本文将分享传统后台工程师积累的技术栈和方法论,如何延续并迁移到 AI 系统,并系统性拆解 AI Infra 的硬件、软件、训练和推理挑战。
作者 | rayrphuang
AI Infra 和传统 Infra 有什么区别?程序员积累的技术栈和方法论,如何复用到 AI 系统架构设计上?
随着大模型技术的爆发,AI Infra 已成为基础设施领域的核心战场。过去1年多的时间,我们QQ基础架构算法工程团队落地了多个大模型应用,包括语音合成大模型、内容理解多模态大模型、生成式推荐大模型,跑通大模型训练到推理的全链路。踩了很多坑,也积累了不少经验。本文将分享传统后台工程师积累的技术栈和方法论,如何延续并迁移到 AI 系统,并系统性拆解 AI Infra 的硬件、软件、训练和推理挑战。

一、硬件演进
经济基础决定上层建筑。软件层面的架构设计,无法脱离硬件约束。了解现代 AI 硬件特性非常有必要。

一台高性能的GPU服务器可以换一套深圳房子
1. 从CPU为中心到GPU为中心
传统基础设施以 CPU 为核心,通过多线程和微服务构建分布式系统,处理高并发请求(如 Web 服务)。这些都有成熟的方法论了(如"海量服务之道")。主要工作是逻辑事务的处理,瓶颈在网络 I/O 和 CPU 核心数量。发展到今天,硬件已经很少是制约 CPU 系统设计的瓶颈。
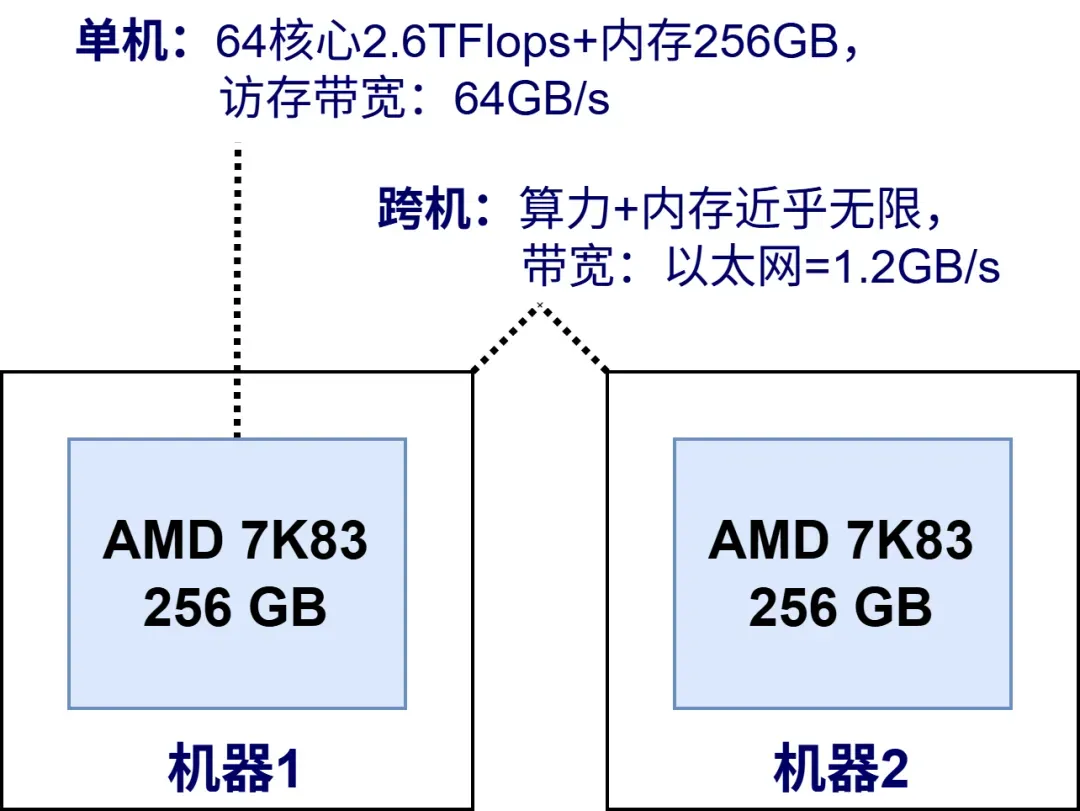
而 AI Infra 以 GPU 为核心,其设计目标从逻辑事务处理转向高吞吐浮点计算。此时CPU 多线程被 GPU 并行计算替代,内存被显存替代。如下图所示,H20单卡96GB显存,可以提供44TFlops的单精度浮点运算,算力和访存带宽是主流CPU数十倍甚至数百倍。每台机器安装8卡=768GB显存,另外还有 CPU 192核384线程 + 2.3TB 内存。
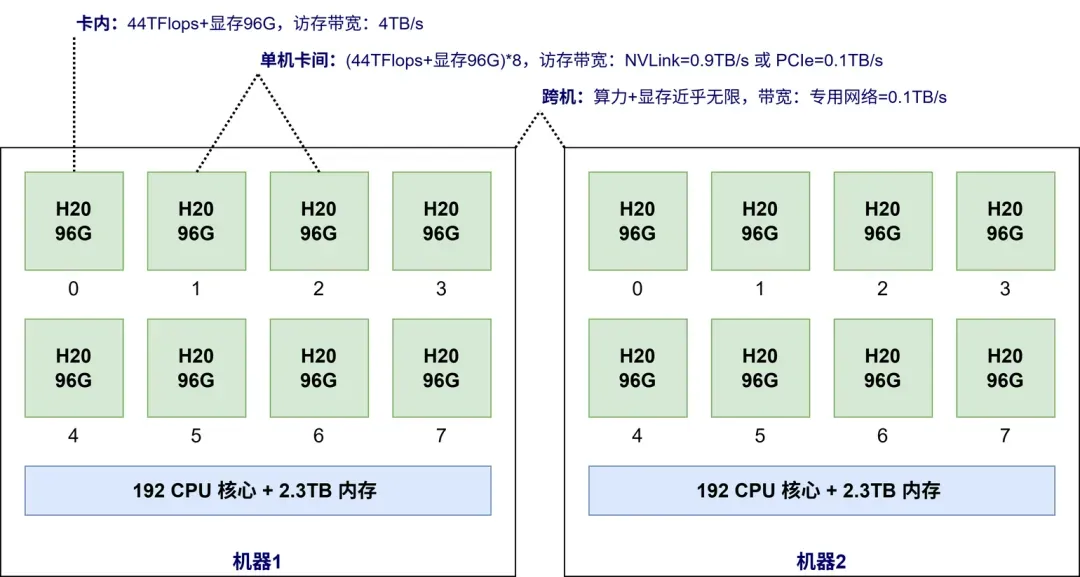
为什么 GPU 会成为核心?是因为 LLM 大模型每次生成一个 token,都需要读取全量的模型参数。传统的 CPU + 内存的算力和带宽无法满足如此恐怖的计算密度,计算和通信都必须转移(offload)到 GPU 内完成。CPU 成为数据搬运工和“辅助处理器”。
