 编辑丨#
编辑丨#DeepSeek,这段时间十分热门的科技公司,其主推模型 DeepSeek-R1 在实体医院中也是广受欢迎。自 DeepSeek-R1 在 2025 年 1 月推出以来,仅四个月时间就已经在全国超过 750 家医院投入使用,这其中完成了本地部署的有超过 500 个(截止到 2025 年 5 月 8 日)。
但尽管如此,LLM 在医院等设施内的部署还处于监管的「灰色地带」,清华大学的张一教授如此指出。如何完善针对临床 AI 的监督框架,避免患者与医院陷入潜在的危险,是当下需要解决的一个问题。
张一教授与其团队的看法以「Rapid deployment of large language model DeepSeek in Chinese hospitals demands a regulatory response」为题,于 2025 年 7 月 30 日刊登在《Nature Medicine》。

论文链接:https://www.nature.com/articles/s41591-025-03836-y
医院中的 DeepSeek
DeepSeek 的广泛使用得益于其多项技术优势,尤其是「极高的性价比」和「开源可定制性」——这两点对于降低医院部署成本至关重要。目前,市场上两种主流的 DeepSeek-R1 一体化商业系统均以可负担的价格面向众多医院。
相较于早期 LLM 的推理能力,DeepSeek-R1 通过「多阶段训练方法」实现了更高水平的推理性能,其表现可媲美 OpenAI 的 o1 模型,这对于处理复杂的医疗任务尤为关键。更重要的是,其开源许可使医院可以灵活改造与二次开发,完美契合中国各地不同规模院所的预算与 IT 条件。
表 1: 医院实际部署深度求索医疗解决方案的场景及需求。
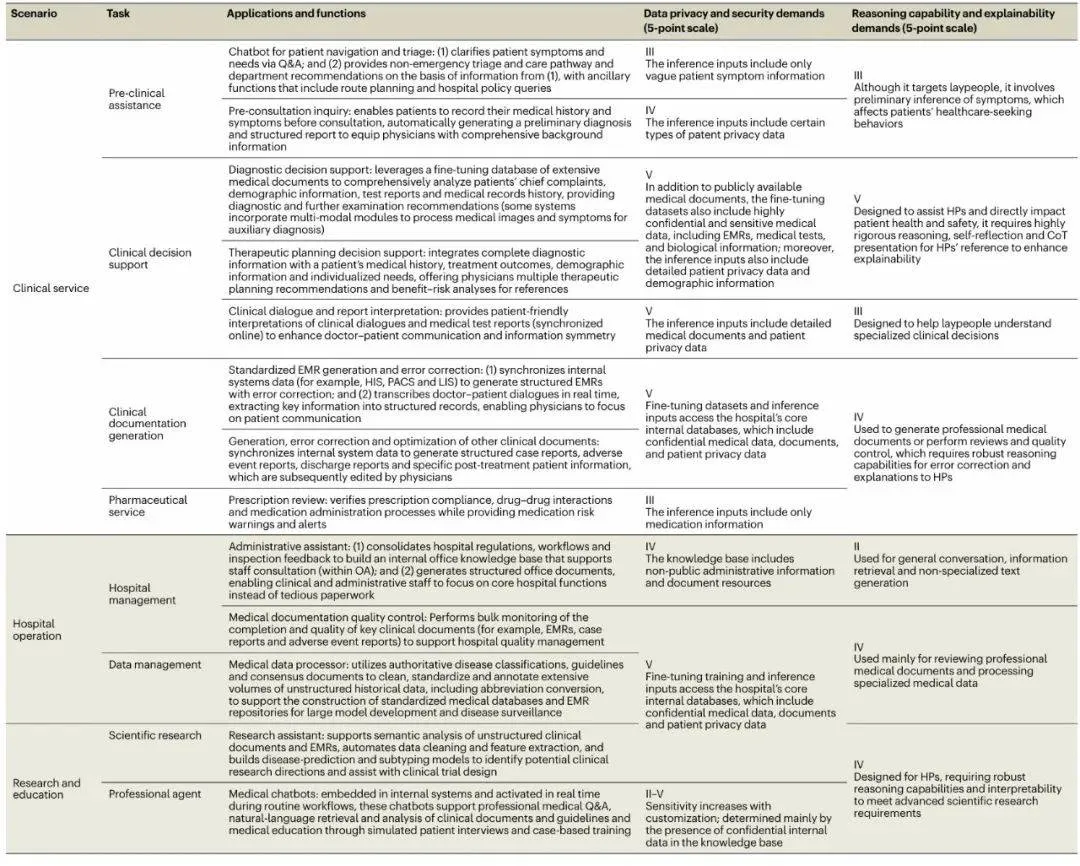

