
译者 | 陈峻
审校 | 重楼
本文将向你介绍OpenAI新发布的两个开源模型--gpt-oss-120b和gpt-oss-20b,它们的特点,以及在何种场景下该使用哪个模型。
近期,OpenAI发布了两个开源的大语言模型(LLM)--gpt-oss-120b和gpt-oss-20b。它们是自GPT-2以来,由OpenAI第一个公开许可的LLM。其旨在创建最好、最先进的、供推理和工具使用的模型。通过开源gpt-oss,OpenAI允许人们在Apache 2.0的范围内,自由地使用和适配。当然,这两种模式也考虑了专业个性化,以及定制到本地和上下文任务的民主化方法。
在本文指南中,我们将介绍如何获取gpt-oss-120b和gpt-oss-20b服务,以及在何种场景下使用哪个模型。
gpt-oss的特别之处
OpenAI本次新开源的模型是自GPT-2以来最强大的公共模型。其先进之处主要体现在:
- 开放的Apache 2.0许可证:gpt-oss的各种模型不但完全开源,并且是根据Apache 2.0许可证提供授权的。这意味着,它们没有任何copyleft限制,开发人员可以将其用于研究或商业产品,且无需许可费或源代码义务。
- 可配置的推理水平:gpt-oss独特的功能在于用户可以轻松地将模型的推理能力配置为:低、中或高。这是速度与“思考”深度的权衡。使用“浅推理”和“深度推理”分别会让模型在回答之前进行少量与深度的“思考”。
- 全思考链(Chain-of-Thought)访问:与许多封闭模型不同,gpt-oss展示了其内部推理。它有一个默认的分析输出,即推理步骤通道,以指向最终答案通道。用户和开发人员可以检查或过滤输出部分,以调试或信任模型的推理。
- 原生代理功能:gpt-oss模型建立在代理工作流之上。它们是为遵循指令而构建的,而且在“思考”中使用了工具的原生支持。
模型概述和架构
这两个gpt-oss模型都基于Transformer网络,采用了专家混合(Mixture-of-Experts,MoE)设计。在MoE中,只有完整参数(即“专家”)的子集才对于每个输入的token有效,从而减少了计算。我们来看一组数字:
- gpt-oss-120b的总参数量为1170亿个(36层)。它使用了128个专家子网络,每个token都有4个活跃的专家,也就是说每个token能生成51亿个活跃参数。
- gpt-oss-20b的总参数量为210亿个(24层),它有32个专家(4个活跃),每个token产生约36亿个活跃参数。同时,该架构还包括了一些高级功能,例如:所有注意力层(attention layer)都使用旋转位置嵌入(Rotary Positional Embeddings,RoPE)来处理过长的上下文(最多128,000个token),以便注意力本身在全局滑动窗口和128 token的滑动窗口之间交替进行。该设计类似于GPT-3。此外,这些模型使用了大小为8的分组多查询注意力,以节省内存,同时也保持了快速推理能力。由于其激活函数是SwiGLU,因此所有专家权重都被量化为4位的MXFP4格式,以允许大型模型适配80GB GPU,让小型模型适配16GB,而不会造成重大的准确性损失。下表总结了其核心规格参数:
模型 | 层 | 总参数 | 活跃参数/token | 专家(总计/活跃) | 上下文 |
gpt-oss-120b | 36 | 117B | 5.1B | 128 / 4 | 128K |
gpt-oss-20b | 24 | 21B | 36B | 32/4 | 128K |
技术规格和许可