为了更直观地理解这个计算密度,我们做一个简单的计算。不考虑计算的延时,LLM 大模型生成一个 token 的耗时公式计算为:

以 DeepSeek-R1-671B-A37B-FP8 模型为例,计算一个 token 耗时,H20 为 37B × 1byte ÷ 4000GB/s = 9ms,如果是 CPU 则为 37B × 1byte ÷ 64GB/s = 578ms。
2. 从"去IOE"到"AI大型机"
显而易见,我们的现在身处新的一轮烈火烹油的硬件革命的历史进程中,各种专用硬件、专用网络层出不穷。DeepSeek-R1 和 QWen3-235B 千亿级参数训练需千卡 GPU 集群协同,通过专用网络互联构建“AI超算”,其设计逻辑与以前的 IBM 大型机惊人相似——以硬件集中化换取极致性能与可靠性。

IBM大型机
传统 Infra 的分布式理念貌似在 AI 时代失效了。传统 Infra 追求横向扩展,而 AI Infra 呈现 “AI 大型机”特性,是因为传统后台服务的可以容忍毫秒级延迟,但 AI 集群不行,GPU 的算力是 CPU 的数百倍,微秒级的延时等待也会造成很大的算力损耗,需要硬件的高度集成。在可预见的1-3年的未来,这样的专用硬件+网络的集中式架构很难发生比较大的改变。
回顾历史,我们总是在寻求科技平权。前人推动“去IOE”(IBM小型机、Oracle数据库、EMC存储),用分布式廉价x86 pc机替代集中式高端硬件,本质上是利用软件创新重构一个高可用+低成本的互联网基础设施。"AI大型机"是技术发展必由之路,但不是终极形态。长期(5年)来看,必然会出现 "AI 去 NVIDIA 化",重演“去 IOE”的历史。
二、软件演进
说完硬件体系的革命,接下来再关注下软件层面的变化。
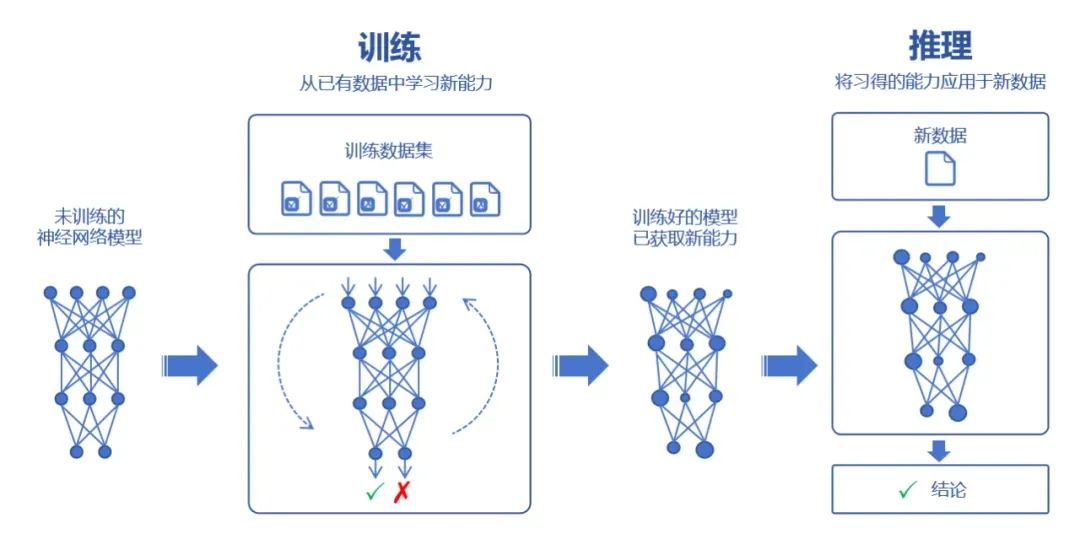
相比传统后台应用的增删查改,AI 应用的新范式是模型训练和推理。模型训练是指通过海量数据拟合出一个复杂的神经网络模型,推理就是利用训练好的神经网络模型进行运算,输入的新数据来获得新的结论。
