
基于一致性模型(Consistency Models, CMs)的轨迹蒸馏(Trajectory Distillation)为加速扩散模型提供了一个有效框架,通过减少推理步骤来提升效率。然而,现有的一致性模型在风格化任务中会削弱风格相似性,并损害美学质量 —— 尤其是在处理从部分加噪输入开始去噪的图像到图像(image-to-image)或视频到视频(video-to-video)变换任务时问题尤为明显。这一核心问题源于当前方法要求学生模型的概率流常微分方程(PF-ODE)轨迹在初始步骤与其不完美的教师模型对齐。这种仅限初始步骤对齐的策略无法保证整个轨迹的一致性,从而影响了生成结果的整体质量。为了解决这一问题,文章提出了单轨迹蒸馏(Single Trajectory Distillation,STD),一个从部分噪声状态出发的训练框架。为了抵消 STD 引入的额外时间开销,文章设计了一个轨迹状态库(Trajectory Bank),预先存储教师模型 PF-ODE 轨迹中的中间状态,从而有效减轻学生模型训练时的计算负担。这一机制确保了 STD 在训练效率上可与传统一致性模型保持一致。此外,引入了一个非对称对抗损失(Asymmetric Adversarial Loss),显著增强生成结果的风格一致性和感知质量。在图像与视频风格化任务上的大量实验证明,STD 在风格相似性和美学评估方面均优于现有的加速扩散模型。
论文地址:
https://arxiv.org/abs/2412.18945
项目主页:
https://single-trajectory-distillation.github.io/
项目Github:
https://github.com/dynamic-X-LAB/Single-Trajectory-Distillation
项目模型:
https://huggingface.co/Single-Trajectory-Distillation/Single-Trajectory-Distillation
小红书 AIGC 团队提出风格迁移加速算法,入选 ACM MM 2025。
论文标题:
Single Trajectory Distillation for Accelerating Image and Video Style Transfer
01、背景