- 硬件要求:gpt-oss-120b需要高端GPU(约80-100 GB VRAM),并在单个80 GB A100/H100级GPU或多GPU的设置上运行。而gpt-oss-20b相对较轻,即使在笔记本电脑或苹果Silicon上也能以约16 GB VRAM运行。同时,这两种型号都支持128K token的上下文,非常适合冗长的文档,以及密集型计算。
- 量化和性能:这两种型号都使用4位的MXFP4作为默认值,其有助于减少内存的使用,并加快推理速度。当然,如果没有兼容的硬件,它们会回落到16位,并且需要约48 GB供给gpt-oss-20b。此外,使用FlashAttention等可选的高级内核,也可以进一步提高计算速度。
- 许可证和使用:基于Apache 2.0发布,这两种型号都可以被自由地使用、修改和分发,甚至用于商业用途,而无版权或代码共享的要求,更无API费用或许可证限制。
技术规格 | gpt-oss-120b | gpt-oss-20b |
总参数 | 1170亿 | 210亿 |
每个token的活跃参数 | 51亿 | 36亿 |
架构 | 带有128专家的MoE(4个活跃/token) | 带有32专家的MoE(4个活跃/token) |
Transformer块 | 36层 | 24层 |
上下文窗口 | 128,000个token | 128,000个token |
内存要求 | 80 GB(适合单个H100 GPU) | 16GB |
安装和设置过程
下面我们来看看如何上手使用gpt-oss:
Hugging Face Transformers:请安装其最新的库,并直接加载模型。以下安装命令是必要的先决条件:
复制以下代码可从Hugging Face hub处下载所需的模型。
复制下载模型后,你可以使用以下方式进行测试:
复制此设置可从OpenAI指南中获得,并在任何GPU上运行。为了在NVIDIA A100/H100卡上获得最佳速度,请安装triton内核,以使用MXFP4;否则该模型将会在内部使用16位。
vLLM:对于高吞吐量或多GPU服务,你可以使用vLLM库。OpenAI在2x H100s上可以实现,你可以使用以下命令安装vLLM:
复制接着你可以通过以下命令启动服务器:
复制或者在Python中,使用:
复制这其实是在Hopper GPU上使用优化的注意力内核。
Ollama(Mac/Windows上的本地):Ollama是本地聊天服务器的turnkey。安装Ollama后,只需运行:
复制这将下载(量化)模型并启动用户聊天界面。Ollama会默认自动应用“harmony”格式的聊天模板。你也可以通过API调用它。例如,使用Python和OpenAI SDK指向Ollama的终端:
复制它会像官方API一样,将提示词发送给本地gpt-oss模型。
Llama.cpp(CPU/ARM):提供预构建的GGUF版本(例如,ggml-org/GPT-Oss-120b-GGUF on Hugging Face)。安装llama.cpp后,你可以在本地构建服务模型:
复制然后以相同的格式将聊天消息发送到http://localhost:8080。此选项允许在具有JIT或Vulkan支持的CPU或GPU-agnostic的环境中运行。
总体而言,gpt-oss模型可以与最常见的框架一起使用。上述方法(如:Transformers、vLLM、Ollama、llama.cpp)涵盖了桌面和服务器设置。你也可以进行混合配置。例如,运行一个用于快速推理的设置(如:在GPU上的vLLM)和另一个用于设备测试的设置(如:Ollama或llama.cpp)。
实际操作演示部分
任务 1:推理任务
提示词:选择与第三个术语相关的选项,就像第二个术语与第一个术语相关的方式一样。
IVORY : ZWSPJ :: CREAM : ?