举个例子,训练就是根据 <年龄, 身高> 的分布使用最小二乘法拟合模型 y = ax + b,推理就是利用这个模型 y = ax + b,输入一个新的年龄,预测身高。
1. 深度学习框架
工欲善其事,必先利其器。传统后台应用依赖 tRPC 或 Spring 等微服务框架,帮助我们屏蔽负载均衡、网络通信等底层细节,我们可以把精力放在业务实现上。
与之相似,AI 应用则依赖深度学习框架。如果没有深度学习框架,我们就可能陷入在茫茫的数学深渊中,挣扎于痛苦的 GPU 编程泥潭里。有了深度学习框架,我们才可以把所有精力花在设计模型和创新本身上,而不用关注底层的实现细节,极大降低了 AI 应用的门槛。
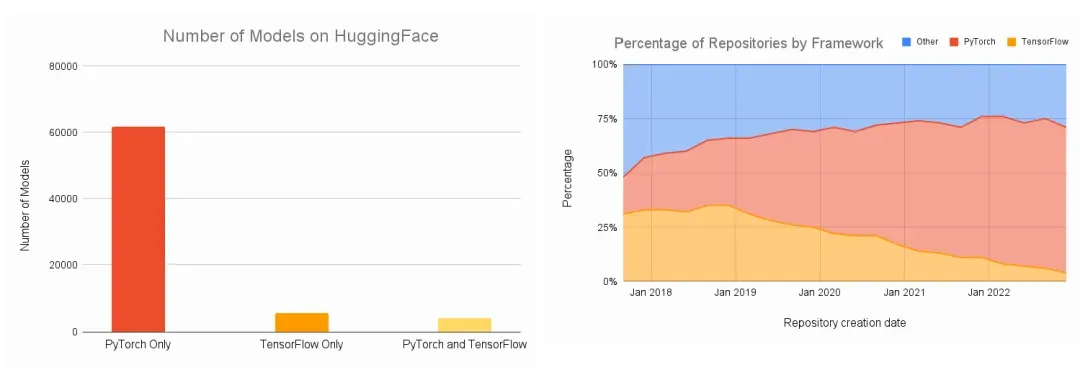
大家可能听说过不同的深度学习框架——Tensorflow,PyTorch。现在是2025年,不用纠结选哪个,因为 PyTorch 就是 AI 模型训练、推理的深度学习框架的事实标准。开源模型和代码都是 PyTorch 一边倒。
得益于动态计算图、自动微分和丰富的 Tensor 操作算子,PyTorch 能帮助我们快速实现模型设计。如下图所示,只需要描述模型结构+待学习的网络参数,不需要关心数学计算和 GPU 编程的细节。

2. GPU 编程
绝大部分的 AI 应用,的确不需要我们手写数学计算的 GPU 代码。但为了满足模型创新的需求,有必要学习 GPU 编程。例如 Meta 发布的 HSTU 生成式推荐模型,核心的 hstu_attn 计算,如果直接用 PyTorch 框架算子组合实现,则时间复杂度为 O(M * N²) ,其中 M 和 N 是一个数量级,相当于O(N³) 。但是通过自定义内核,可以优化到 O(N²)。
在 GPU 核心上运行的代码片段称为内核(kernel)。编写高性能的 CUDA 内核需要丰富的经验,并且学习曲线陡峭。因为我们习惯于传统 CPU 编程处理串行的计算任务,通过多线程提高并发度。而 GPU 采用 SIMT 架构,有大量计算单元(CUDA Cores)和数万个线程,但是被分组后的线程同一时刻只能执行相同的指令。这与传统CPU的串行思维、不同线程处理不同任务,存在根本性冲突,导致 GPU 编程学习难度大。