扩散模型在图像和视频风格化任务中表现出强大的生成能力,但由于其依赖多步推理过程,推理速度较慢,难以满足实际应用需求。近年来,一致性蒸馏(Consistency Distillation, CMs)方法通过减少推理步数实现加速,取得了一定效果。然而,现有一致性方法在风格迁移任务中存在明显局限:风格一致性弱,图像质量下降。其根本原因在于现有方法依赖从原始图像  加噪生成的
加噪生成的  ,并从该点出发去拟合教师模型的初始去噪轨迹,导致训练过程仅关注部分路径,且与实际推理中从固定噪声状态开始去噪的流程不一致。
,并从该点出发去拟合教师模型的初始去噪轨迹,导致训练过程仅关注部分路径,且与实际推理中从固定噪声状态开始去噪的流程不一致。
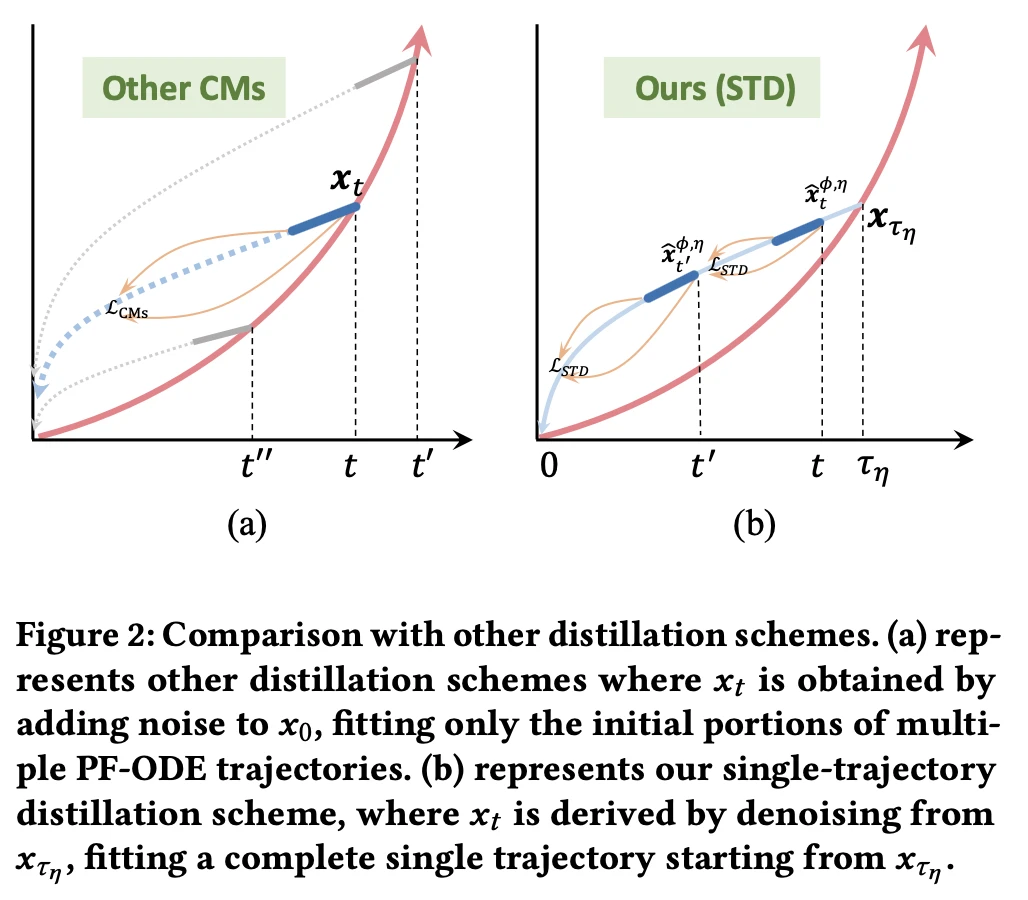
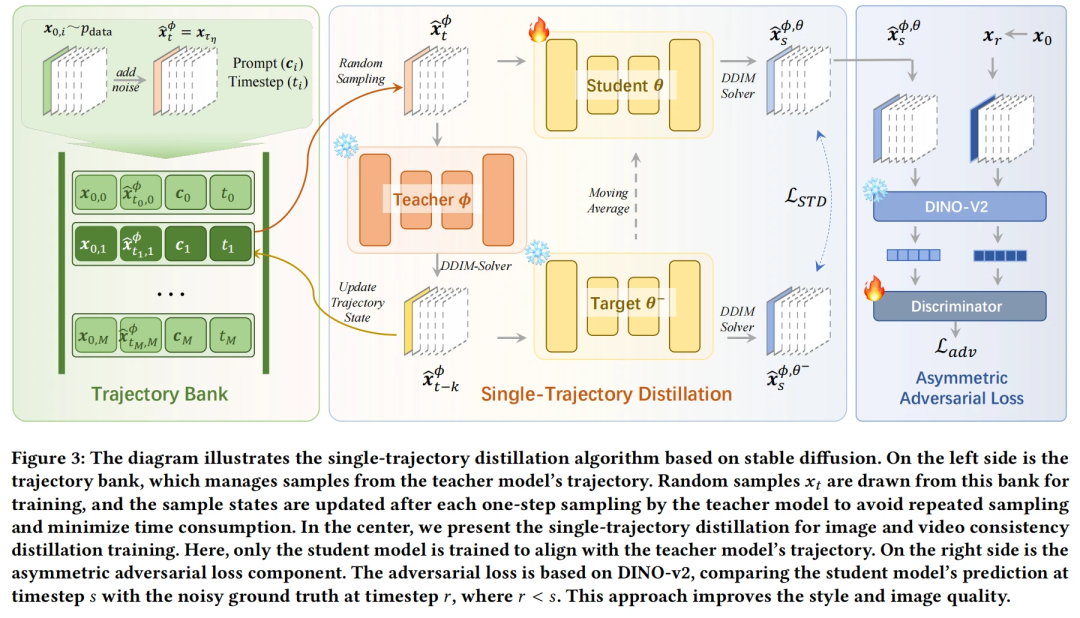
如图 2所示,(a) 中的传统一致性蒸馏方法(Other CMs)从 加噪得到不同的 ,再拟合多条 PF-ODE 轨迹的初始部分,存在轨迹不对齐问题。而在 (b) 中,文章提出的单轨迹蒸馏(Single-Trajectory Distillation, STD)方法则从一个固定的加噪状态  出发,通过教师模型完整地去噪出多个 ,并以此为训练目标,使学生模型在一条完整轨迹上实现自一致性。这种策略有效解决了训练-推理路径不一致的问题,提升了整体生成质量。
出发,通过教师模型完整地去噪出多个 ,并以此为训练目标,使学生模型在一条完整轨迹上实现自一致性。这种策略有效解决了训练-推理路径不一致的问题,提升了整体生成质量。
为了避免从 开始反复推理带来的训练开销,进一步提出了轨迹缓存库(trajectory bank),用于预存教师模型轨迹中的中间状态,从而保持训练效率不变。同时,引入了非对称对抗损失(asymmetric adversarial loss),对不同噪声级别下的生成图与真实图进行对比,有效提升图像饱和度,减少纹理噪声。
文章还构建了图像和视频风格化的标准测试集,并在多项评估指标下验证了 STD 的有效性。实验结果显示,STD 在风格相似性、美学质量和推理效率方面均显著优于现有一致性蒸馏方法。
02、前置理论
扩散模型
扩散模型通过多步噪声叠加模拟数据退化过程,并在生成阶段通过逆向去噪获得真实样本。基于分数匹配理论,前向过程可表述为将数据分布转化为高斯噪声的随机微分方程(SDE): 。
