离职掀桌!Mistral被曝“蒸馏”DeepSeek。
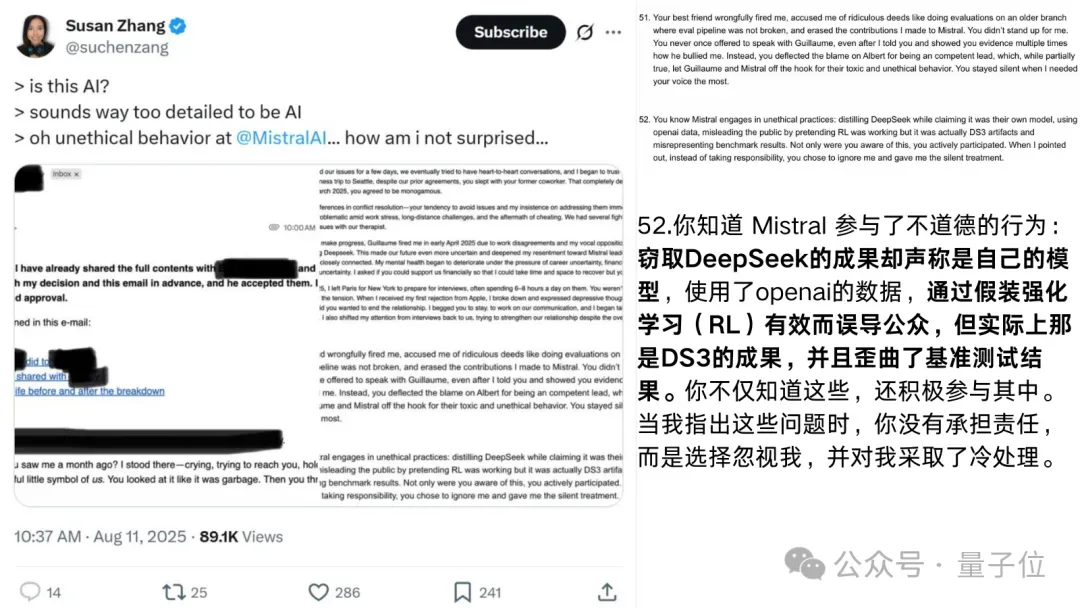
网友在推特上爆料,一位Mistral离职女员工群发邮件,直指公司多项黑幕。
其中最劲爆的就是:Mistral最新模型疑似直接蒸馏自DeepSeek,却对外包装成RL成功案例,并刻意歪曲基准测试结果。
说到Mistral,这家公司被誉为欧洲版OpenAI,是全球开源明星玩家之一,模型性能一直备受好评。
也正因为声誉突出,这次爆料才显得格外震撼。
早在今年6月,就有博主通过“语言指纹”分析,发现Mistral-small-3.2和DeepSeek-v3很像。
有意思的是——今年2月,还有网友调侃DeepSeek是“中国的Mistral”。

结果半年过去,剧情反转:Mistral不仅没跑赢DeepSeek,还被曝“借”了人家的成果。
这波啊,这波叫回旋镖自带GPS,绕半圈又精准扎回自己身上。
Mistral蒸馏DeepSeek实锤