现实生活中的SIMT架构
现在推荐使用 Triton 编程语言完成 GPU kernel 的开发,它提供类似 Python 的语法,无需深入理解 GPU 硬件细节(如线程调度、共享内存管理),而且和 PyTorch 深度学习框架的生态结合更好。推荐这个 Triton-Puzzles-Lite 项目用作 Triton 的入门学习。
3. Python 编程
正如客户端开发离不开Kotlin/Objective-C,AI Infra 的编程第一公民就是 Python。PyTorch 深度学习框架的设计哲学强调 Python 优先 。
以前大部分模型还可以轻松导出 ONNX、TorchScript 等用 C++ 部署,现在随着对模型的细粒度优化和控制越来越多,比如 KV Cache、MoE/模型并行、复杂的if/for控制流、自定义 Triton 算子等,模型越来越难以脱离 Python 的控制部署。笔者也从“C++ Boy”变成“Python Boy”。
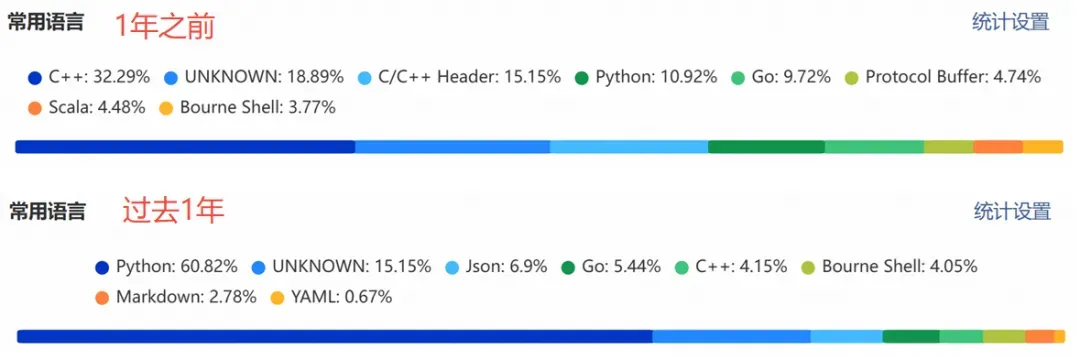
笔者git提交的语言统计变化
三、模型训练的挑战
我们一直追求更大的模型,DeepSeek-R1 有数千亿参数,使用了数十万亿 token 的训练数据,涉及算力、存储、通信等多维度的工程挑战。有了 PyTorch 深度学习框架,只是 AI 应用落地的万里长征第一步。接下来我们将讨论深度学习框架之上的模型训练的挑战。
1. 存得下
DeepSeek-R1 模型大小=670GB,而一台 GPU 服务器有8张H20卡,提供768GB显存,足够存下一个完整的 DeepSeek 模型。那整个行业为什么还投入大量的人力物力,顶着通信延时造成的算力损耗,也要建设分布式 GPU 集群?核心原因是单台 GPU 服务器“存不下”。
(1) 显存刺客:中间激活
如下图所示的模型,x1/x2/x3/x4 这些中间变量就是"中间激活"。它们是神经网络前向传播(Forward)的“堆栈帧(Stack Frame)”——记录每一层处理后的数据快照,确保反向传播(Backward)可回溯梯度,根据预测误差调整模型权重,最小化损失函数。