。
Song 等人 [1] 证明存在概率流常微分方程(PF-ODE)与 SDE 具有相同边界概率密度,其形式为
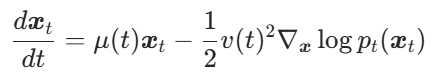
其中 为去噪模型预测的分数项。基于此可发展多种数值解法,包括DDIM-Solver、DPM系列等求解器。
为去噪模型预测的分数项。基于此可发展多种数值解法,包括DDIM-Solver、DPM系列等求解器。
轨迹
在扩散模型中,轨迹直观表征了样本在加噪与去噪过程中的演化过程,但现有研究鲜少明确定义这一概念。本文将轨迹点定义为特定时间步的边界概率密度(可通过样本分布估计),从而支持轨迹样本分布的量化分析。前向扩散 SDE 轨迹可表述为
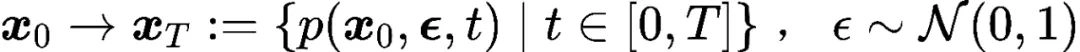
反向扩散轨迹则定义为
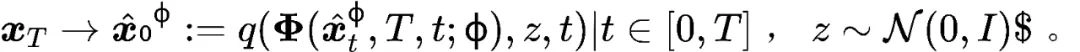
当模型充分预训练且 时,有
时,有 成立,此时
成立,此时 表示带去噪模型
表示带去噪模型 的 ODE 求解器。
的 ODE 求解器。
基于部分加噪的编辑
扩散模型凭借强大的生成能力和多样性,通过部分加噪再去噪已成为图像视频编辑的主流方法。该方法通过保留原始图像部分信息维持主体结构,其中去噪强度 控制编辑程度,对应轨迹可表示为
控制编辑程度,对应轨迹可表示为
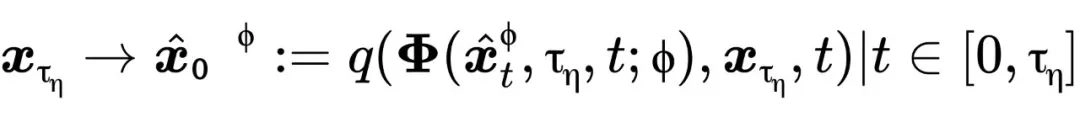
其中
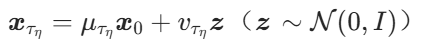

一致性模型
Song 等人提出 [2] 的自一致性模型通过减少推理步数实现加速,其核心在于确保任意时刻的生成函数满足不同时间步  反向扩散到
反向扩散到  的自一致性,即
的自一致性,即
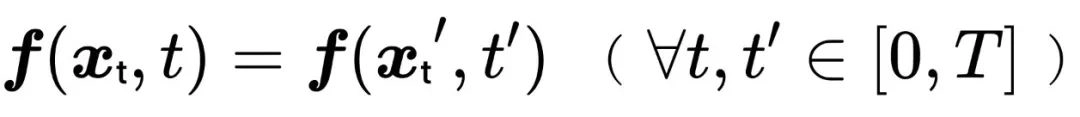
基于蒸馏方法可高效构建一致性模型,其损失函数定义为
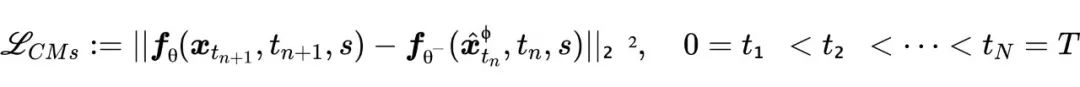
其中  均匀采样于
均匀采样于 ,
, 为目标步长。计算期望时
为目标步长。计算期望时  ,
, 通过 SDE 生成,而
通过 SDE 生成,而 由 ODE 求解器
由 ODE 求解器  确定。为提升训练稳定性,采用EMA策略更新目标网络参数
