大模型时代,模型、数据与各种「参数/脚本/许可证」等ML资产爆炸式增长,但真正能被发现、复用、合规使用的比例并不高,这正在成为AI生产力落地的「隐形天花板」。
以知名开源平台HuggingFace为例,平台目前托管超过150万个模型,每月还在新增约10万个模型,总数据存储量高达17PB。
然而超过半数的模型缺乏基本文档说明,不到8%的模型拥有明确的许可证。
在这种「量大而松散」的现实下,可搜索、可复用、可合规的ML资产管理已不再是锦上添花,而是工程与研究协作的基本盘。
面对此挑战,凯斯西储大学(CWRU)、新加坡国立大学(NUS)和加州大学尔湾分校(UCI)的研究团队将在VLDB 2025首次系统性提出 《ML-Asset Management: Curation, Discovery, and Utilization》 教程,从「整理(Curation)—发现(Discovery)—利用(Utilization)」三大环节给出完整的方法论与系统路径, 全面深入探讨ML资产管理的新范式。

论文链接:https://ml-assets-management.github.io/assets/docs/ml_assets.pdf
细节/资料:https://ml-assets-management.github.io/
现场信息以VLDB25日程为准,暂定会议房间Albert(2F),当地时间周四 13:45–15:15
什么是「ML 资产」?
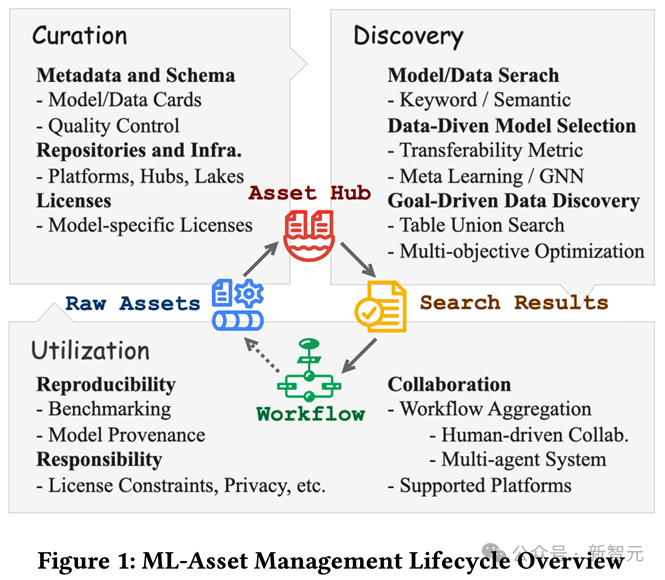
三类对象,一个闭环
教程将ML资产划分为三大类,并以「整理(Curation)→ 发现(Discovery) → 利用(Utilization)」构成闭环:
数据类:原始/标注/验证/测试/生成(基准)数据、开放样本、特征向量等。
模型类:预训练、微调或基础模型,以及训练管线、库、AutoML 组件与 LLM 代理等相关资源。
元数据类:本体/约束、许可证、脚本与 prompts、溯源(provenance)、数据来源、硬件元数据、实验记录等。
以日常生活为例,当你发现社交平台总能精准推荐你感兴趣的视频或音乐时,这背后其实正是「数据资产」(你的观看历史、音乐偏好)、「模型资产」(预测你兴趣的推荐模型),以及「元数据资产」(视频分类标签、音乐风格描述等)在共同驱动。
再比如,一家公司想快速上线智能客服功能,除了语言模型和历史客服数据外,还需要准备用于驱动模型对话的prompt模板、明确模型使用范围的许可证信息,以及自动化部署脚本。
如果团队能够快速找到并直接复用这些资产,就能显著减少从零开始训练模型和搭建系统的成本与周期,更快速地响应用户需求。
这正是ML资产管理带来的实际价值:提高效率、避免重复劳动,让团队更专注于创新和持续优化用户体验。
这个闭环的目标很明确:给资产「上身份证」 → 让资产「被找到」 → 让资产「用得对」。
三部曲深度解读
从「信息」到「能力」
该教程以资产生命周期为主线,系统性地梳理了各个阶段的现有技术、挑战与机会。