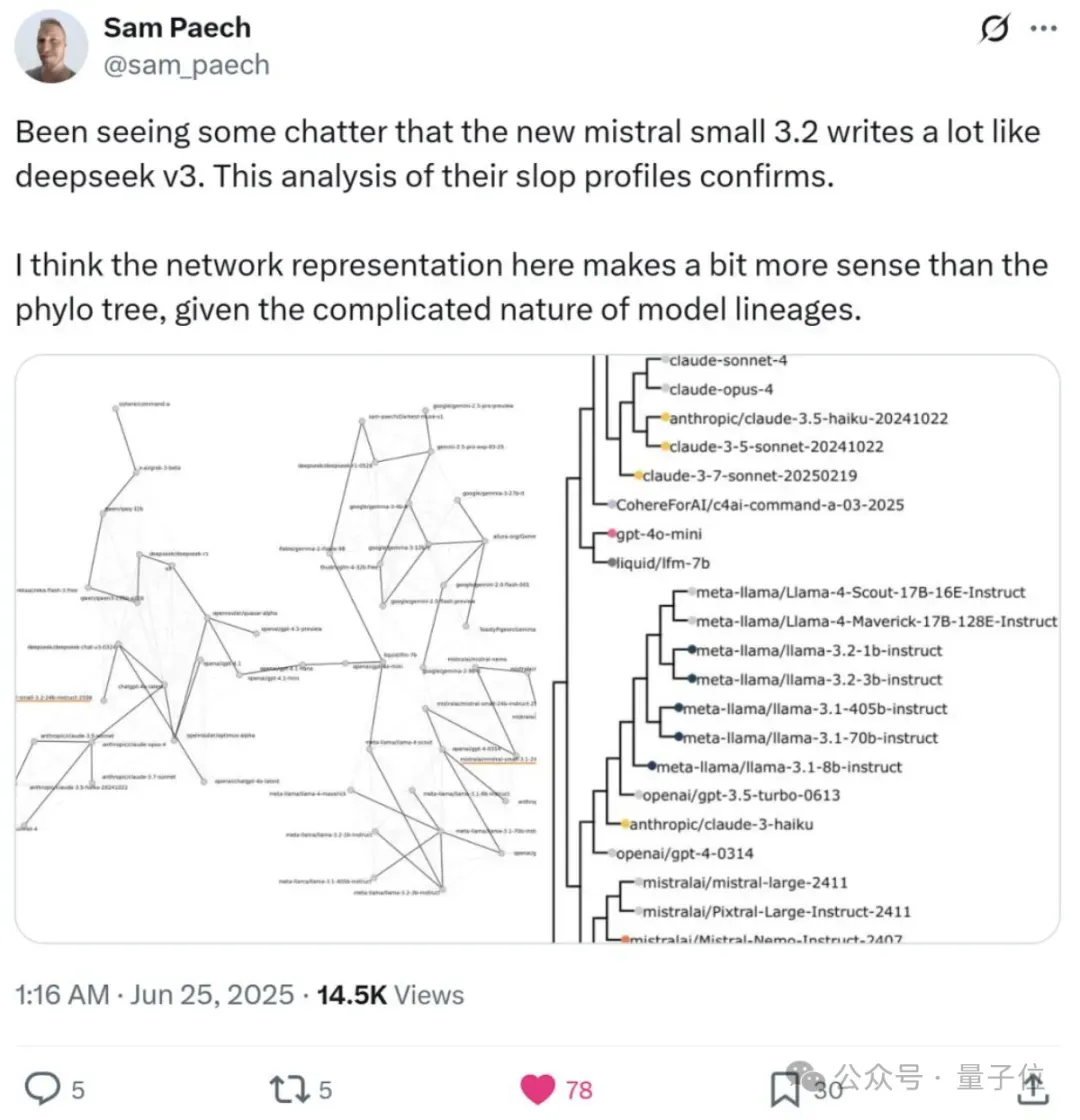
就像我们开头提到的,推特博主Sam Peach通过分析模型输出中过度使用的词汇模式(Slop),发现了Mistral-small-3.2与DeepSeek-v3之间令人惊讶的高度相似性。
这种相似性通常很难通过独立训练偶然出现,所以很可能就是蒸馏(distillation)的结果:
Mistral-small-3.2“学习”了DeepSeek-v3的输出风格。
具体来说,Sam Peach是这样做的。
他先统计了模型在创意写作(creativewriting)的输出中,比人类文本更常出现的词和n-gram(词组)。
然后他把这些把数据整合起来,形成一个特征集。
最后把这些高频特征进行层次聚类(hierarchicalclustering),生成了一张“相似性图”。
通过比较相似性图中模型的远近位置,就可以发现Mistral-small-3.2和DeepSeek-v3在图中非常接近,这就表明了它们的输出模式高度相似。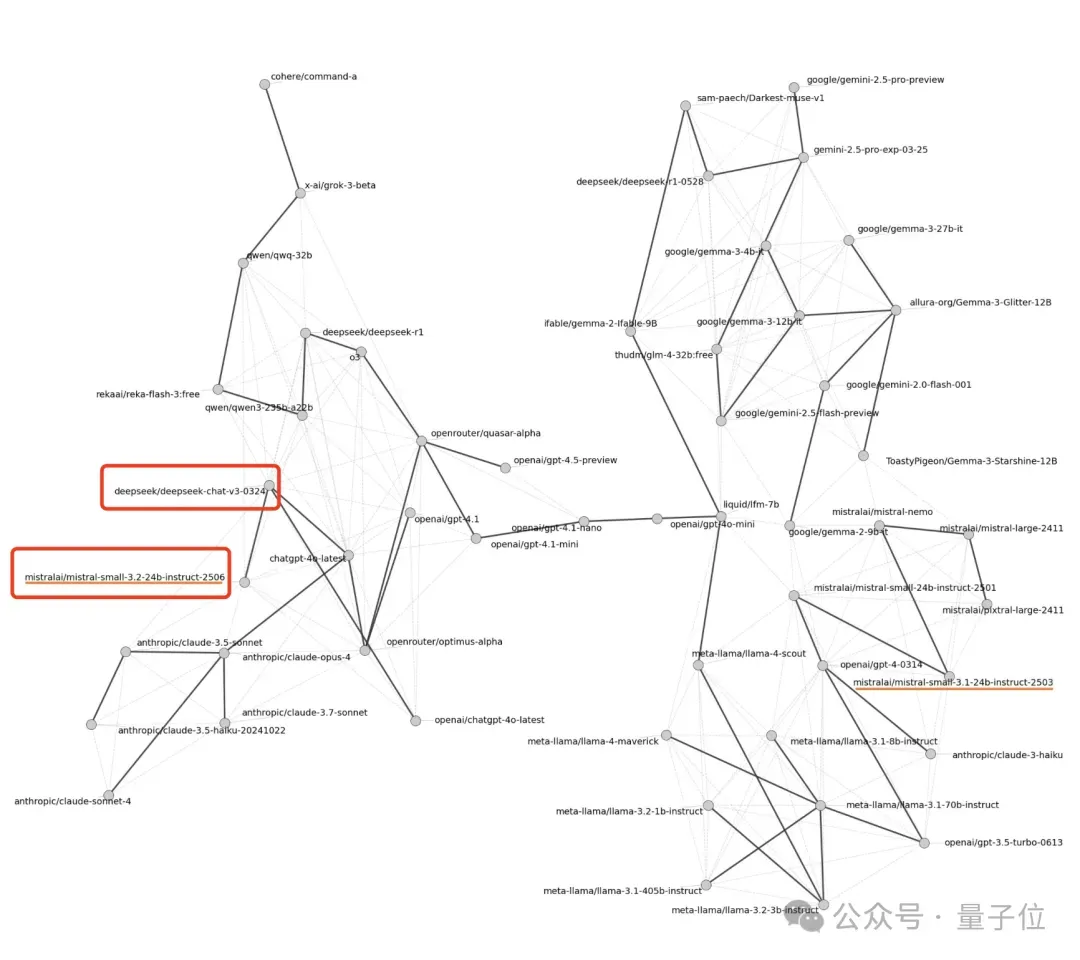