确定。为提升训练稳定性,采用EMA策略更新目标网络参数 。
。
03、方法

单轨迹蒸馏理论
在扩散模型中,理想情况下反向去噪轨迹应与前向扩散轨迹严格互逆。但实际中,不完美去噪模型会导致:
- 轨迹不一致性:
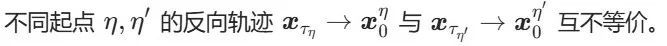
- 误差传播:

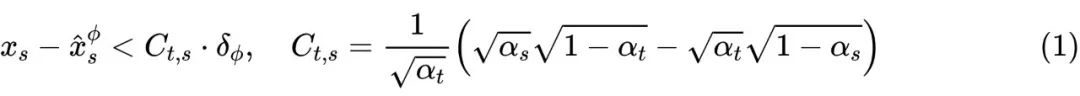
理论推导:
为证明从 SDE 轨迹上两个不同强度点出发的去噪轨迹  和
和  不相同,可转化为证明:轨迹 上的任意点不位于另一条轨迹上。此外,每条去噪轨迹与 SDE 轨迹必然存在唯一交点,即起始时刻
不相同,可转化为证明:轨迹 上的任意点不位于另一条轨迹上。此外,每条去噪轨迹与 SDE 轨迹必然存在唯一交点,即起始时刻  对应的点。因此,只需聚焦于此特定位置,证明轨迹 在 处的点不位于轨迹 上即可。
对应的点。因此,只需聚焦于此特定位置,证明轨迹 在 处的点不位于轨迹 上即可。
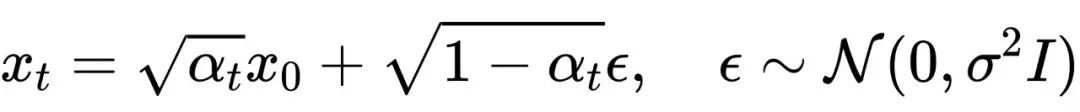
教师模型预测的噪声为 ,其误差满足
,其误差满足 。当教师模型训练完美时,
。当教师模型训练完美时, 。使用 DDIM-Solver 从
。使用 DDIM-Solver 从  时刻去噪至 时刻的过程可表示为:
时刻去噪至 时刻的过程可表示为:
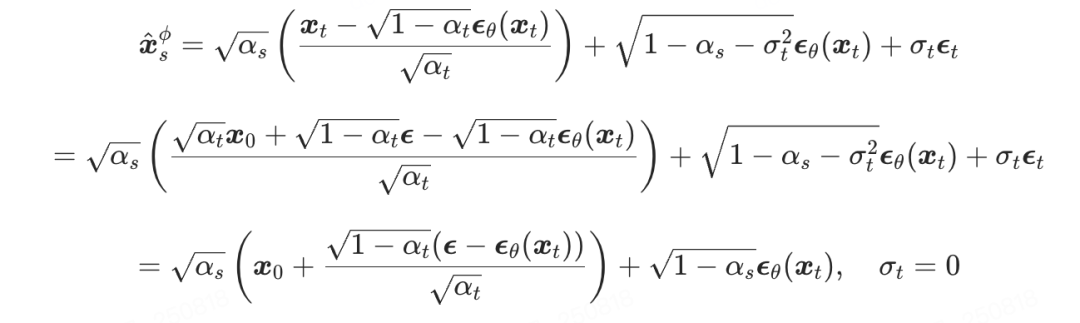
从 加噪到  可以用前向扩散公式表示为:
可以用前向扩散公式表示为:
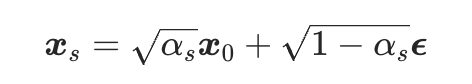
则  和 的差异可以表示为:
和 的差异可以表示为:
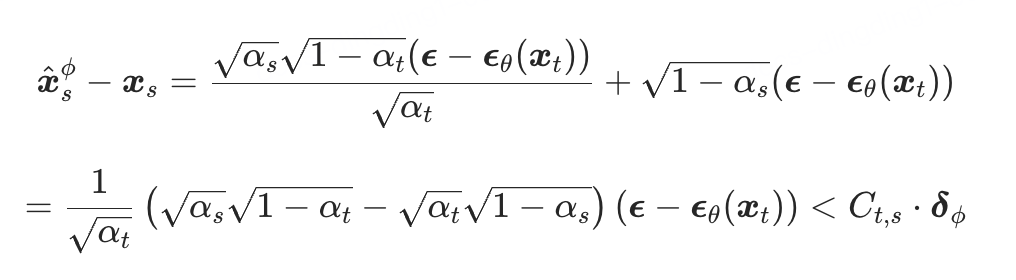
其中
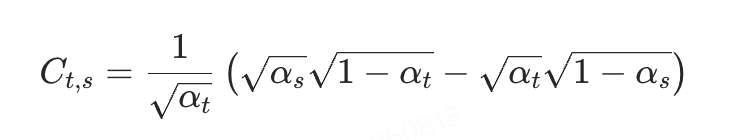
当t和s越接近,误差上界越小。
针对图像/视频风格化任务中固定起点 的需求,提出基于一致性模型仅在固定起点的单条轨迹上做一致性蒸馏,具体包含两个关键点:
- 固定噪声强度起点
 (即
(即  )。
)。 - 使用教师模型
 生成完整轨迹
生成完整轨迹 ,引导学生模型
,引导学生模型  学习该轨迹的自一致性。
学习该轨迹的自一致性。
