
现在 ComfyUI 慢慢被很多人接受,但是更多的是工程师,作为一名设计师,我发现很难理解 AI 绘画的底层逻辑,如果没有了解本质,只是了解大概,不理解里面各个参数后面的原理,那么之后面临的最直接的一个问题是不知道怎么微调模型,只能照着人家的教程 1:1 模仿。
知其然,不知其所以然是不可取的,这就是“知识”和“懂”的区别。
所以,我一直好奇,AI 绘画是怎么输入描述词,输出一张高质量的又好看的图片的?它背后是怎么操作的?
为了搞明白其中的原理,我咨询了前端工程师,后端工程师,算法工程师,产品经理、运营人员等,最后终于明白了七七八八,感谢他们的倾囊相授,所以,我想用设计师能听得懂的语言来帮助大家了解 AI 绘图到底是怎么一回事。
我不能保证大家能理解得很全面,但是我能保证大家看完后,对 AIGC 有一个整体的理解。
更多AI绘画教程:
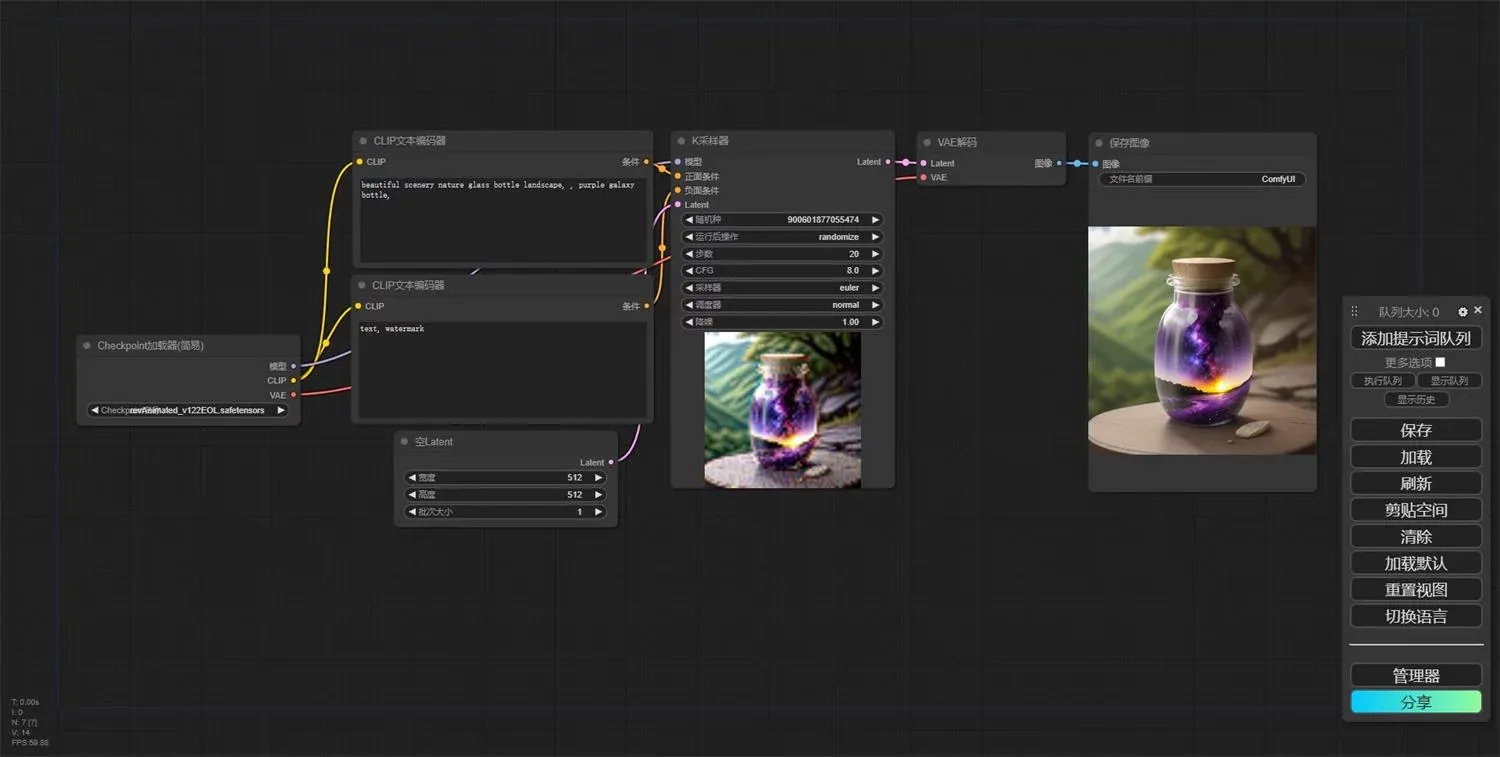
所以,到这里,有三个基本的问题需要我们先解决下:
- 什么是 AIGC
- 什么是 Stable diffusion
- 什么是 ComfyUI
一、什么是 AIGC
AIGC 的全名叫做(Artificial Intelligence Generated Content:生成式人工智能),通过机器学习,AIGC 能根据自己学习到的内容,主动创作出新的类似的内容,我们可以理解为“好学”。那么 AIGC 能学习什么,又能生成什么呢?