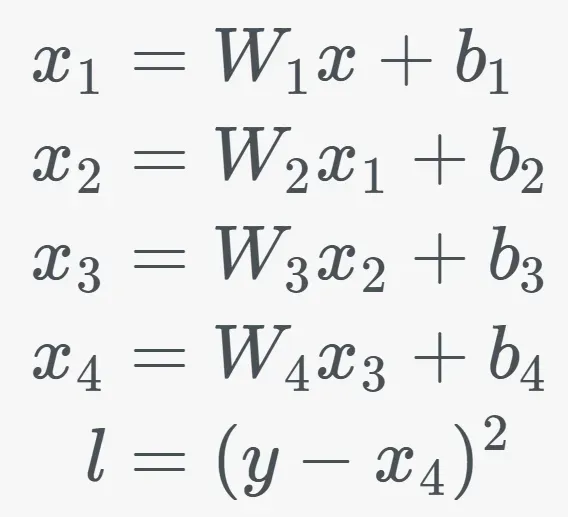
这些中间激活为什么会成为"显存刺客"?是因为中间激活的空间复杂度是和输入数据长度正相关的,特别的,对于 LLM 来说是O(N²)正比于输入数据长度的平方,这是一个指数爆炸式增长的数字。类似函数递归不断增长的“堆栈帧”导致的内存溢出,我们遇到了 AI Infra 的 OOM(Out of Memory)挑战。
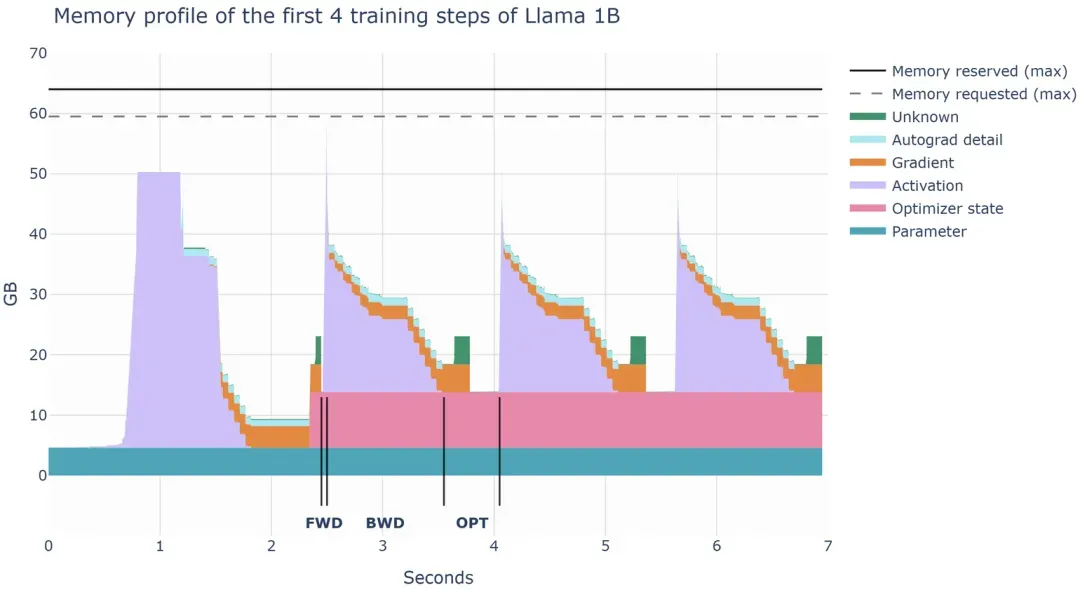
借助 PyTorch 的 profiler 工具,我们可以直观地看到这个OOM。下图是训练过程中不同阶段的显存分配,包括模型参数(Parameter)、优化器状态(Optimizer state)、中间激活(Activation)、梯度(Gradient)。在前向传播结束后出现一个显存占用(中间激活)的尖峰,远大于模型参数本身。
(2) 模型并行
传统后台服务使用分片(Sharding)策略解决单机存不下的问题。与之相似,AI Infra 提出“模型并行”,就是将单个大模型拆分为多个子模块,并分布到不同 GPU 上协同工作,通过通信来共享数据。有不同的“拆分模型”策略,例如按模型模块划分,按张量(Tensor)划分的,也可以将多种拆分方法结合起来一起使用。PyTorch 深度学习框架和开源方案 Megatron 都能帮助我们高效地实现模型并行。
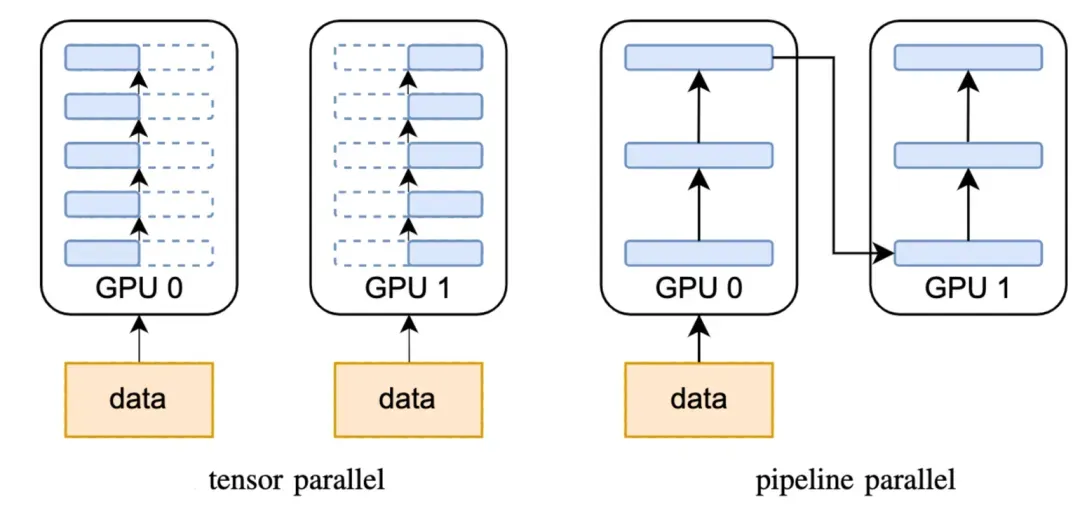
不同的模型并行策略
2. 算得快
建设分布式 GPU 集群的原因,一个是因为“单机存不下”,另外一个是提升训练速度。但简单的机器堆叠,算力不一定有线性的增长。因为分布式训练并不是简单地把原来一个 GPU 做的事情分给多个 GPU 各自做。需要协调多个 GPU 机器计算任务分配,GPU 机器之间的数据传输会引入网络IO和通信开销,降低训练速度。
(1) 通信计算重叠
如下图所示的常规训练时序是串联式的,存在许多网络 IO,GPU 利用率低,训练速度慢。我们希望 GPU 大部分时间都在计算,而不是花在数据传输或等待其他 GPU 的工作上。
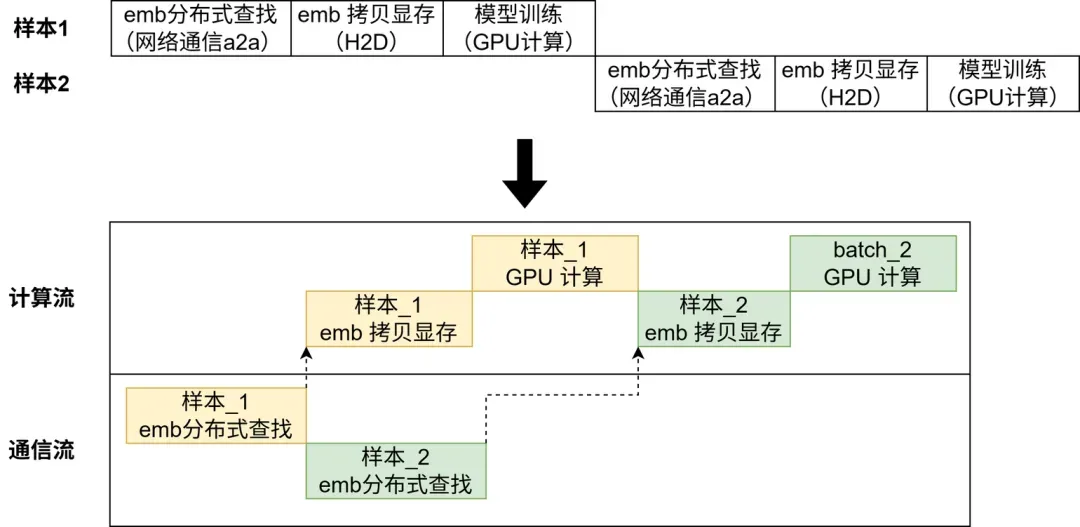