根据第二部分对轨迹的定义,可以写出单轨迹蒸馏损失函数的表达式如下:
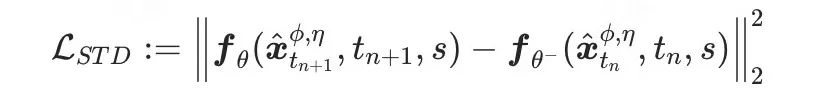
其中
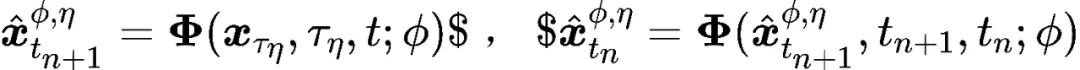
为降低蒸馏误差,约束学生模型学习的时间步 接近教师步 :
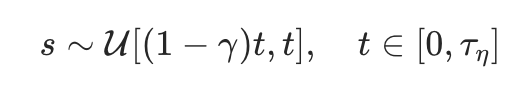
其中  表示控制目标时间步 的取值下限比例因子通过缩短 与 的距离,可以减小误差上界,同时保留随机性提升模型性能。
表示控制目标时间步 的取值下限比例因子通过缩短 与 的距离,可以减小误差上界,同时保留随机性提升模型性能。
轨迹状态库
在 STD 训练过程中,教师模型的全轨迹状态需通过多步 ODE-Solver 进行反向扩散,导致训练耗时显著增加。为解决此问题,提出轨迹状态库(Trajectory Bank),其存储教师模型沿反向扩散轨迹 的中间状态。通过按采样概率
的中间状态。通过按采样概率 从库中随机抽取
从库中随机抽取 ,可直接获取时刻的轨迹状态样本,避免从加噪至
,可直接获取时刻的轨迹状态样本,避免从加噪至 再逐步去噪的高耗时过程。轨迹库定义如下:
再逐步去噪的高耗时过程。轨迹库定义如下:
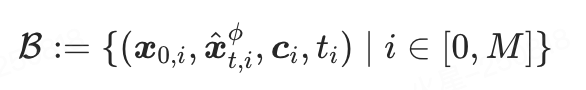
如图3左侧所示,轨迹库从数据集中采样,通过前向SDE加噪至噪声强度得到样本 ,并将样本及其对应提示词
,并将样本及其对应提示词 存入库中。训练时随机从库中采样,经教师模型处理后生成
存入库中。训练时随机从库中采样,经教师模型处理后生成 及对应时间步,替换库中原样本以实现更新。当再次采样到该样本时,直接从
及对应时间步,替换库中原样本以实现更新。当再次采样到该样本时,直接从 推进至
推进至 ,依此类推。当
,依此类推。当 时,将该样本移出库,并加入新的
时,将该样本移出库,并加入新的 。
。
非对称对抗损失
作者观察到一致性蒸馏的图像往往带有比较明显的斑点噪声,有许多方法都用到了对抗损失函数来增加生成的稳定性以及图像质量,其中 Wang 等 [3] 采用整个去噪模型作为判别器,而 Sauer 等 [4] 则使用 DINO-v2 的特征训练一个比较小的判别器。文章选择后者,出于以下两点原因:
- 语义级约束优势:本方法学习轨迹
 的目标分布(非原始数据分布),DINO-v2特征可提供语义约束而非像素级匹配;