从目前的主流产品来看,AIGC 能生成内容大致有:文本、代码、图片、视频和音频。

二、什么是 Stable Diffusion
Stable Diffusion(稳定扩散)是 AIGC 中生成图片的一款工具,称之为图片生成类 AI 大模型,它的主要工作是根据文本的描述产生详细图像。我们可以理解为这款工具就是生成图片的,也是设计师最需要的工具,能解决的一个最直接的问题是,设计素材不用上网到处找了,自己给自己造一个就完事儿了。
下面这张图就是 Stable diffusion 生成图片的全过程,其实就是从模糊变清晰的过程,这里面的原理我会在后面细讲。

他有一个竞对,叫做 Midjourney,是图片类 AIGC 应用程序,虽然做的东西一样,但是呈现方式和解决路径不同,针对的用户群体也不同,SD(Stable Diffusion)相较于 MJ(Midjourney),可控性更强,功能更丰富,定制化也更强,而且是开源的。当然 MJ 也有自己的优势,比如操作简单,好理解,SD 的上手难度比 MJ 会高很多。

三、什么是 ComfyUI
因为 stable diffusion 是个大模型,就需要一个界面来承载模型,方便用户使用,这个界面就叫做 ComfyUI,从本质上讲,ComfyUI 是构建在 Stable Diffusion 之上的基于节点的图形用户界面(GUI),而 Stable Diffusion 是一种最先进的深度学习模型,可以根据文本描述生成图像。