传统后台服务我们通过多线程或异步 IO 避免阻塞 CPU 主线程,与之相似,AI Infra 提出通信计算重叠的方法论。GPU 编程模型中有流(stream)的概念,一个流表示一个 GPU 操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。不同流之间可以并行执行。那么通过令计算和通信操作加入不同的流中,可以做到二者的执行在时间上重叠。例如 TorchRec 的 训练流水线 能帮助我们实现高效的通信计算重叠。
四、模型推理的挑战
AI 模型训练成本很高,优秀如 DeepSeek 也要烧掉500万美金,但再贵也只是一次性的。而模型推理的成本更高,因为用户越多,AI 模型推理次数越多,总成本越高。模型推理面对的挑战和传统 Infra 非常相似,主要是2个挑战:高吞吐(降本),低延时(增效)。
1. 降低延时
现在的 AI 模型越来越多地直面终端用户,需要和用户进行实时的交互,例如文本对话和语音合成。模型推理耗时过高,会直接造成用户体验受损,用户流失与转化率下降。
传统后台服务我们使用链接复用、缓存、柔性等技术降低系统响应时间。AI Infra 也有相似的做法。
(1) CUDA Graph
在 GPU 编程模型中,CPU 和 GPU 是异构的,CPU 通过 API(例如 CUDA API) 向 GPU 提交任务,然后异步等待 GPU 的计算结果返回。GPU 收到任务后,会执行内核启动、内存拷贝、计算等操作。这个过程中,涉及到 CPU 与 GPU 之间的通信、驱动程序的处理以及 GPU 任务的调度等环节,会产生一定的延迟。模型推理需要执行大量重复的 GPU 操作,每个的 GPU 操作都要重复执行上诉环节,这些非核心的 GPU 开销会成倍数地放大,影响最终响应时间。
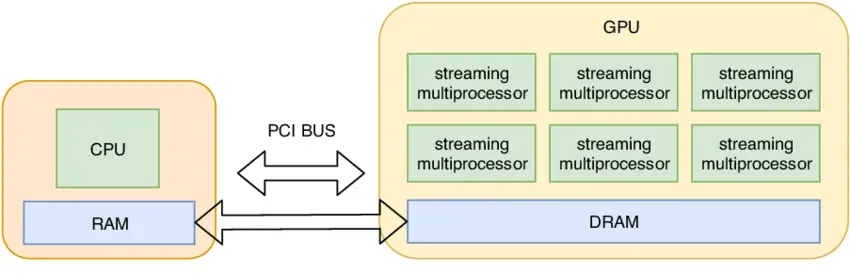
CPU 和 GPU 通信
在传统后台服务,我们使用 Redis 的 Lua 脚本封装多个 Redis 操作和计算逻辑,一次提交,减少网络开销。与之相似,AI Infra 利用 CUDA Graph 技术将多个 GPU 操作转化为一个有向无环图(DAG),然后一次性提交整个 DAG 提交到 GPU 执行,由GPU自身来管理这些操作的依赖关系和执行顺序,从而减少 CPU 与 GPU 之间的交互开销。
