编辑 | 云昭
OpenAI 的 ChatGPT 也好、Claude 也好,国内的 DeepSeek也好,到底在推理上是烧钱,亏钱,还是挣钱?
ChatGPT Pro 的毛利高达 5-6 倍;
Claude 做开发者的生意更赚钱:Claude Code Max 的毛利润率竟高达 12-20 倍溢价。怪不得大家都下场卷编程赛道!
而 API 的利润率接近 100%,堪比软件。
就在刚刚,一位资深业界人士、同时也是刚成立一年的初创公司的联合创始人忍不住替我们揭开了真相。
大家口口声声说推理成本让整个行业不可持续,这说法到底有多站得住脚?
昨晚,英国一家初创公司 catchmetrics.io 的联创 Martin Alderson 发表了一篇博客,在 HackerNews 上引起了巨大反响,评论高达 430 多条。
 图片
图片
文章中,Alderson 以 DeepSeek R1 为基准架构,可以说将整个推理环节的成本翻了个底朝天,并得到了一个让人惊掉下巴的结论,他发现:
大模型在推理环节,输入的处理上成本几乎是免费的,而在 decode 输出阶段的成本却搞出来上千倍!
输入处理几乎免费:约 $0.001 / 百万 tokens
输出生成才是真正成本:约 $3 / 百万 tokens
按照这个数字,你就会发现 OpenAI ChatGPT 的经济状况到底有多健康!
话不多说,咱们马上看看这篇神文究竟是如何起底 OpenAI 和 Anthropic 这两家究竟有多赚钱的!
1.AI推理环节很烧钱?我怀疑
我一直听说 AI,尤其是推理环节,是个“烧钱机器”。表面上看这种说法很合理,但我对这种论调始终存疑,所以决定自己挖一挖。
我没见过有人真正把大规模推理的成本结构拆开过,而这恰恰是我很感兴趣的经济学问题。
先说清楚:这只是粗算。我没有大规模运行前沿模型的经验,但我对在云上跑超高吞吐量服务的成本和经济学很了解,也知道超大规模云厂商和裸机之间离谱的利润差。欢迎指正。
2.一些假设
我只考虑纯粹的计算成本。这当然是过度简化,但考虑到现有模型即便不再改进也极具实用性,我想测试一个假设:大家口口声声说推理成本让整个行业不可持续,这说法到底有多站得住脚。
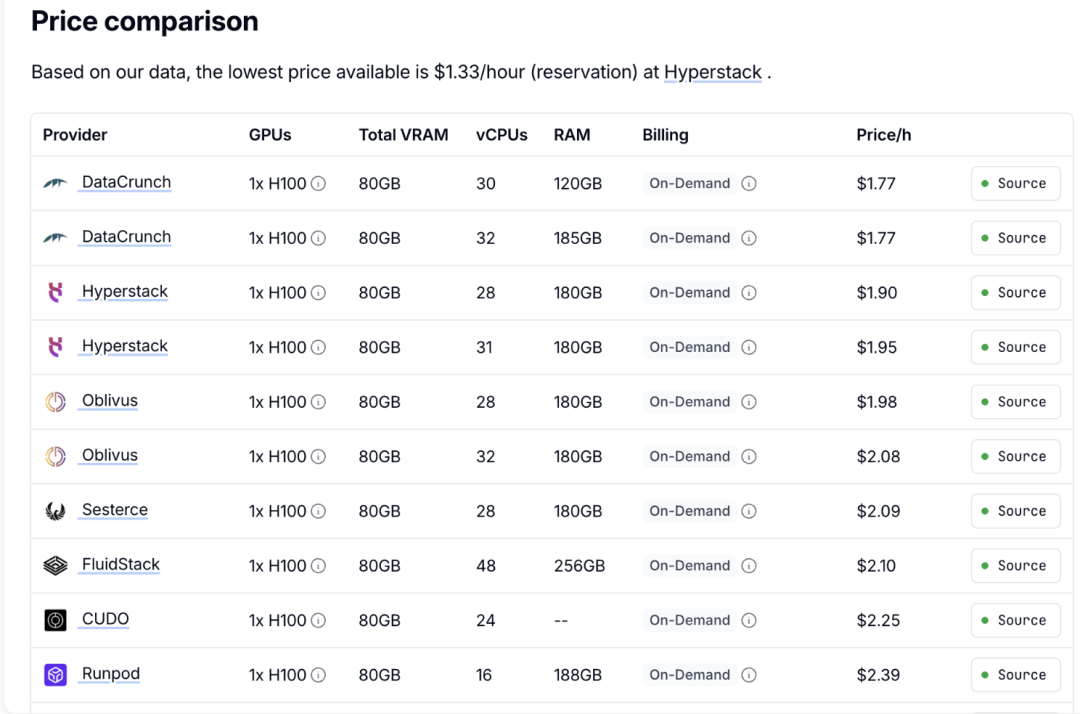
我取一块 H100 的成本为 2 美刀/小时。这其实比零售按需租赁价还贵,而我(希望)大厂能以远低于这个价格拿到。
作为基准架构,我选用 DeepSeek R1:总 6710 亿参数,通过专家混合(MoE)激活 370 亿参数。性能大致接近 Claude Sonnet 4 和 GPT-5,我觉得这个假设算合理。
 图片
图片
3.从第一性原理出发:H100 成本推算
生产环境设定
假设一组 72 张 H100,每张 2 美元/小时,总成本 144 美元/小时。
延迟要求下,我设定 batch size=32 并行请求/模型实例,比基准测试里的巨大 batch 更现实。采用张量并行,每个模型实例分布在 8 张 GPU 上,因此 72 张 GPU 可以同时跑 9 个模型实例。
Prefill 阶段(输入处理)