不同的临床场景所对应的安全性和保密性要求各有不同,根据实际情况的需要,即使同一种服务也会有要求的差异化。除此之外,由于是面向医疗专业人员的应用,如诊断和治疗决策支持,这些应用需要最高标准的推理和可解释性。 DeepSeek 在这些地方做得很好,论文中如此评价道。
临床服务场景
预问诊与分诊支持:聊天机器人预诊,梳理患者症状需求,提供非急诊科室推荐、路线及政策查询。
诊前病史采集:患者候诊前录入病史症状,系统生成初步诊断报告,隐私与推理可靠性要求高。
临床决策支持:整合多源医疗数据(含影像)生成诊断建议与治疗方案,涉敏感病历,隐私及推理需求最高。
临床对话与报告解读:实时转化专业术语、解读报告,输入为完整病历需高隐私,面向患者推理需求低(语言通俗即可)。
标准化EMR生成与纠错:自动提取多系统数据生成结构化病历,涉核心数据库,隐私与推理纠错能力要求高。
其他医疗文书生成:自动生成病例/出院小结等初稿,数据敏感需最高隐私,推理需保障术语规范。
处方审核:审核处方合规性与用药风险,仅输入药品信息,隐私与推理需求适中。
医院运营管理
行政助手:整合规章流程构建知识库,支持员工查询并生成办公文书,隐私要求高(保护非公开信息),推理需求低。
病历质量监控:批量监测病历文书质量,需访问核心数据库(保护最高),推理仅需保障审核准确。
科研教学
科研助手:分析非结构化病历辅助建模与试验设计,面向科研需高隐私、推理及可解释性。
医疗数据清洗与标准化:利用权威指南清洗历史数据,构建标准化库,数据敏感隐私需求极高,推理需保障术语准确。
医学教育机器人:嵌入系统支持医学问答、模拟教学,隐私与推理需求依任务复杂度动态变化。
个人健康管理
慢性病监测与报告解读,需上传医疗记录生成风险评估与解读建议,隐私保护需求高,推理能力依服务类型调整。
LLM 的监管