ComfyUI 既然是 GUI 图形界面,那么就肯定会有产品界面的优化,所以优化之前的界面有个很熟悉的名字叫做 Webui,因此,得出结论,Webui 和 ComfyUI 其实是一个东西,只是展现方式不同,一个是页面操作,一个是节点操作。在上手难度上看,Webui 更容易理解,但出图的速度,ComfyUI 更快捷,而且 ComfyUI 可以直接复用别人的工作流,喜欢用哪个,大家可以自己决定。
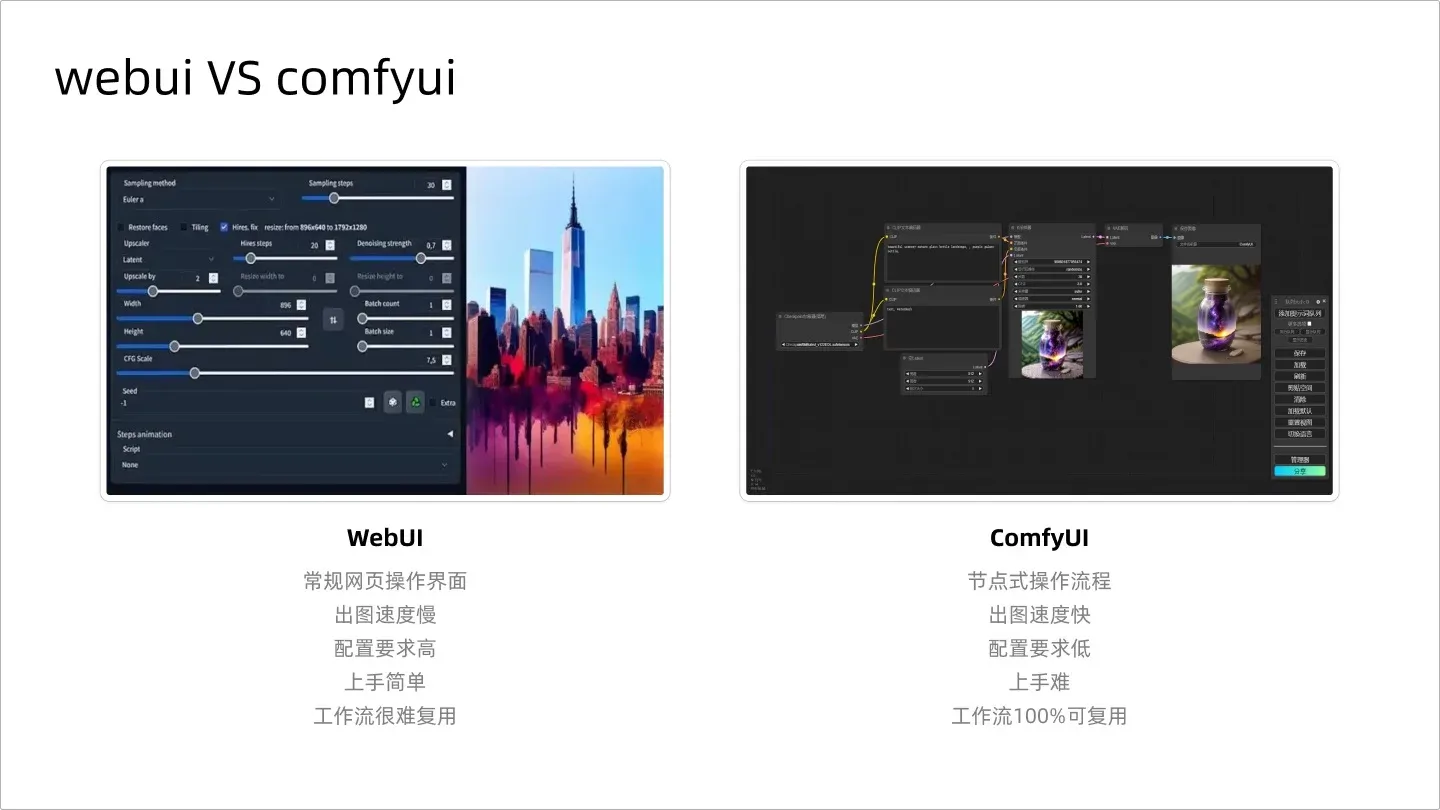
Webui 和 ComfyUI 的区别
总结下这些关系,就是如果你想用 AIGC 生成图像,你现在有三款软件可以用,分别是 Webui、ComfyUI 和 Midjourney,如图,至于用哪个,我会在下一期做更为详细的说明。如果简单区别,就是 MJ 很难控制相同的角色,比如绘制漫画,很难做到人物统一,元素保持一致,这时候就需要用到 SD,他能实现线稿上色、2D 转 3D、图片换风格、做到人物元素保持完全一致,即:精细可控。
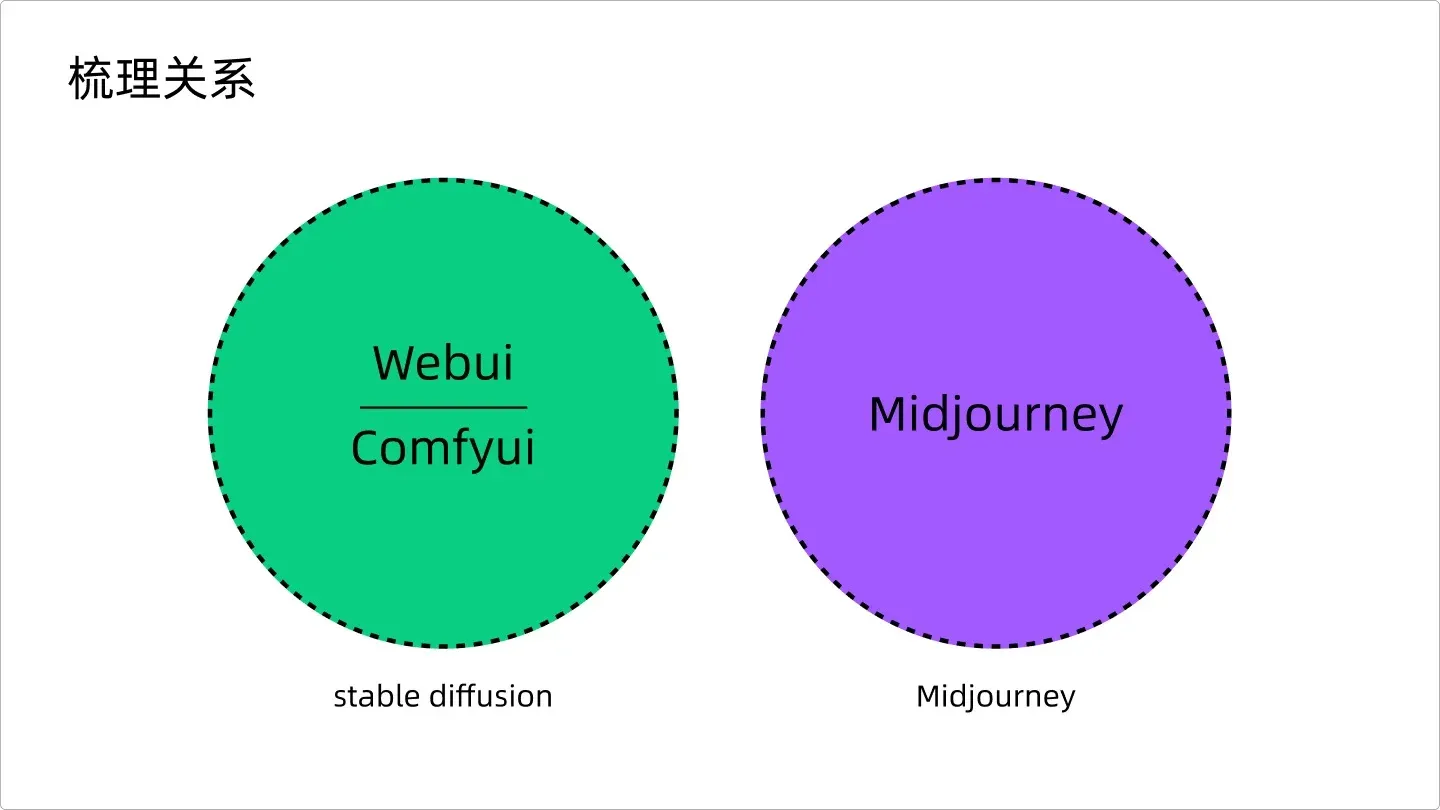
梳理关系
OK,到这里,基本已经简单阐述了 AIGC 的基本概念,下面就是本章的重点内容,AI 是怎么画画的?解决这个问题,其实本质是理解 AI 绘画是怎么自己思考的。要明白 AI 绘图的底层问题,其实很简单,只要我们理解了人是怎么学会画画的。
我们要先解决以下 2 个点:
- 人是怎么识别图片的?
