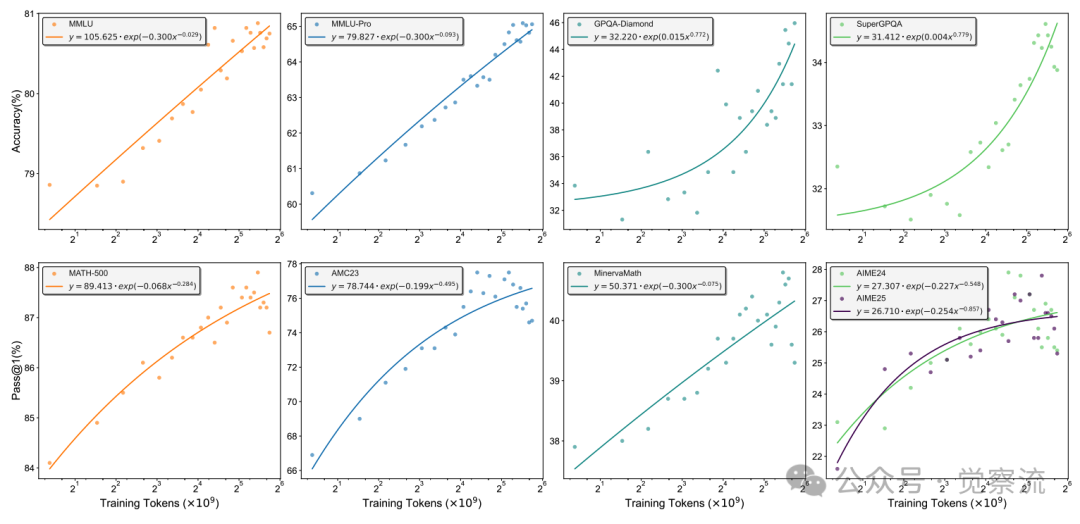
训练token与性能的幂律关系
上图揭示了一个关键发现:随着训练token数量增加,模型性能遵循清晰的幂律关系。以MMLU为例,其性能可精确表示为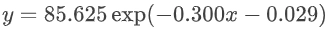 ,其中x为训练tokens数量(单位:10^9)。这种可预测的扩展行为表明,RLPT具有明确的持续改进路径——只要增加计算资源,性能就能按预期规律提升。
,其中x为训练tokens数量(单位:10^9)。这种可预测的扩展行为表明,RLPT具有明确的持续改进路径——只要增加计算资源,性能就能按预期规律提升。
思维过程分析进一步揭示了RLPT的工作机制。研究者提供了一个示例,展示了模型如何通过结构化序列处理next-segment reasoning任务:首先抽象先前上下文以捕捉整体流程,然后确定后续步骤,形成候选延续,验证其合理性,探索替代可能性,必要时进行回溯,最终产生最终答案。这种结构化轨迹与LLM在复杂问题解决中表现出的多步推理策略一致,解释了RLPT的有效性。
与SFT的对比实验表明,RLPT在泛化能力上具有明显优势。研究表明,监督微调往往促进表层记忆而非深度泛化能力,而RLPT通过自主探索有意义的轨迹,培养了更强的泛化能力。RLPT与SFT代表了两种截然不同的学习范式:探索vs记忆。监督学习促使模型记忆输入-输出对,而RLPT鼓励模型探索多种可能的推理路径,选择那些能产生与参考文本语义一致的响应。这种探索过程模拟了人类学习中的"思考-验证-修正"循环,使模型能够发展出更稳健的推理能力。
此外,RLPT为后续的RLVR(Reinforcement Learning with Verifiable Rewards)提供了坚实基础,进一步扩展了LLM的推理边界。当RLPT与RLVR结合时,在AIME24和AIME25上的Pass@1分别达到29.9%和29.0%,显著优于单独使用RLVR的结果。这种组合策略充分利用了两种方法的优势:RLPT提供广泛的推理能力基础,而RLVR则针对特定任务进行精细优化。
深层讨论:RLPT的理论意义
RLPT为何能更好地挖掘预训练数据的价值?关键在于它能够揭示数据构建中潜在的思维过程。通过生成中间推理内容,RLPT不仅增强了原始数据,还支持更高效的数据学习。这种机制使模型能够从相同数据中提取更深层次的知识,突破了传统监督学习的表层记忆局限。
从本质上讲,RLPT与监督微调代表了两种截然不同的学习范式:探索vs记忆。监督学习促使模型记忆输入-输出对,而RLPT鼓励模型探索多种可能的推理路径,选择那些能产生与参考文本语义一致的响应。这种探索过程模拟了人类学习中的"思考-验证-修正"循环,使模型能够发展出更稳健的推理能力。
RLPT为RLVR提供了理想的训练基础。研究表明,当RLPT作为RLVR的预训练阶段时,模型在数学推理任务上的表现进一步提升。这表明RLPT培养的基础推理能力可以被更专业的奖励机制进一步精炼,形成能力提升的层次递进效应。这种组合策略充分利用了两种方法的优势:RLPT提供广泛的推理能力基础,而RLVR则针对特定任务进行精细优化。
从数据效率视角看,RLPT显著提升了训练数据的利用效率。通过让模型主动探索和验证其推理过程,相同数量的预训练数据能够产生更多的学习信号。研究表明,RLPT生成的推理轨迹比原始文本包含更丰富的语义信息,使模型能够从更少的数据中学习到更复杂的推理模式。