最新的爆料则进一步指明,Mistral模型和DeepSeek相似不是巧合,而是可能使用了蒸馏。
由于爆料人Susan Zhang的推特设置可见范围,更多爆料信息暂时无从得知。
但这里需要说明,蒸馏并不是一件违规的事,现在很多模型都是通过这一方法快速提升能力。

Mistral的问题在于,可能隐藏了这部分事实。
离职员工说,Mistral这样做是在假装自家模型的强化学习有效,这不仅歪曲了基准测试结果,而且误导公众。
不少人也认同这一观点:蒸馏模型必须标注,保持透明性才是关键。
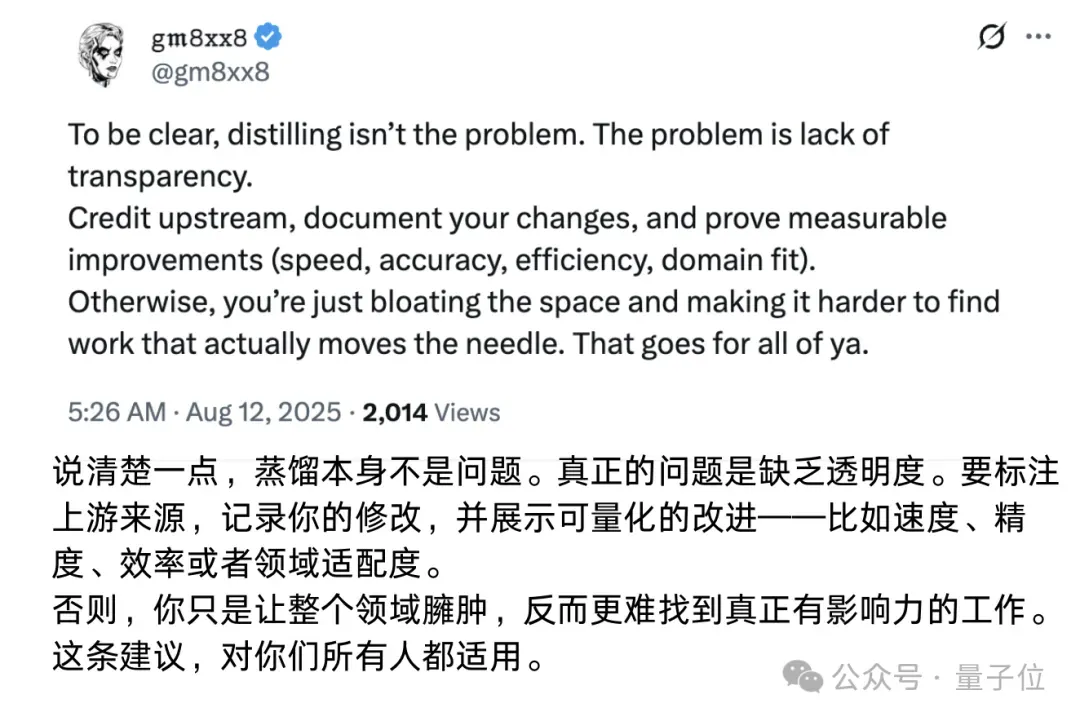
此外还有网友表示,蒸馏实际上为模型开发开辟了一条捷径,好让大家不用再重复造轮子。
官方暂无回应
这事儿颇具争议,除了事件本身,主要还在于Mistral在开源AI圈的地位不低。
它成立于2023年,base法国巴黎,一直被称为欧洲版OpenAI。由前Google DeepMind的Arthur Mensch和前Meta的Guillaume Lample与Timothée Lacroix联合创立。
在今年8月,Mistral被曝估值达到100亿美元,且正在筹集新一轮10亿美元融资。
而在上一轮融资中(2024年6月),Mistral完成了一轮由General Catalyst领投的6亿欧元(6.45亿美元)的融资,这使其估值上升至58亿欧元(62亿美元),排名全球第四(美国湾区外排名第一)。

从公司成立以来,Mistral一直保持开源路线,今年开源的模型就包括轻量级模型Mistral Small和主打编程的Mistral Code等。
相较于主流的大语言模型,主打开源、小快灵的Mistral,在多语言处理和推理能力方面具备相当的竞争力,在大模型市场中占据着独特的地位。
同时他们也推出了自家聊天机器人LeChat,对标ChatGPT,内置深度研究模式、原生多语言推理和高级图像编辑等功能。
截至目前,Mistral官方还没有回应,就在昨天他们还发布了新模型Mistral Medium V3.1。