- NFDQB
- SNFDB
- DSFCN
- BQDZL
gpt-oss-120b的响应为:
复制比较分析
gpt-oss-120B正确地识别了类比中的相关模式,并通过深思熟虑的推理选择了选项C。因为它有条不紊地解释了单词对之间的字符转换,因此获得了正确的映射。另一方面,gpt-oss-20B未能在此任务上产生任何结果,则可能是因为输出token的限制,也就揭示了输出长度的局限性,以及计算效率的低下。总体而言,gpt-oss-120B能够更好地管理符号推理,具有更多的控制和准确性。可见,对于此类涉及到语言类比的推理任务而言,gpt-oss-120B比gpt-oss-20B更可靠。
任务2:代码生成
提示词:给定两个大小分别为m和n的排序数组nums1和nums2,返回两个排序数组的中位数。
在C++中,总体运行时复杂度应该是O(log(m+n))。
示例1:
输入:nums1 = [1,3],nums2 = [2]
输出:2.00000
解释:合并数组=[1,2,3],中位数为2。
示例2:
输入:nums1 = [1,2],nums2 = [3,4]
输出:2.50000
解释:合并数组=[1,2,3,4],中位数为(2 + 3)/2 = 2.5。
约束:
nums1.length==m
nums2.length==n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i],nums2[i] <= 106
复制gpt-oss-120b的响应为:
复制gpt-oss-20b的响应为:
复制比较分析
gpt-oss-120B准确地完成了类比,选择了选项C,并通过成功地识别字母替换模式,显示了强有力的理由。该模型在处理字母振荡的转变和跟踪事物之间的关系方面,显示了良好的推理。与之对比,gpt-oss-20B甚至无法完成任务。该模型超过了输出token的限制,没有返回答案。这表明gpt-oss-20B在资源使用或处理提示方面效率低下。总体而言,gpt-oss-120B在结构推理任务中表现得更好,这使得它比gpt-oss-20B更擅长与符号类比相关的任务。
模型选择指南
在120B和20B模型之间如何进行选择,完全取决于项目需求或我们正在处理的任务。通常:
- gpt-oss-120b:是一种大功率模型,可将其用于较为困难的推理任务、复杂的代码生成、数学问题解决或特定领域的问答。它的性能接近OpenAI的o4-mini模型。因此,它需要一个具有80GB以上 VRAM的大型GPU来运行,并且能在视分步推理至关重要的基准和长形式(long-form)任务中表现出色。
- gpt-oss-20b:是一个针对效率优化的“苦干”模型。在许多基准测试中,它与OpenAI的o3-mini的质量相匹配,但可以在单个16GB VRAM上运行。当你需要快速的设备响应助手、低延迟聊天机器人、或使用网络搜索、及Python调用的工具时,请选择20B。它非常适合概念验证、移动/边缘应用、或硬件受限的场景使用。在许多情况下,20B模型的回答已足够好。例如,它在某项困难的数学竞赛任务中的得分约为96%,几乎与120B相当。