的目标分布(非原始数据分布),DINO-v2特征可提供语义约束而非像素级匹配; - 对视频蒸馏更友好:DINO-v2 判别器在视频任务中显存效率更高,支持多帧处理。
受到 MCM 方法启发,提出非对称对抗损失函数。不同于传统方法约束 与真实图像
与真实图像 的匹配,论文中建立
的匹配,论文中建立 与
与 的约束关系(
的约束关系( ),实验发现通过时间步错位可以显著增强图像风格化程度。具体实现:
),实验发现通过时间步错位可以显著增强图像风格化程度。具体实现:
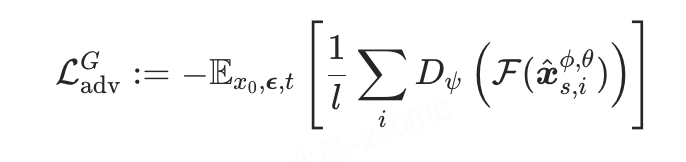
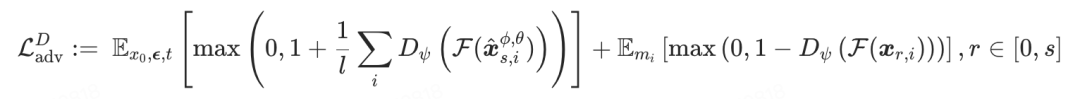
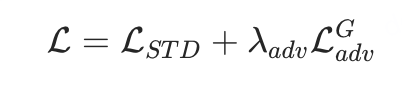
其中  表示DINO-v2模型,
表示DINO-v2模型, 表示判别器,
表示判别器, 表示判别器的可学习参数, 指对 加噪
表示判别器的可学习参数, 指对 加噪  步后获得的样本,其中 从
步后获得的样本,其中 从 s到 的范围内随机选取。
s到 的范围内随机选取。
04、实验
数据集:
- 训练集:Open-Sora-Plan-v1.0.0
- 测试集:wikiArt + COCO + 自定义100张图像/12个视频及15种风格图像的测试集
评估指标:风格相似度(CSD)、LAION 美学评分和时间一致性(Warping Error)指标
对比方法:LCM / TCD / PCM / TDD / Hyper-SD / SDXL-Lightning / MCM
对比实验

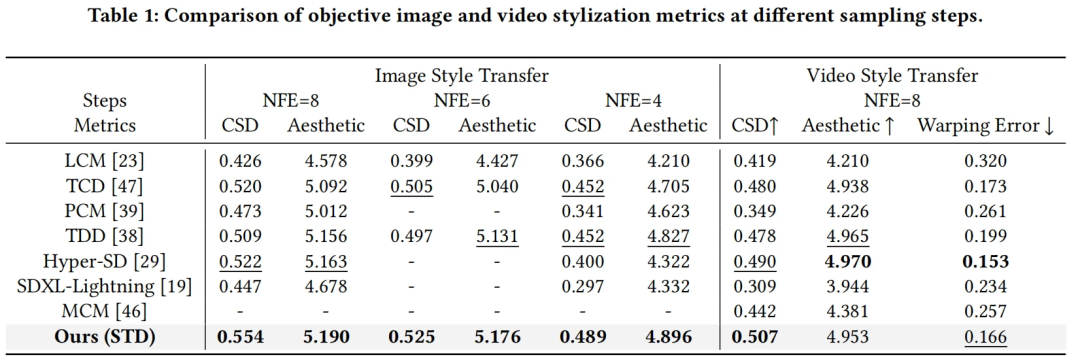
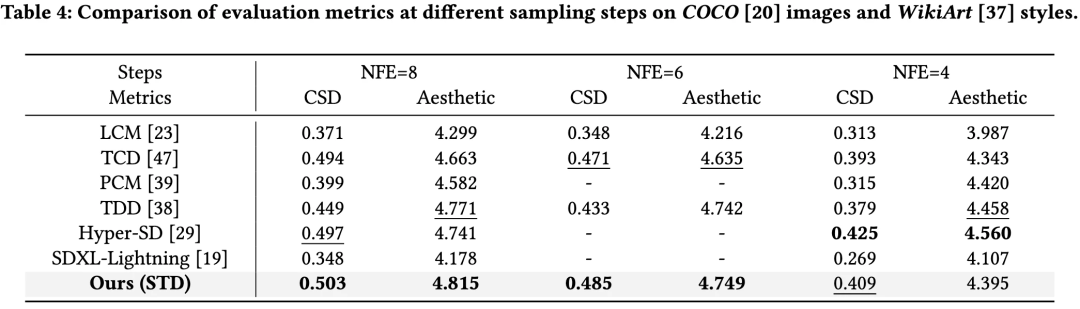
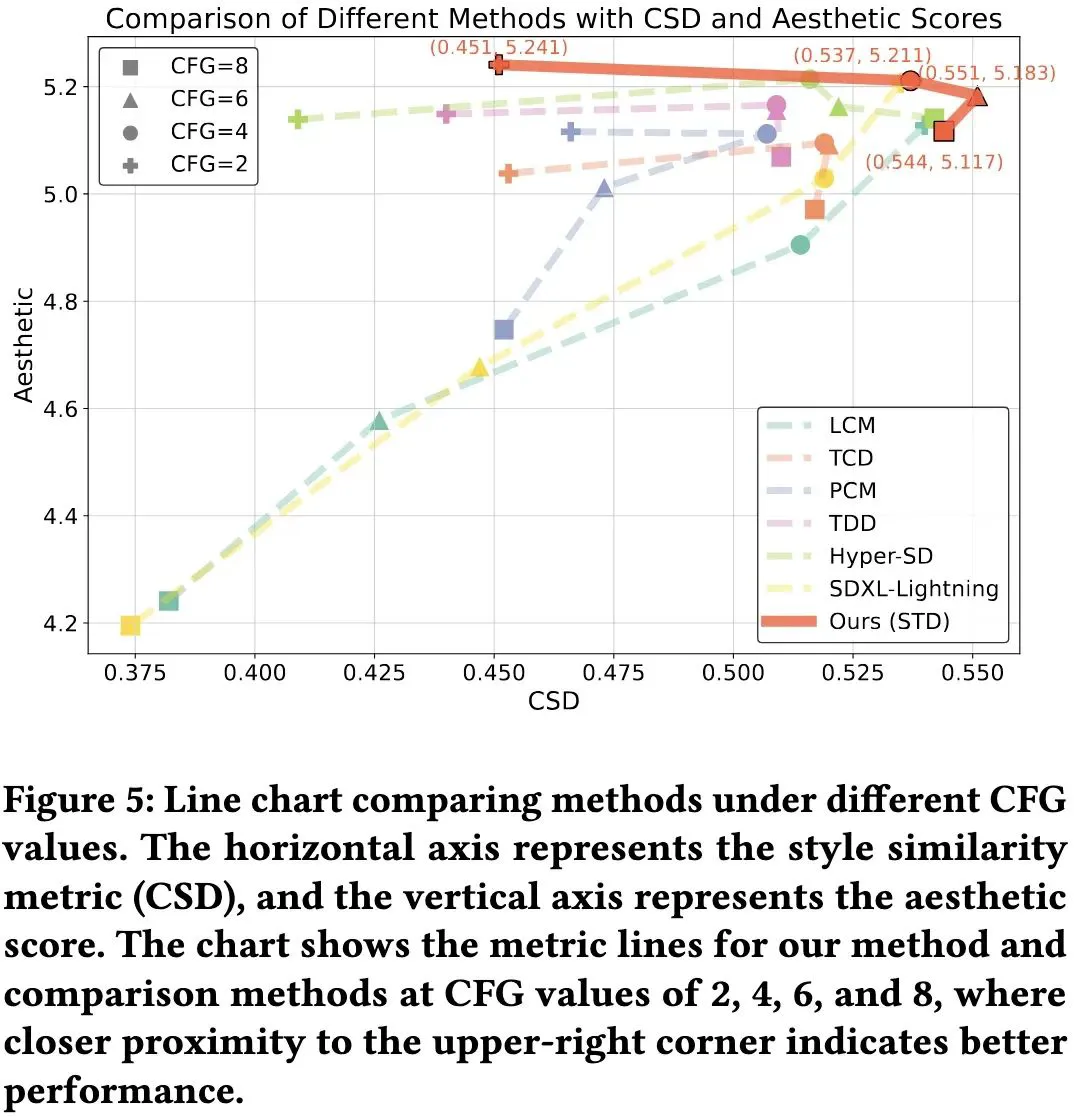
STD 与当前多种加速方法在 8 步、6 步、4 步下进行对比(表1、表4),在风格相似性和美学分数上达到 SOTA 水平。其中图像生成在 NFE=8 时 CSD 分数比Hyper-SD 提升 ↑0.032;视频生成的 warping error 达到 0.166,显著优于 MCM 的 0.257。从可视化(图4)中可以看出 STD 方法的风格质量和图像质量显著更高;在不同 CFG 的定量指标折线图中(图5)也表现出了更优水平。
