作者丨齐铖湧
编辑丨马晓宁
世界模型的研究尚处于起步阶段,共识尚未形成,有关该领域的研究形成了无数支流,过去一年多,Sora为代表的视频生成模型,成为继大语言模型(LLM)后新的学术热点。本质上讲,当下火爆的视频生成模型,是一种世界模型,其核心目的是生成一段逼真、连贯的视频。
要达到这样的目的,模型必须在一定程度上理解这个世界的运作方式(比如水往低处流、物体碰撞后的运动、人的合理动作等)。
胡文博正是世界模型研究领域近两年的绝对新锐。
以下是具体内容,AI科技评论做了不改变原意的编辑和整理。
感谢邀请和介绍,我今天分享的题目是《迈向三维感知的视频世界模型》(Towards 3D-aware Video World Models)。
之所以讲这个,是因为Sora在2024年初出来时,给大家带来很大震撼。比如它生成的视频,虽然看起来是二维的,但已经具备一定的3D一致性。不过从我们做三维重建的角度看,比如尝试把它重建出来,会发现墙面与地面的垂直性、平整度等都还不够好。

基于这个观察,领域内认为视频扩散模型有潜力作为世界模型的一种表示方式,但视频本身仍是二维的,而我们的世界是三维的。
所以我们思考:如何实现一个具备三维感知能力的视频世界模型?
为了实现这种三维感知,我们主要做了两方面工作,今天重点讲第二方面。
第一方面是如何从二维观测中重建三维信息,这部分和前面彭老师讲的内容比较接近。第二方面是如何将重建得到的三维信息融入到生成过程中,使二维空间的视频扩散模型具备三维感知特性。
我先简单介绍一下第一方面的工作:如何在开放世界环境中,从二维视频中重建三维信息。
我们做了一系列工作,例如video depth (DepthCrafter)(2024年10月挂在arXiv上,现在效果可能已经不是最新的了)。
除了video depth (DepthCrafter),我们进一步思考:既然video depth还是2.5维的信息,能否直接从视频中估计点云。这就是GeometryCrafter,有了点云,我们就能做类似4D重建的任务,把各帧融合到同一坐标系中。
再进一步,我们还估计了运动信息,这部分我们最新的工作叫Holi4D,可以从单目视频中重建运动。最后一块是表面法线估计NormalCrafter,与前几项相比,法线包含更多高频细节,因为它是位置的一阶偏导数。基于法线我们可以做重打光、材质编辑等任务。
总的来说,目前从任意开放世界二维视频中重建三维信息的技术已经发展得不错,我们能得到比较好的三维重建结果了。
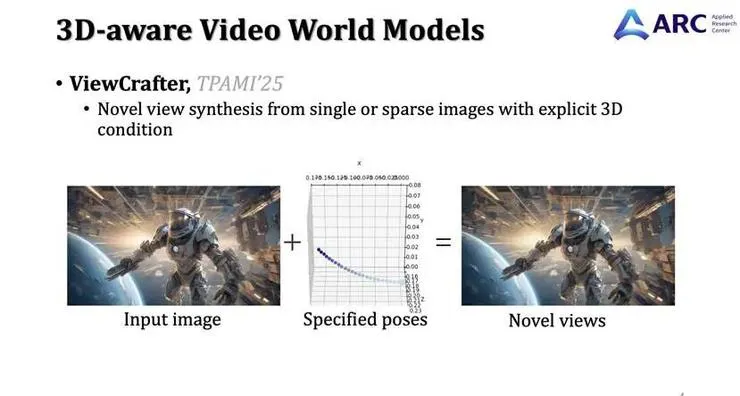
接下来重点讲第二方面:如何将三维信息用在视频扩散过程中,使模型具备三维感知能力。我们首先探索了静态场景下的生成任务:输入一张单图,希望模型能根据任意指定的相机位姿,生成对应的观测图像。这样我们就能像玩游戏一样,通过控制相机,实现对静态场景的探索。
这些空洞正好由擅长内容生成的视频扩散模型来填补。我们将渲染的点云作为条件,控制视频扩散过程,从而生成既逼真又符合指定视角变换的图像。