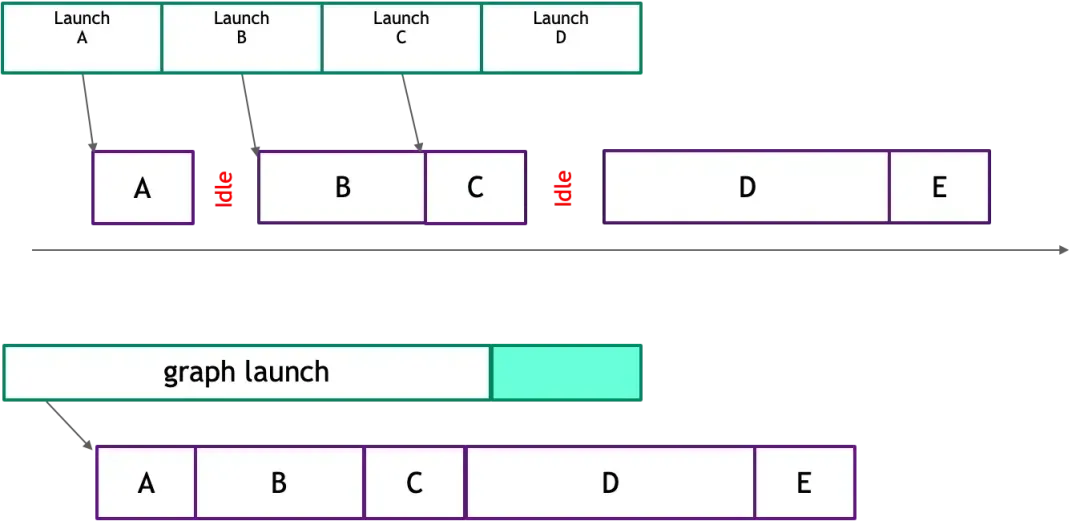
多个 GPU 内核启动转化为 CUDA Graph
(2) KV Cache:空间换时间
LLM 大模型推理存在大量矩阵乘法运算,且高度依赖上下文信息。每次推理都需要将之前生成过的词重新输入模型进行计算。这种计算方式使得复杂度达到了 O(N²),其中必然存在大量的重复计算。
例如,给定“天气”,模型会逐个预测剩下的字,假设接下来预测的两个字为“真好“。
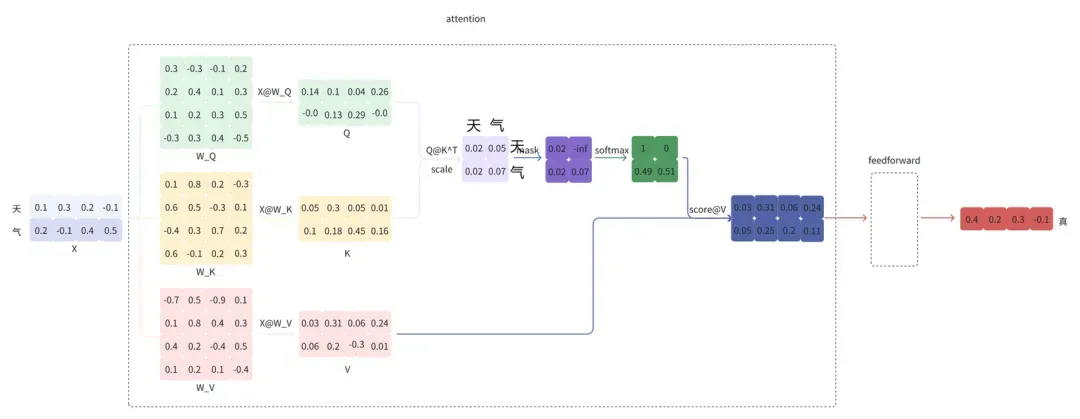
将”真“拼接到”天气“的后面,即新的输入为”天气真“,再预测”好“
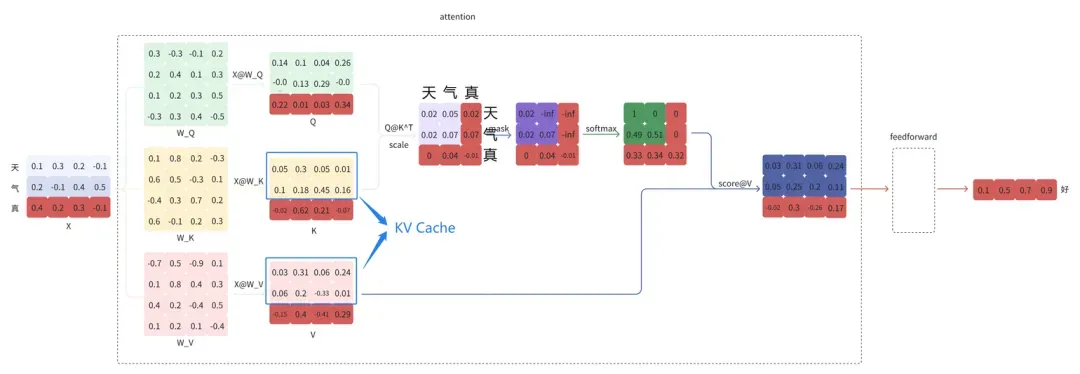
观察到,经过多次预测后,X @ W_K 和 X @ W_V 的结果上半部分都是相同的。这是由于 LLM 模型结构的特殊设计导致的。这些重复计算的结果可以缓存(即 KV Cache)下来,空间换时间,减少计算量。几乎所有的 LLM 推理框架都支持了 KV Cache,例如vLLM 。
(3) 流式响应
有时候模型推理延时实在避免不了,可以从工程交互上想办法。传统后台服务的 RPC 通信是一问一答方式,这种方式不太适合语音合成或者文本对话的场景。因为大模型推理需要几秒-几十秒,如果等待模型推理结束才展示结果,用户会等待较长的时间,体验很差。
流式响应就是当模型推理计算得到第一个token或者第一个音频帧的时候,立马展示或者播放给用户,同时后续的模型推理结果在已经建立的 TCP 流上继续顺序传输。工程上从关注模型推理的整体耗时,改为关注首token或首个音频帧的耗时。几乎所有的 LLM 推理框架都支持了流式响应。
2. 提高吞吐量
提高吞吐量是程序员在传统 Infra 领域孜孜不倦的追求,因为更高的吞吐量意味着更低的机器成本。实现 AI 应用的高吞吐本质上就是提高昂贵的 GPU 的利用率,让 GPU 单位时间能完成更多的任务。