消融实验
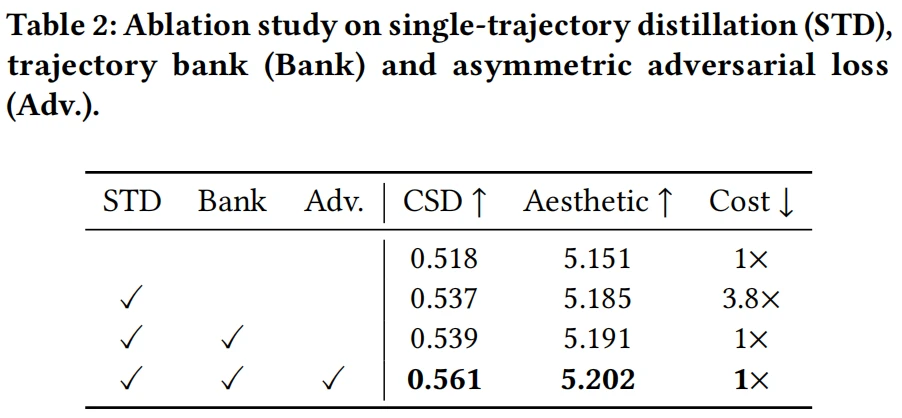
文章对单轨迹蒸馏方法、轨迹状态库以及非对称对抗损失函数做了笑容实验(表2),当使用轨迹状态库时,抵消了 STD 带来的额外 3.8 倍训练耗时,而 STD 方法和非对称对抗损失函数都显著提升了风格相似性分以及美学分。




其他重要参数的取值和特性消融实验:
- STD 和非对称对抗损失强度(图6):强度越大,细节和噪点越少,对比度越强,画质越好;
- 不同的噪声起点(图8): 越大,风格化程度越大,但是内容相关性越弱;
- 不同的目标时间步 的取值下限比例因子(图10):更大的 值带来更低噪声,更强的非对称对抗损失产生更高对比度;
 在风格保持与细节呈现间取得最佳平衡;
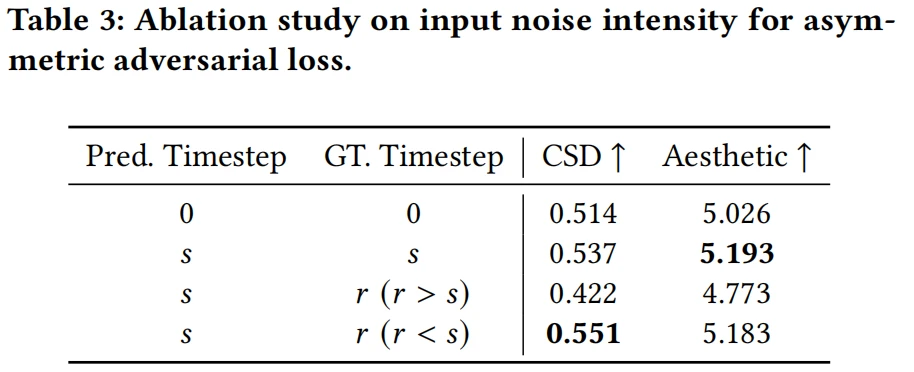
在风格保持与细节呈现间取得最佳平衡; - 非对称对抗损失目标时间步位置(表3、图9):当
 时风格化程度最佳,噪点最少。
时风格化程度最佳,噪点最少。
可扩展性试验

文章进一步讨论了 STD 方法的适用范围,从 STD 的理论推导上看,该方法可用于其他任何“基于部分噪声的图像/视频编辑”任务,如 inpainting 等。为了验证猜想,文章展示了一组使用 STD 和其他加速方法用于 inpainting 的对比图。如图7,相比 LCM 和 TCD 方法,STD 的 inpainting 效果更加自然。
05、结语
文章针对基于一致性模型的图像视频风格迁移加速方法,重点优化了风格相似性与美学质量。研究发现前向 SDE 轨迹中不同噪声强度会导致 PF-ODE 轨迹产生差异,据此提出基于特定噪声强度的单轨迹蒸馏方法(STD),有效解决了训练与推理轨迹不对齐问题。为降低 STD 方法的训练成本,创新性引入轨迹库机制,并采用非对称对抗损失提升生成质量。对比实验验证了本方法在风格保持与美学表现上的优越性,系统消融实验证实了各模块的有效性。该方法可扩展至部分噪声编辑任务,文章已探索了基于 STD 的图像修复应用,未来拟进一步拓展至其他图像编辑任务的加速。期望本研究能为该领域后续工作提供新思路。
参考文献:
