
一、python环境准备
可详细参考使用Python操作nNeo4j中python环境的搭建。
主要python库如下:
复制二、数据准备
数据一共有4列,381行,命名为triples.csv:
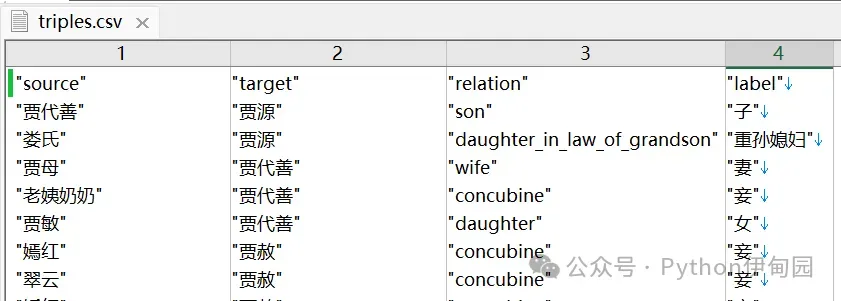
- source:实体起点。比如Alice指向Bob,Alice是起点,箭头开始的位置。
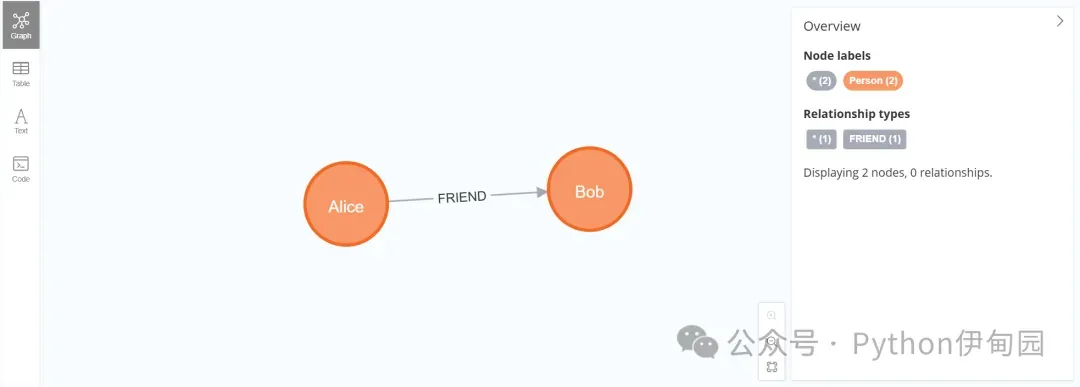
- target:实体起点。比如Alice指向Bob,Bob是终点,箭头终止的实体。
- relation:实体间的关系。实体A与实体B的关系,但是要注意,实体关系是有指向的。比如A是B的父亲,A指向B;B是A的儿子,此时就是B指向A。
- label:标签。会将target列的实体打标签,一个实体可以有多种标签,可以类别一个人是有多重身份的。
数据解释示例:
“贾代善”是“贾源”的son,“贾代善”的标签是“子”;
“贾母”是“贾代善”的wife,“贾母”的标签是“妻”;
三、代码编写
3.1 基础库的导入
复制csv库用来读取triples.csv文件;
py2neo用来连接neo4j图数据库。
3.2 连接neo4j数据库
复制此行代码连接了neo4j图数据库,连接方式为bolt,由Neo4j图形数据库团队创作,主要用于执行数据库查询。
当然,也可以通过http协议进行连接,连接代码如下:
复制3.3 读取数据文件
复制读取triples.csv文件,'r'表示read,读取文件,'encoding'表示数据编码为utf-8。