- AI 是怎么识别图片的?
这里,请问,披着狼皮的羊,是狼还是羊?
答案是在人类看来,是狼,但是,AI 会觉得是羊,为什么会出现两者皆然不同的答案,是因为人类看的是形状,AI 看的是纹理。

人类会关注图片中的对象的形状,这是通过经验来获得的,看下图:

人类识图原理
AI 研究的是图片中对象的纹路。我把它解释成“RGB 色块的像素分布规律”,AI 先把图片通过“加噪点”的方式将图片一点点扩散,类似 photoshop 中的添加杂色。这个过程叫做正向扩散。
当视频在手机上无法加载,可前往PC查看。之后,提取每个小色块的 RGB,这样就把一张图片变成了由一堆像素数据组成的排列组合,再通过一个标签(tag)来定义这一组像素数据,告诉 AI,basketabll 的像素是这种分布规律,足球 football 的像素是那种分布规律,AI 就会记住每一张图片的像素分布规律特征。
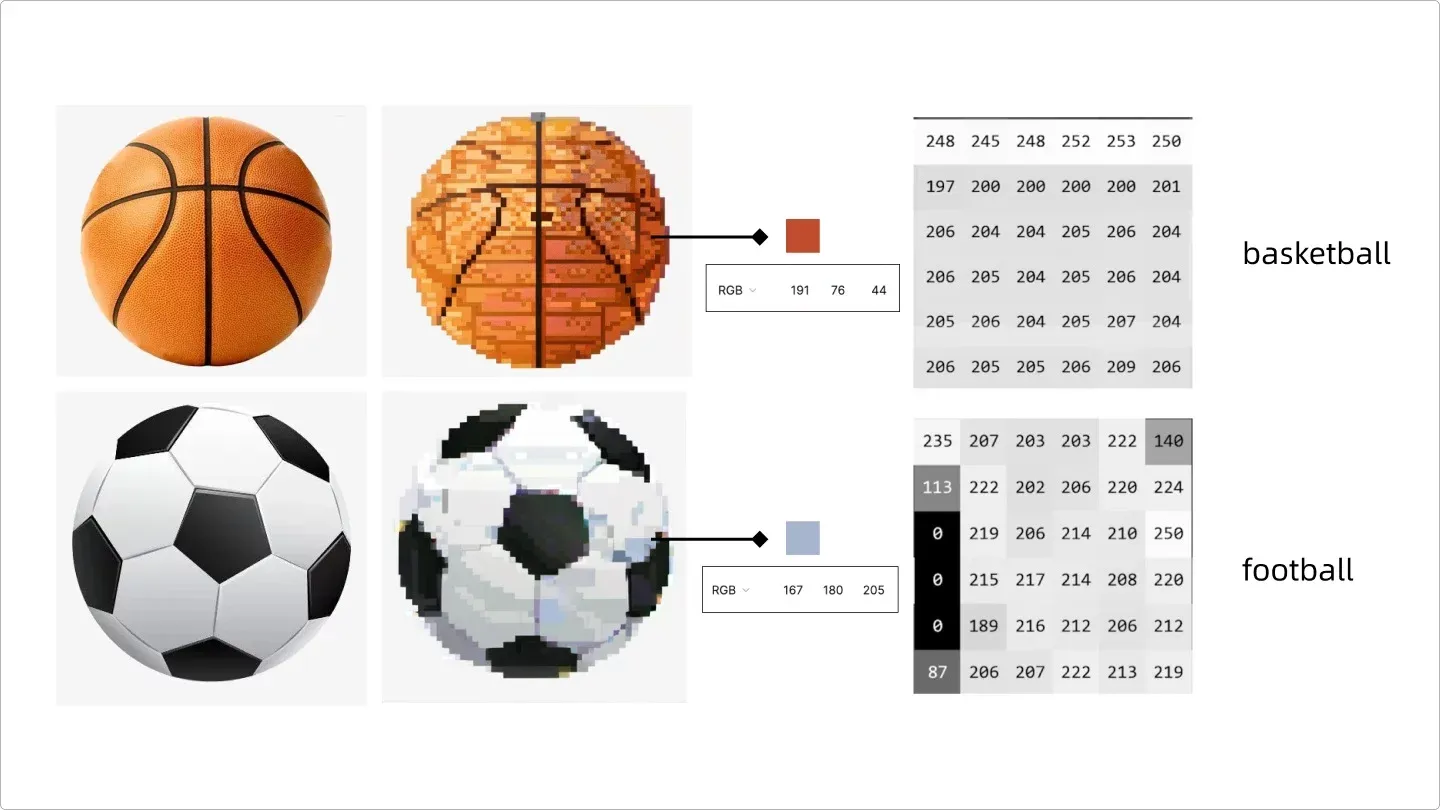
AI识图原理
当几千几万个同类物体都被 AI 识别之后,AI 就会知道这类物体的像素分布特征,这个时候,再给 AI 识别一张类似的图片,AI 就是根据该图片的特征和之前存储的特征进行比对判断,最后给出结果。这里用到了两个很重要的技术:人工神经网络和深度学习,鉴于超纲,我们知道即可。
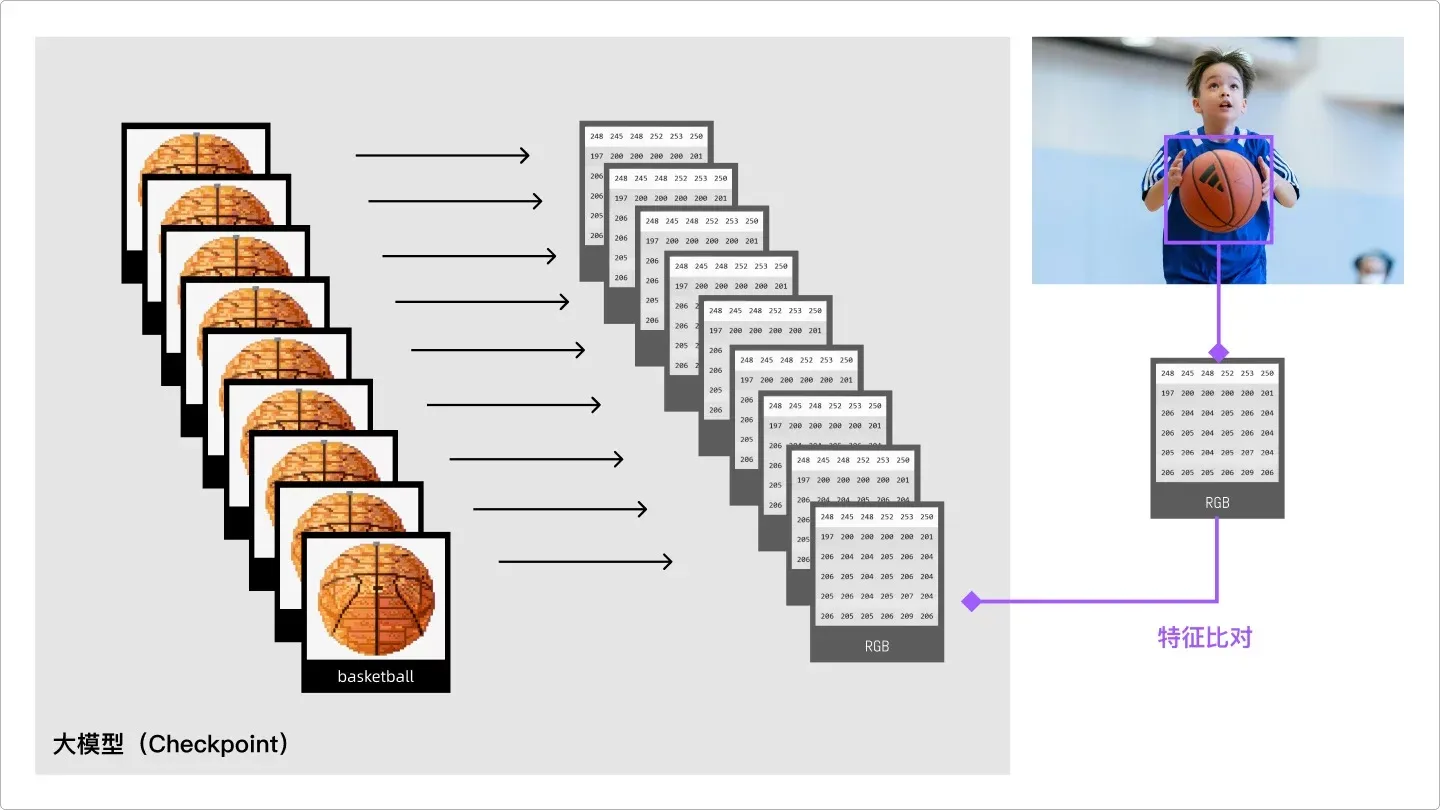
图片特征比对