[1] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021. Score-Based Generative Modeling through Stochastic Di!erential Equations. In ICLR.
[2] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. 2023. Consistency models. In Proceedings of the 40th International Conference on Machine Learning. 32211–32252.
[3] Fu-Yun Wang, Zhaoyang Huang, Alexander Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. 2024. Phased consistency models. Advances in neural information processing systems 37 (2024), 83951–84009.
[4] Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. 2025. Adversarial di!usion distillation. In ECCV. Springer, 87–103.
06、作者简介
Core Contributors
许思杰
小红书 AIGC 团队算法工程师,在 ACM MM、ICCV 等计算机视觉、多媒体顶会发表多篇论文。主要研究方向为视频 AIGC 的可控生成&视频风格化任务,近期研究领域为基于多模态大模型的智能剪辑。
王润奇
小红书 AIGC 团队算法工程师,在 ICCV、ACM MM 等计算机视觉、多媒体顶会发表多篇论文,曾多次获得天池、顶会 Challenge 冠亚季军。主要研究方向为扩散模型、可控图像生成和视频生成等。
魏婴
小红书 AIGC 团队算法工程师,主攻图像视频AIGC可控生成和风格化,近期聚焦基于多模态大模型的长文和人像生成。
秦明
小红书社区智创 AIGC 方向负责人。在计算机视觉领域顶会发表多篇论文,曾获 ICCV VOT 世界冠军,多次刷新 MOT 国际榜单世界记录。在创作领域,专注于视频自动化剪辑、图像/视频可控生成、个性化生成等方向的算法研究与落地工作。