整理(Curation):为ML资产安上「身份证」
元数据(Metadata)是资产策展的关键,清晰的元数据能说明资产的来源、适用场景、性能指标、已知限制等。
研究团队引入了数据卡片(Data Cards)与模型卡片(Model Cards)等新兴概念,建立标准化的资产描述体系。
此外,通过知识图谱技术(如CRUX平台),实现了ML资产的知识化、结构化管理,推动资产更易被理解和使用。
另一方面,资产许可证管理同样重要。
团队探讨了针对模型的特定许可证(如Gemma License),如何在法律上明确资产的使用范围与限制,保障资产安全合规使用。
发现(Discovery):快速找到想要的模型或数据
资产发现是资产管理的核心之一。
研究团队从简单的关键词和标签搜索,到最新的语义和向量检索技术,展示如何快速准确地从海量资产中定位所需。
同时,团队提出了数据驱动模型选择(Data-driven Model Selection)与模型驱动数据发现(Model-driven Data Discovery)的创新概念。
前者基于元数据和迁移能力度量,帮助用户快速选定最适合自己数据的模型;后者则反向思考,根据模型需求主动发现或生成合适的数据,优化模型表现。
利用(Utilization):更高效、更透明、更负责任
在资产利用阶段,研究团队强调协作、可复现性与负责任的AI。
协作方面,展示了如何利用模块化的工作流(如Apache Texera平台),实现跨学科、跨团队的高效合作,进一步通过AI智能体技术,自动化生成完整的资产应用工作流;
可复现性方面,标准化的资产管理体系能有效追踪模型来源和数据加工过程,极大提升实验的可复现性和透明度;
在负责任方面,明确的资产许可证与伦理约束能防范数据泄露、隐私侵犯与滥用风险,提升整个ML生态的可信度。
系统级挑战与机遇
随着ML资产规模的迅速扩张,如何实现存储、版本控制、索引搜索等系统级管理成为关键。
研究团队指出,未来ML资产管理需要构建新一代专用系统,这些系统不仅要支持大规模存储和版本控制,还要具备混合查询、高效索引、实时更新与安全隐私保护等能力。
此次tutorial将通过现场展示CRUX、ModelGo和Apache Texera等前沿平台,具体演示ML资产管理技术如何解决实际问题,促进数据科学更快、更好、更安全地发展。

项目链接:https://cruxproject.org/
CRUX(整理 + 发现),由 CWRU 团队开发。
面向以材料科学为主的科学领域,通过知识图谱技术、自动数据集成和探索式查询引擎,CRUX支持自然科学领域的「Why」与「What-if」分析,推动高质量的未发表数据被更多地使用和共享,从而激发新研究问题与创新ML流水线设计。
相关论文:
• Generating Skyline Datasets for Data Science Models(EDBT 2025)
• ModsNet: Performance-Aware Top-k Model Search Using Exemplar Datasets(VLDB 2024)
• CRUX: Crowdsourced Materials Science Resource and Workflow Exploration(CIKM 2023)

项目链接:https://www.modelgo.li/
ModelGo(合规),由NUS团队开发。
本体驱动的模型许可证分析工具,支持权利授予、条款冲突与兼容性检查;团队提出 ModelGo Licenses(类似 CC 的模型许可证集),满足不同的模型发布与治理需求,并作为第一个用于ML模型的许可证提交OSI批准。
相关论文:
• Position: Current Model Licensing Practices are Dragging Us into a Quagmire of Legal Noncompliance(ICML 2025, Oral)
• ModelGo: A Practical Tool for Machine Learning License Analysis(The Web Conf 2024, Oral)

项目链接:https://texera.io
Apache Texera(利用),由UCI团队开发。
Apache Texera (Incubating) 支持基于GUI的工作流组装、实时执行、联合调试与确定性回放,让「资产化流水线」成为日常工程实践。通过实时协作编辑、共享调试上下文和可复用的工作流,Texera让数据科学家、工程师和领域专家能够在同一个平台上高效合作,从而加速数据驱动创新。
同时,Texera还支持对机器学习资产的管理与共享,包括数据预处理模块、特征工程流程和模型组件,使团队能够沉淀和复用 ML 经验,实现从数据到模型的全链路协作。
相关论文:
• Texera: A System for Collaborative and Interactive Data Analytics Using Workflows(VLDB 2024)
• Udon: Efficient Debugging of UDFs in Big Data Systems with Line-by-Line Control(SIGMOD 2024) • IcedTea: Efficient and Responsive Time-Travel Debugging in Dataflow Systems(VLDB 2025)
讲者与机构
Mengying Wang(CWRU)|ML 资产管理与工作流、知识图谱与 Graph RAG。
Moming Duan(NUS)|AI 治理与模型许可。
Yicong Huang(UCI)|Texera 主力贡献者,数据管理与 ML 系统。
Chen Li(UCI)|数据管理与大数据系统,开源与实用系统构建。
Bingsheng He(NUS)|数据库与 ML 系统,高性能计算。
Yinghui Wu(CWRU)|数据管理与图数据分析。
结语
AI的下一个拐点,不仅在于「更强的模型」,更在于把既有的模型、数据与元数据真正「管」起来——可描述、可搜索、可复用、可合规。这正是本教程希望交付的系统能力:用数据管理的严谨与工程系统的方法,把分散的资源沉淀为可复利的AI生产资料。