即使大语言模型在当下的广泛运用带来了诸多益处,其仍有部分潜在的风险。DeepSeek-R1 的高级推理能力可能让错误输出更具迷惑性,导致误诊、不当治疗等,多模态模型中医生可能过度依赖,加剧风险。
在上文中所陈列的临床辅助等使用场景中,若大模型提供错误建议,可能导致治疗延迟或不当自我治疗。在这些场景里,因为操作失误或者黑客等因素导致的伦理、合规或数据泄露问题也需要考虑其中的风险。
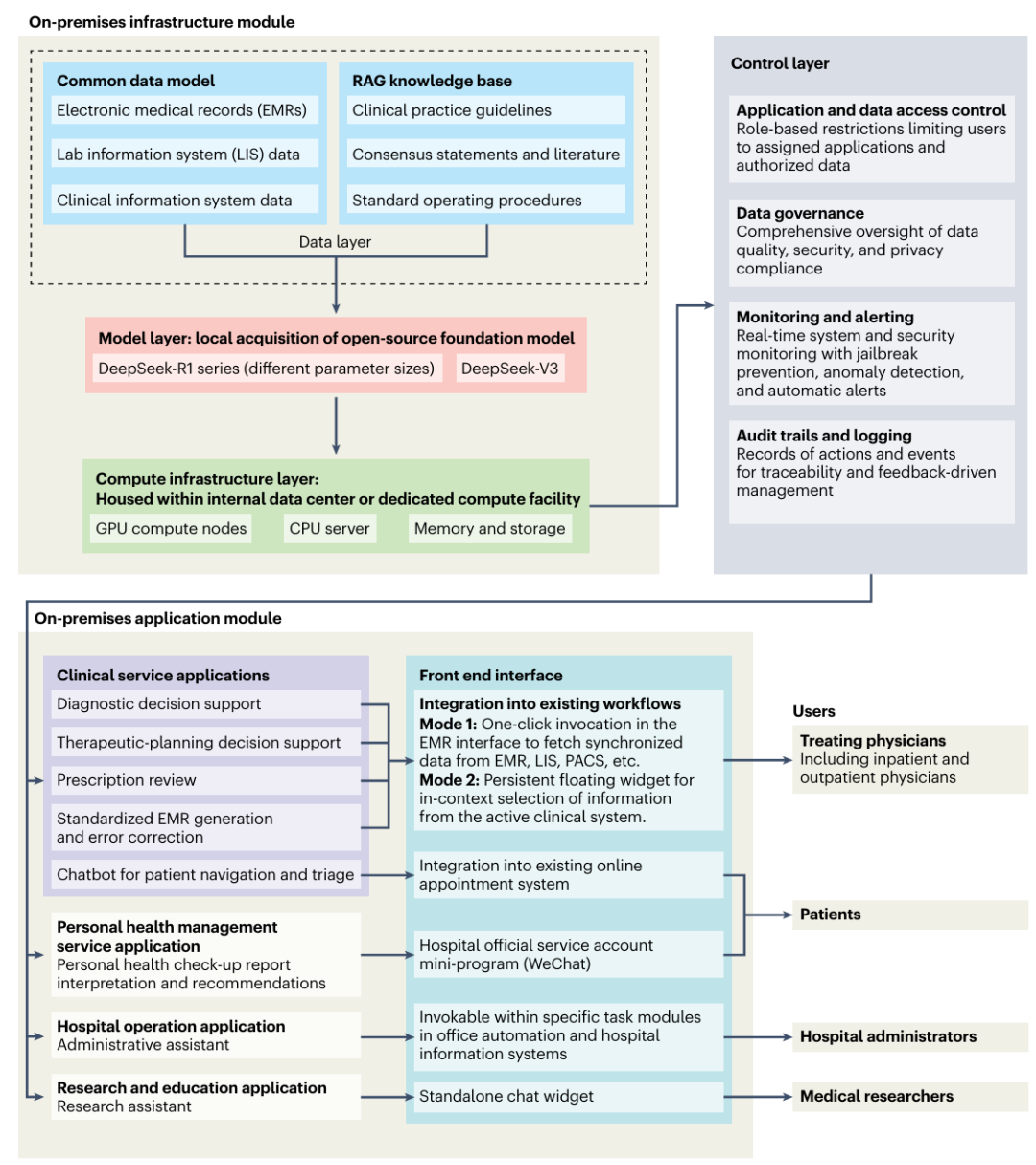
图 1:北京 P 医院的 DeepSeek OPD 在现实世界中的系统架构。
张一教授表示,DeepSeek 的推广正处于 LLM 在医疗领域应用的监管「灰色地带」,自其发布以来,中国在 AI 应用方面进展迅速,但监督框架还不甚完善。在少数地方,分类标准仍然模糊不清,高风险应用程序经常与仅用于研究和教育的医疗聊天机器人混为一谈。
表 2:面向医生和患者的基于大语言模型的医疗应用的监管状态。
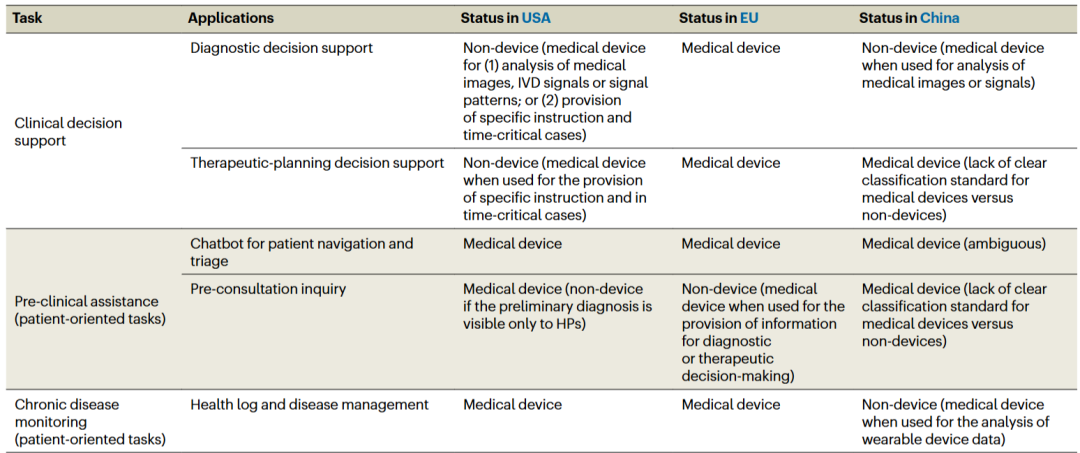
正确而完善的监管措施应该是怎样的
最基础的部分,应该是基于应用场景和风险等级分类 LLM 应用,明确 NHC(国家卫生健康委员会)与 NMPA(国家药品监督管理局)的监管职责及协调机制。
其次需要定义高风险应用监管阈值。对诊断、治疗决策支持等高风险应用,明确其作为医疗设备的监管边界,分辨清楚哪些是简单的引导程序哪些是智能应用。
构建生命周期管理路径:包括采用定制化评估工具(如 MedBench)并公开结果、实施实时验证与部署后监控、建立模型更新的变更控制机制(更新后触发重新评估)。
张一教授强调,包括中国在内,许多国家在医院大语言模型门诊诊疗方面缺乏足够的监管准备,尤其是在创新与患者安全之间的平衡问题上。因此,建立一个强大且全面的监管框架,已变得既紧迫又必不可少。