使用csv.reader形成基于文件的迭代器对象,简单来说就是可以通过reader遍历每一行数据。
for item in reader就是遍历每一行数据。
由于数据有表头,因此首行不计入实体关系的建立。
3.4 定义实体与关系
对于基础语法,可参考:使用Python操作Neo4j
复制item表示某行数据,以首行数据为例:
item[0]表示贾代善,item[1]表示贾源,item[2]表示son,item[3]表示子。

start_node定义为起始实体,实体的标签定义为Person,name定义为source列的数据;
end_node定义为终止实体,实体的标签定义为Person,name定义为target列的数据;
relation定义为start_node与end_node的关系item[3]。
对于以下代码,表示在标签为 Person 的节点中,通过 name 属性值匹配 start_node。
复制3.5 完整代码如下
复制四、图数据库查看
打开neo4j图数据库:http://localhost:7474/browser/
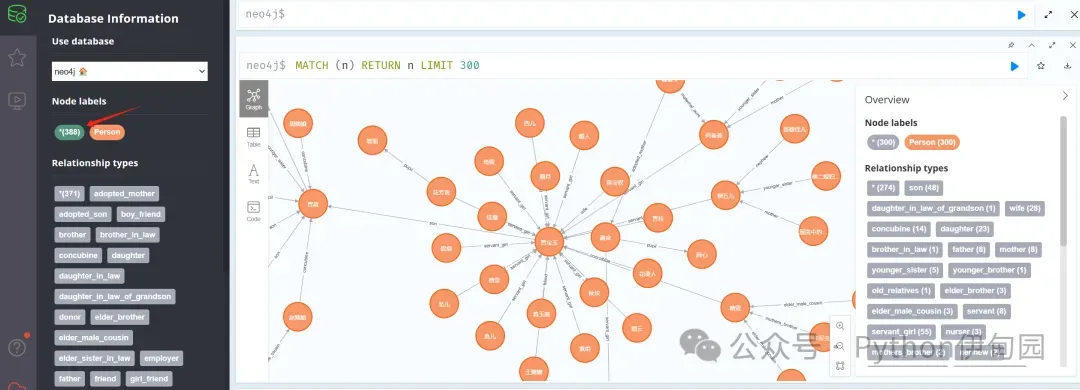
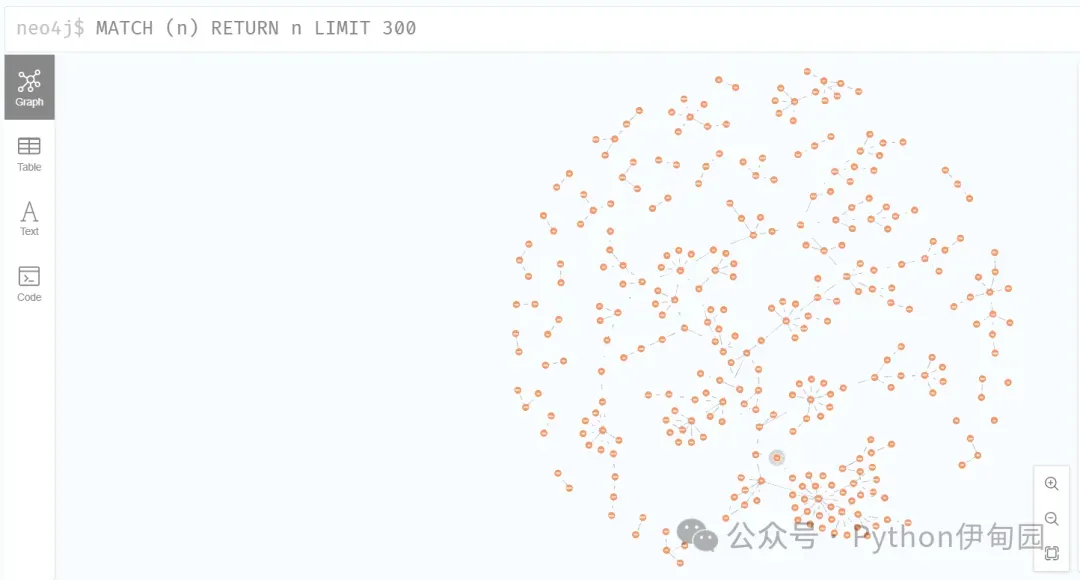
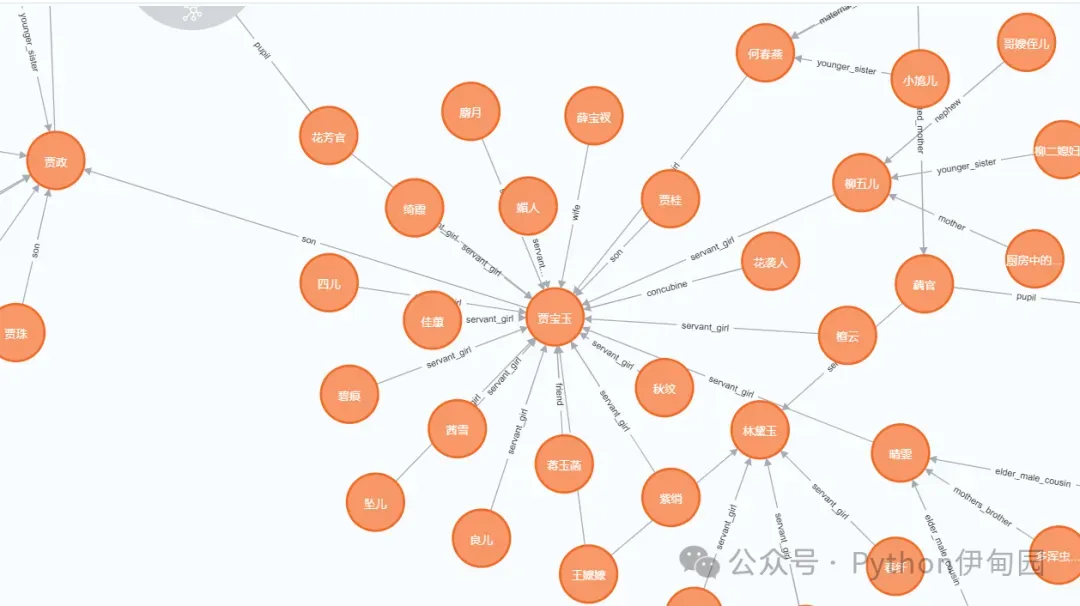
可以看到一共形成了388个实体,多种实体关系;
以贾宝玉实体为例,可以看到其复杂的人物关系。
五、图数据库扩展使用方向
在我们形成知识图谱后,如何来应用呢?
在当前大模型不断发展的情况下,可以考虑将复杂的关系喂给大模型,让大模型自动分析,给出我们想要的结论。