尽管模型推理需要执行万亿次浮点运算,但 GPU 有大量的计算单元(CUDA Cores),单个请求的模型推理很难令 GPU 利用率达到饱和。提高 GPU 利用率有2个方法:传统批处理和连续批处理。这里的“传统批处理”是相对于“连续批处理”这样的新型批处理方式而言的。
(1) 传统批处理
其实传统后台服务也大量使用了批处理,例如 Redis 的 MGet 命令,单次请求就完成所有 key 的获取,将 N 次网络往返(RTT)压缩为1次。与之相似,模型推理的批处理就是将多个输入样本打包(batch),将原本串行的 N 次轻量的推理计算,合并为 1 次重量的计算,实现单位时间内处理更多的请求,提高了 GPU 利用率。
“打包输入样本”是一个共性需求,大部分推理框架都提供该功能,例如 Triton Inference Server 的 Batcher 。
(2) 连续批处理
传统批处理类似 “固定班次的公交车”:乘客(请求)必须等待发车时间(组建一个batch),发车后所有乘客同步前进。即使有乘客提前下车(短请求完成),车辆仍需等待所有乘客到达终点(长请求完成)才能返程接新乘客。传统批处理存在着资源浪费:GPU 要等待长请求处理完,不能处理新的请求而空闲。
这个问题在 LLM 应用领域显得特别突出,因为不同用户请求 Prompt,模型的回答结果长度差异巨大,如果使用传统批处理,GPU 空闲率很高。这个本质上是个任务调度问题,传统后台服务我们使用工作窃取算法(work stealing)解决线程空闲问题,与之相似,AI Infra 提出“连续批处理”解决这个问题。
连续批处理类似“随时随地拼车的顺风车”,每辆车(GPU)在行程中可随时上/下客。新乘客(请求)直接加入当前车辆的空位(空闲计算单元),已完成的乘客立即下车(释放资源)。几乎所有的 LLM 推理框架都支持了连续批处理能力,例如 vLLM 的 Continuous Batching
五、结语
AI Infra 面对的工程挑战,例如计算、存储、通信,大部分是新时代的老问题,我们在传统 Infra 领域都能找到对应的场景和解决思路。差异只在于战场从 CPU 转移到 GPU,传统后台工程师积累的方法论,依然可以无缝衔接到 AI Infra。