性能基准和比较
在标准化基准方面,OpenAI的各个gpt-oss可以共享结果。目前,120B模型正在不断迭代。它在艰难的推理和知识任务上的得分已高于20B模型,虽然目前两者仍各有千秋。
基准 | gpt-oss-120b | gpt-oss-20b | 开放AI o3 | OpenAI o4-mini |
MMLU | 90.0 | 85.3 | 93.4 | 93.0 |
GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
Humanity’s Last Exam | 19.0 | 17.3 | 24.9 | 17.7 |
AIME 2024 | 96.6 | 96.0 | 95.2 | 98.7 |
AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
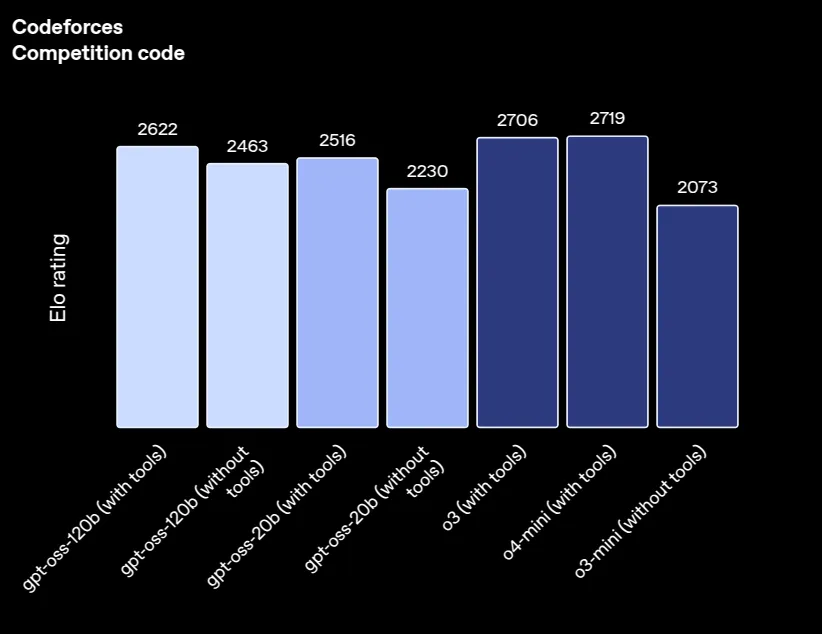
来源:ChatGPT
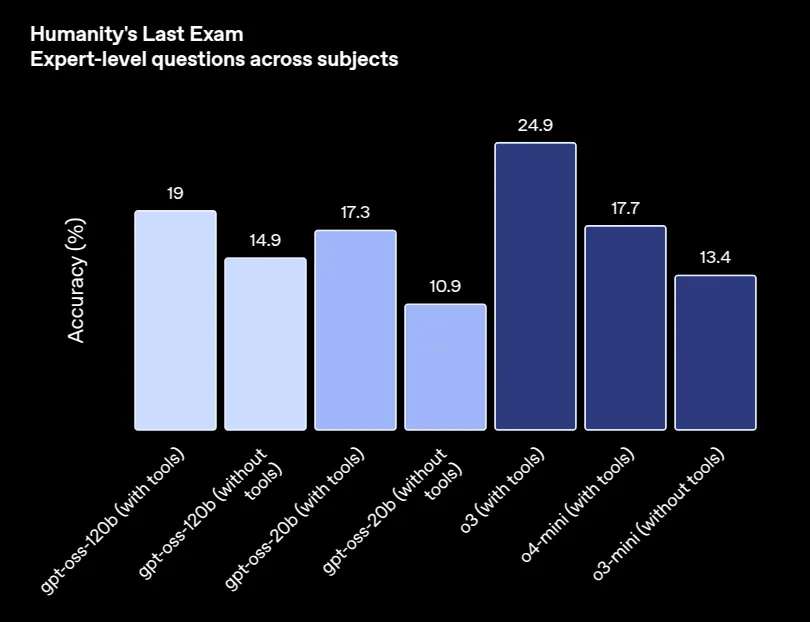
来源:ChatGPT
用例和应用
以下是gpt-oss的一些典型用例场景:
- 内容生成和重写:生成或重写文章、故事或营销文案。gpt-oss模型可以在写作前描述他们的思维过程,并帮助作家和记者创建更好的内容。
- 辅导和教育:可以演示描述概念的不同方式,一步一步地解决问题,并为教育应用或辅导工具和医学提供反馈。
- 代码生成:可以很好地生成代码、调试代码或解释代码。gpt-oss模型也可以在内部运行工具,允许它们辅助开发任务或作为编码助手提供帮助。
- 研究协助:可以总结文档,回答特定领域的问题,并分析数据。gpt-oss的模型也可以针对法律、医学或科学等特定研究领域进行微调。
- 自主代理:启用并使用工具构建带有自主代理的机器人。这些机器人可以浏览网页、调用API或运行代码。它们便捷地与代理框架集成,以构建更复杂的基于步骤的工作流。
小结
综上所述,在OpenAI发布的两个开源模型gpt-oss-120b和gpt-oss-20b中,120B模型全面表现优秀,特别是在:生成更清晰的内容,解决更难的问题,编写更好的代码,并更快地适应研究和自主任务等方面。当然,其短板在于资源利用强度较高,给本地部署带来了一定挑战。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:OpenAI Returns to Open Source: A Complete Guide to gpt-oss-120b and gpt-oss-20b,作者:Vipin Vashisth