人工神经网络,就是类似于人类中大脑的神经元,它可以将相关的知识进行连接,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。所以,上面的篮球在深度学习之后就会变成一个类似“神经元”的东西存在系统里。这里的神经元会通过一个数字来表达。

神经元
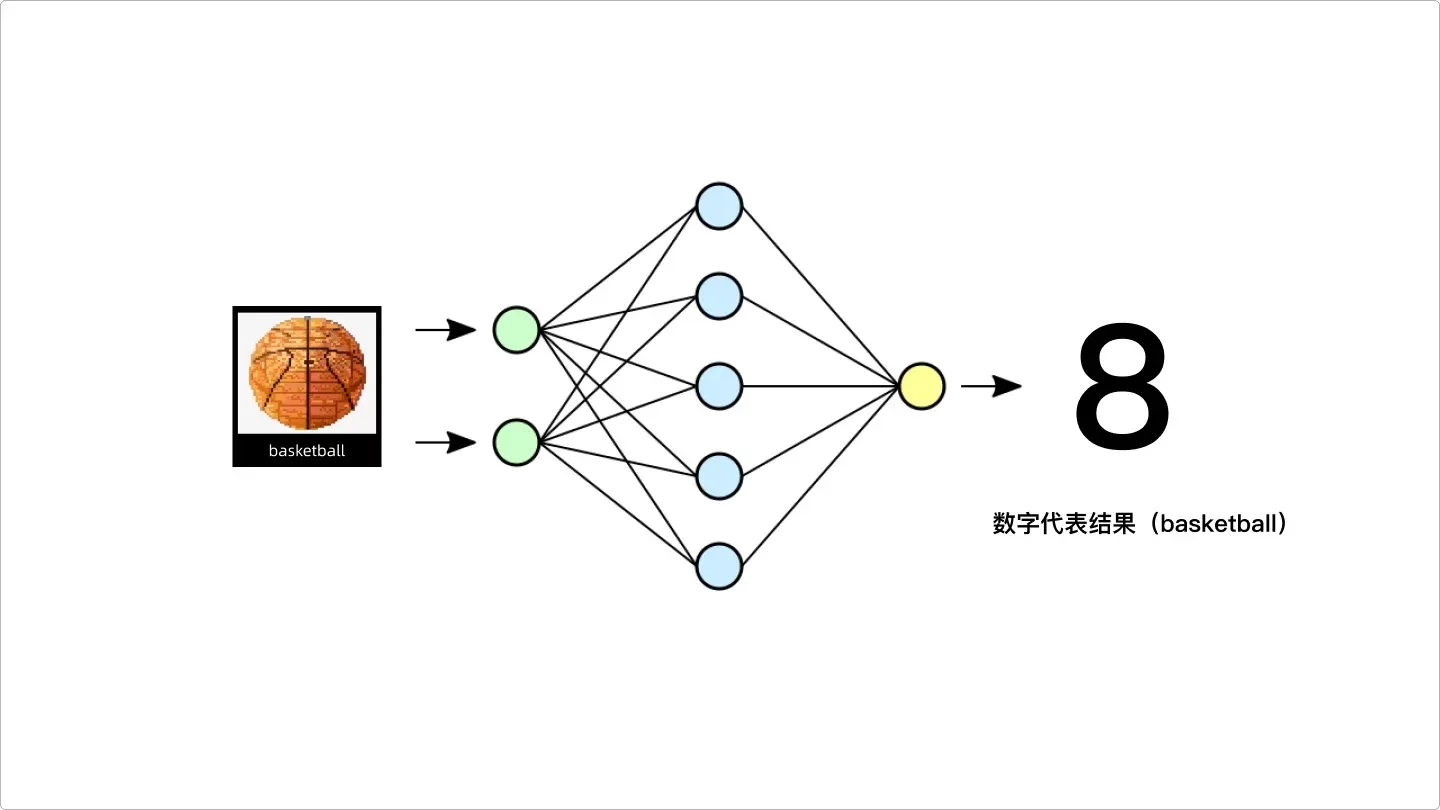
神经网络和深度学习
好了,这个时候,当你跟 AI 说,帮我画一张篮球的照片,AI 就会在已经学习的几百上千张篮球图片中去找特征,然后得到一张类似的像素分布图。本质就是模仿。
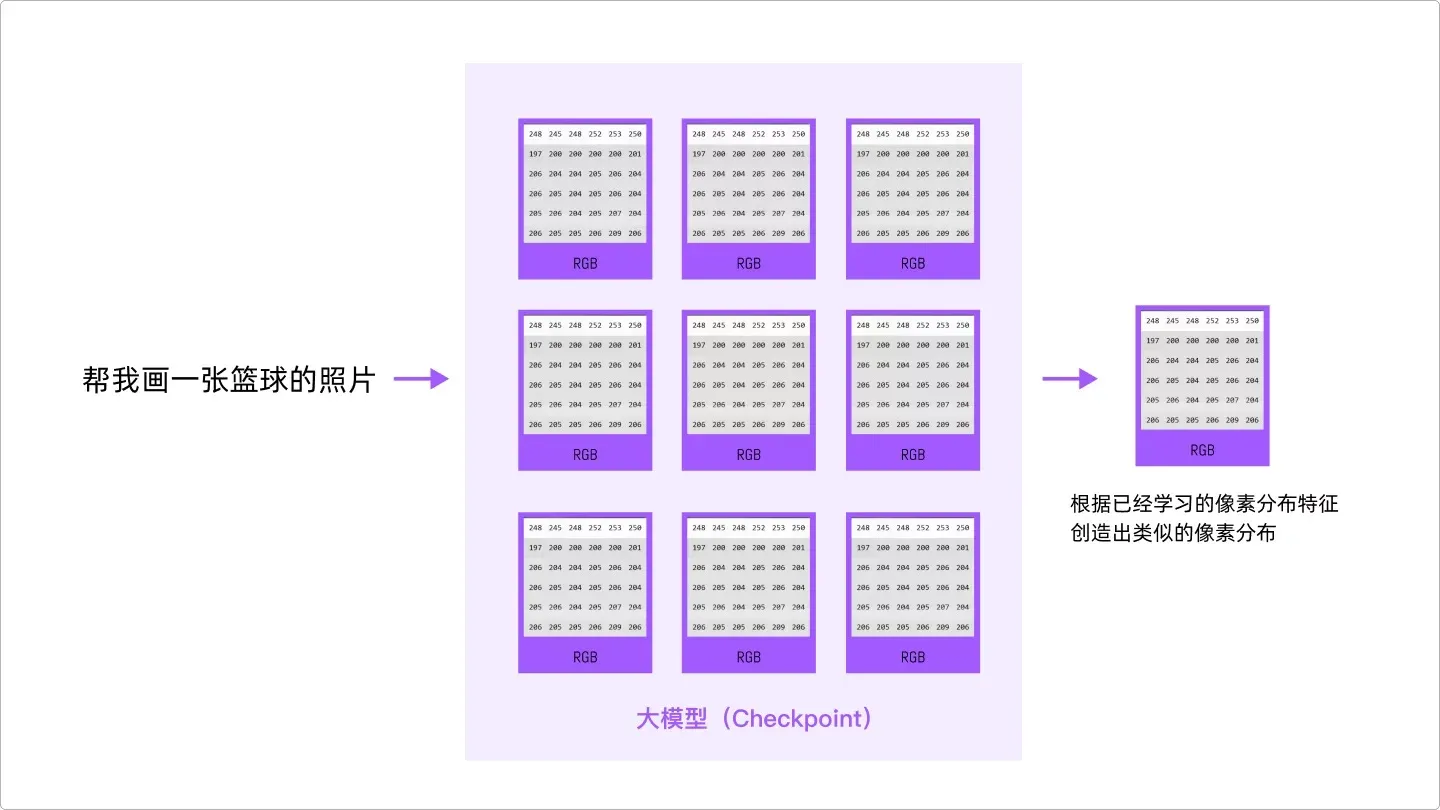
