谷歌 DeepMind 发布了全新的 Gemma 3 270M。
它只有 2.7 亿参数,比七百亿参数级别的大模型轻了约 250 倍,却依旧保持强悍。
DeepMind 并不想拿它硬刚 GPT-4o 或 Gemini Ultra,它生来就为极致高效、本地部署而生。
在内部测试中,Gemma 3 270M 已能在 Pixel 9 Pro 的 SoC 上本地运行,整个推理过程无需依赖外部云端。
它甚至能跑进 Chrome 浏览器、树莓派,工程师 Omar Sanseviero 笑称:“连你的烤面包机都能跑。”
谷歌强调:这款小模型的出发点,就是应对功耗限制、延迟上涨和推理成本飙升的现实挑战。
Gemma 3 270M 由 1.7 亿嵌入参数 + 1 亿 Transformer 块参数组成。
它的词表高达 25.6 万,是同级别模型里罕见的“巨词库”,能吞下冷僻词、专业术语和小语种符号。
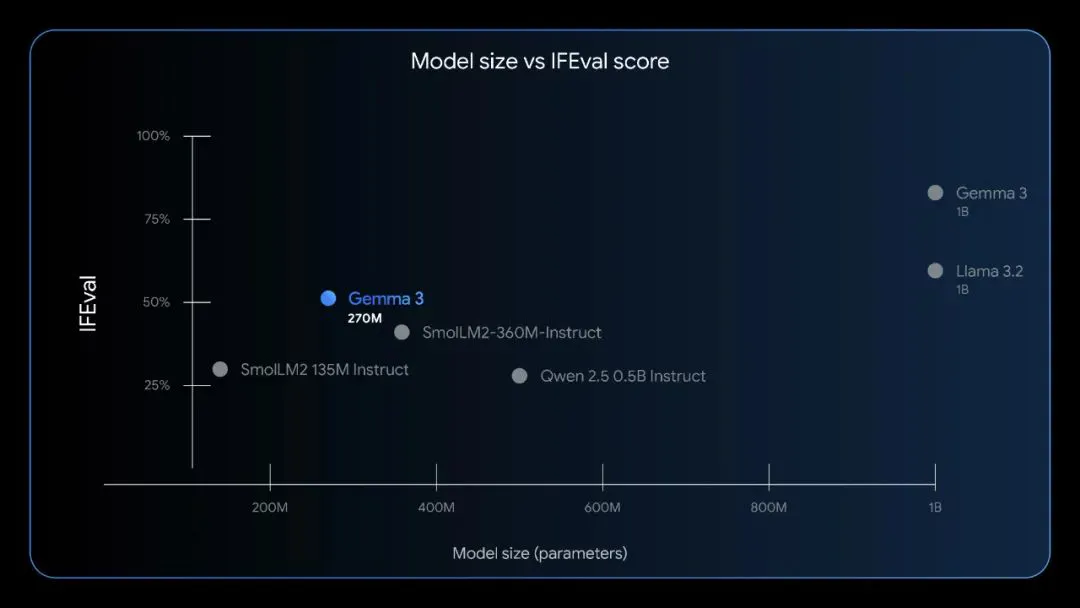
在 IFEval 指令遵循基准里,指令调优版 Gemma 3 270M 拿到 51.2%:胜过 SmolLM2 135M Instruct(44.8%),压过 Qwen 2.5 0.5B Instruct(49.1%),逼近部分十亿级中型模型。
Liquid AI 则在社交平台提醒:自家 LFM2-350M 得分 65.12%,参数只多约 30%。
在 Pixel 9 Pro 上跑 INT4 量化版本,连续 25 轮多轮对话耗电仅 0.75%。
谷歌还放出了量化感知训练(QAT)检查点,把权重量化到 INT4 的同时保持性能,显著降低显存与内存占用,适合资源受限的边缘设备。
谷歌提出“用对工具”的理念:特定任务用小模型往往更快、更省。
在情感分析、实体提取、合规检查、结构化文本生成、查询路由等场景中,官方示例显示 Gemma 3 270M 的端侧推理延迟可低至 50 毫秒量级,而云端大模型动辄数百毫秒乃至数秒。
Gemma 3 270M 可以在同一设备上同时部署多个专用微模型,各司其职、互不抢算力。

网址:https://huggingface.co/spaces/webml-community/bedtime-story-generator
此外,谷歌演示了一个完全离线的“睡前故事生成器”用户在浏览器里点选主角、场景和转折,模型两秒内生成完整短篇;全过程无云调用,速度与隐私兼得。
同时,Gemma 3 270M 沿用 Gemma 自定义许可。
只要传递谷歌的禁止使用政策、向下游提供同样条款并标明修改,就能自由使用、改动、分发模型和衍生版。
企业可把它嵌进产品或云服务,也可继续训练,生成内容版权归使用者,谷歌不主张额外权利。
唯一红线:不得违法、不得作恶。这不是严格的开源许可证,却足以支撑广泛商业化,而且无须另付授权费。
目前,Gemma 生态下载量已突破 2 亿,覆盖云端、桌面、手机三大形态。谷歌希望借 Gemma 3 270M 把“高效、隐私、可商用”的端侧 AI 路线推得更远。