RLPT保持与原始策略分布的接近性,这也是其增强泛化能力的关键因素。与依赖人类标注的方法不同,RLPT的奖励信号直接来自预训练数据本身,从而确保策略更新不会过度偏离原始分布。这种接近性使模型能够保留预训练阶段获得的广泛知识,同时增强其推理能力,避免了“灾难性遗忘”问题。
RLPT的发展方向
尽管RLPT已取得显著成果,但其发展仍有广阔空间。在片段分割策略方面,目前主要采用基于NLTK的句子级分割,但研究者已进行初步尝试,探索使用LLM提取文本中集成的原子步骤作为分割单元。虽然这些方法尚未显示出比句子级分割的明显优势,但更精细的分割策略可能进一步提升RLPT的效果。
与测试时扩展方法的协同是另一个有前景的方向。测试时扩展通过在推理过程中分配更多计算资源(如生成更长的推理链)来提升性能,而RLPT则在训练时扩展模型能力。这两种方法可能产生互补效应:RLPT训练的模型可能更有效地利用测试时扩展,从而实现性能的进一步提升。例如,RLPT训练的模型在进行思维链推理时,可能更少出现逻辑跳跃,从而从更长的推理链中获得更多收益。
探索其他自监督RL目标也是未来研究的重要方向。当前的next-segment reasoning关注文本片段的预测,但可能还有其他有价值的自监督信号,如逻辑一致性、多步推理连贯性等。这些新目标可能进一步丰富RLPT的学习信号,提升模型的推理能力。
RLPT在不同规模模型上的适应性与可扩展性值得关注。虽然目前实验主要集中在中等规模模型(如Qwen3-4B)上,但研究者推测RLPT的效果可能随模型规模增大而增强。探索RLPT在超大规模模型上的表现,以及如何针对不同规模模型调整训练策略,将是未来研究的重要课题。
奖励模型设计仍有优化空间。当前的前缀奖励机制已显著优于严格匹配,但更精细的奖励设计(如考虑推理步骤的逻辑连贯性、创新性等)可能进一步提升RLPT的效果。此外,动态调整奖励权重以适应不同训练阶段的需求,也是值得探索的方向。
总结:训练范式的根本性转变
RLPT代表了大模型训练范式的根本性转变:从被动学习到主动探索。这种转变不仅解决了高质量数据有限增长的瓶颈,还为模型能力的持续提升开辟了新路径。通过在预训练数据上进行强化学习,RLPT使模型能够挖掘数据背后的隐含推理过程,从而培养更深层次的泛化能力。
RLPT对模型能力边界的拓展意义深远。它不仅在多个基准测试上取得显著提升,还展示了与计算资源的良好扩展性,预示着随着更多计算资源的投入,模型能力有望持续增强。更重要的是,RLPT为后续的RLVR提供了坚实基础,进一步扩展了LLM的推理边界。
通向更强大、更通用AI的新路径已在RLPT的指引下显现。通过让模型自主探索有意义的推理轨迹,RLPT使LLM能够发展出更接近人类的思维模式,这种能力对于解决复杂问题、进行创造性思考至关重要。RLPT所展示的训练时扩展新范式,为大模型的发展提供了可持续的方向。
让我们回到文章开头的比喻:RLPT就像是教会学生如何思考,而非仅仅记忆答案。在计算资源持续增长而数据资源相对有限的未来,这种从"记忆"到"思考"的转变,不仅将推动技术进步,还可能深刻影响我们理解和构建智能系统的方式。RLPT所代表的主动探索范式,或许正是解锁下一代AI潜力的关键。