仔细想想,这其实非常类似人类绘画、书法的过程,拿书法举例,一开始我们不停地临摹大师的书法,当临摹的次数愈来越多,技能也就越来越熟练,慢慢就会有形成自己的风格,这种风格跟独一无二,跟谁都不一样,但是是从不断学习“大书法家”的字体中习得到的,学到的不是“形”,而是“神”,也就是行话里的“神韵”。所以每一位大书法家都会说我的字是“取法”于王羲之,柳公权或者是魏碑。

书法临摹和原创
AI 绘画也是如此,它学到的是每一个字,每一个笔画的“规律”,然后根据这个规律,“模仿”出类似的效果。
ok,到这里相信大家已经对 AI 绘画的原理有个基本的认识,还差最后一步,AI 是怎么把像素分布的一堆数字变成一张图片的,这里用到的技术是“反向扩散”。在 AI 识图的时候,是先把图片“正向扩散”成像素分布,最终出图的时候,就是把这个过程倒着推导一遍,可以给大家举个类似的画面,就是沙画。

diffusion model 扩散原理比喻
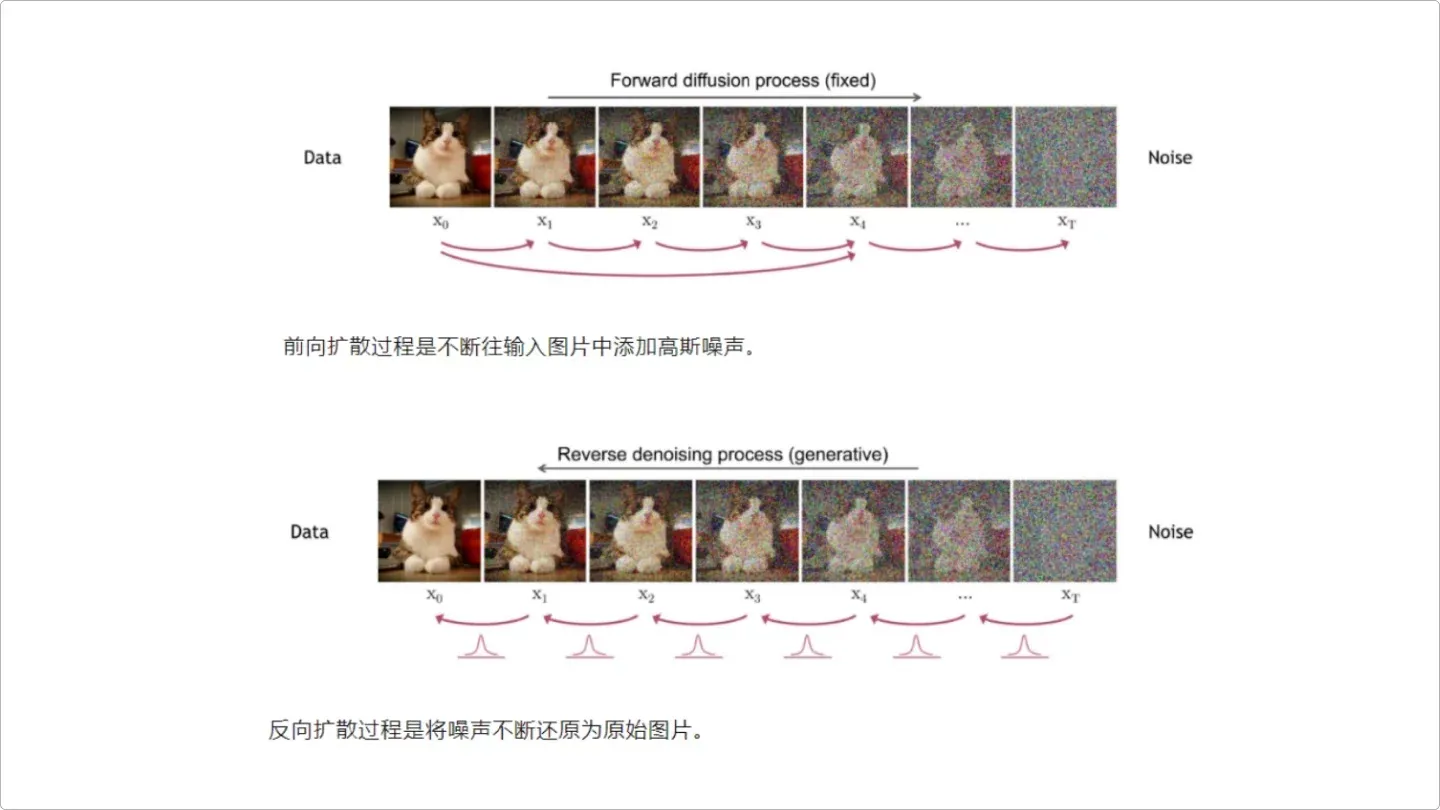
diffusion model 扩散原理图
今天的分享就写到这里,感谢大家。从这一章中,我们主要了解到:
- AIGC 的定义:生成式人工智能
- Stable Diffusion 和 Midjourney 的区别:控图效果不一样
- AI 识图的底层逻辑:提取像素分布规律
- 人工神经网络和深度学习:对函数进行近似估算
- AI 绘图的底层逻辑:扩散原理
在下一章中,我会结合 ComfyUI 的默认画面帮助大家更好地理解 AI 绘图的整体过程,感谢大家的耐心阅读,同时希望大家积极交流。