更重要的是,生成的新图像可以反过来用于多视角重建,更新点云,从而实现迭代式、更大范围的场景探索。这其实与世界模型中的记忆机制相关:三维点云作为一种记忆,通过新探索内容更新点云,再中查询信息作为条件,支持更远的探索。

我们展示一些结果:左侧是指定的相机轨迹,右侧是从单图出发生成的探索结果。
效果还不错,不仅支持单图输入,也支持稀疏多视图输入。从两张图出发的话,探索范围会大很多。探索得到的多视图图像可以直接用于重建三维高斯泼溅模型(3D Gaussian Splatting),实现实时渲染。
刚才讲的是静态场景探索,接下来是如何对动态场景进行探索。这是我们发表在ICCV 2025上的Oral工作TrajectoryCrafter。
核心思想是:用户输入一段单目视频(它是四维世界的二维投影),模型应允许用户对其背后的四维世界进行探索,即同时指定相机位姿和时间点,生成对应的动态观测。
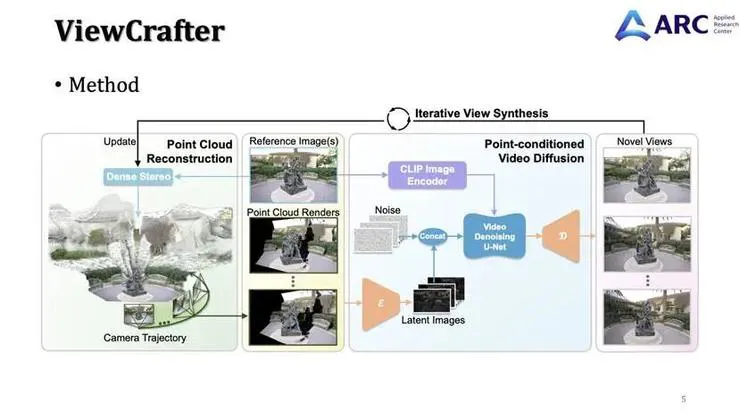
方法延续之前的思路:核心是如何将重建的三维信息注入生成过程。输入是一段视频,我们通过视频重建方法将其提升为三维空间中的动态点云。然后像ViewCrafter一样,基于指定位姿渲染点云。
不同之处在于,动态探索对生成质量要求更高,因此我们除了注入点云信息外,还将原始视频(质量最高)也作为条件注入扩散模型,从而在精准控制相机位姿的同时实现高质量生成。
模型还能实现“子弹时间”特效:固定时间点,旋转相机。另外也能模拟“Dolly Zoom”特效(电影常用手法:边推移相机边调整焦距,使主体大小不变而背景变化),我们的模型可以从原始固定相机视频出发,同时修改相机内参和外参,复现这种效果。
以上两个工作分别实现了对静态和动态场景的探索。
对于世界模型,除了探索,下一步是实现交互:如何对场景中多个物体进行交互?这是我们最新工作VerseCrafter(即将公开)。
实现方案上,我们构建了一个“4D控制视频世界模型”:从单图出发,基于重建和分割方法,重建出部分三维场景,并标注可移动物体。这样就在Blender中得到一个粗糙的、可交互的三维(或四维)世界。虽然粗糙,但易于交互。交互结果作为条件,输入到我们设计的视频扩散模型中,生成最终逼真的观测。
这个方案的关键在于如何构建训练数据。我们建立了一套完整的训练数据标注流程,核心基于重建算法和视觉语言模型(VLM)进行标注与过滤。最终我们获得了约35K个高质量视频片段的数据集。
基于这个模型,我们可以做很多事情:固定相机只移动物体、固定物体只移动相机、同时移动相机和物体。我们对比了现有方案,很多方法只能处理特定类别(如仅限人体),而我们的方法在运动符合度和生成质量上都有不错表现。我们还测试了多玩家联机探索场景的能力:用两个人各自拍摄的照片作为Player A和Player B的视角,让他们在同一个场景中同时探索与交互,模型能分别生成各自的视角视频。
总结一下,今天主要关注第二方面——三维感知视频世界模型,但这部分非常依赖第一方面的开放世界三维重建技术(包括深度、点云、运动、法线等重建)。
在三维感知视频世界模型方面,我们实现了静态场景探索模型、动态场景探索模型,以及支持在四维场景中同时进行探索与交互的模型。
这就是今天想和大家分享的内容,谢谢。