H100 的显存带宽大约 3.35TB/s。激活的 370 亿参数按 FP16 存储需要 74GB。计算:3,350GB/s ÷ 74GB ≈ 45 次前向传递/秒/实例。
关键在于:每次前向传递会同时处理所有序列的所有 token。batch=32,每序列平均 1000 tokens,即每次 32,000 tokens。所以单实例:45 × 32k = 144 万 tokens/秒。9 个实例合计:1300 万 tokens/秒,≈ 468 亿 tokens/小时。
MoE 可能导致不同 token 走向不同专家,吞吐降低 2–3 倍。但由于路由常常聚集,且现代实现有专家并行和容量因子优化,实际影响更可能是 30–50% 的下降,而不是最糟情况。
Decode 阶段(输出生成)
这里情况完全不同。生成是逐 token 输出的:每次前向传递每序列只生成 1 个 token。所以:45 × 32 = 1440 tokens/秒/实例。9 个实例合计:12,960 tokens/秒,≈ 4670 万 tokens/小时。
4.单位 token 成本差异巨大
当我们细化到单个输入和输出的成本来看,就会发现两者极其不对称,差异极其悬殊:
- 输入:144 ÷ 468 亿 ≈ 0.003 美元 / 百万 tokens
- 输出:144 ÷ 4670 万 ≈ 3.08 美元 / 百万 tokens
差了 一千倍!
ps:关于输出成本,有网友提出了质疑。
 图片
图片
该网友表示,事实上,任何有足够资金,能配置一小批高性能 GPU 的人,都可以在规模上解码超大模型。差不多 4 个月前,这个已经可以做到,成本是每百万输出 tokens 0.2 美元。
再加上更多代码优化 hack,以及使用 B200 芯片,这个成本还在显著下降。
 图片
图片
此外,还有一位网友补充了一些作者存在的错误之处。
预填充(prefill)根本不是带宽受限的。
如果你算一下作者得到的 MFU(机器浮点运算利用率):每秒 144 万输入 tokens * 370 亿个活跃参数 * 2(FMA)/ 每实例 8 张 GPU = 每秒 13 Petaflops。
这大约是硬件绝对峰值 FLOPS 的 7 倍。显然,这是不可能的。
ps:虽然澄清这些错误很有必要,但不过,这些都不足以推翻作者下面要得出的结论。
5.当计算而非带宽成为瓶颈
以上假设内存带宽是瓶颈,但在某些情况计算会成为主导:
- 长上下文:注意力机制复杂度随序列长度二次增长。
- 巨大 batch:更多并行头会让计算饱和。
一旦序列长度 >128k,注意力矩阵极大,成本会骤增 2–10 倍。
这也解释了为什么 Claude Code 限制上下文到 200k,不只是性能问题,也是为了让推理停留在廉价的内存带宽受限区,而不是昂贵的计算受限区。超过 200k 的上下文窗口往往要额外收费,本质是因为成本曲线发生了跃迁。
6.真实的用户经济学
基于零售价的推算结果:
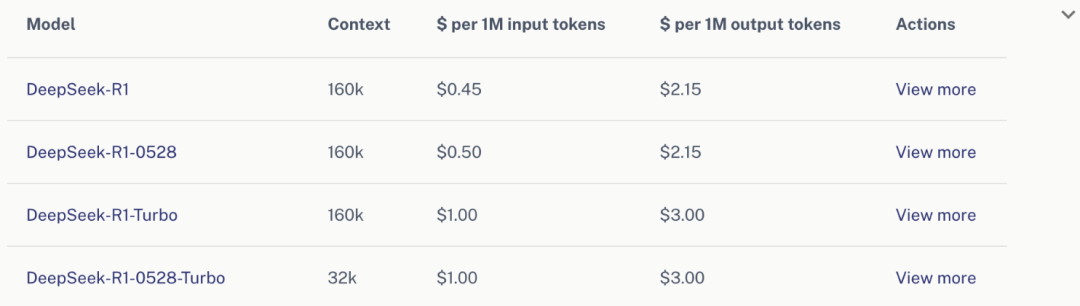
- 输入处理几乎免费:约 $0.001 / 百万 tokens
- 输出生成才是真正成本:约 $3 / 百万 tokens
这与 DeepInfra 对 R1 的定价大体吻合,差别在于输入 tokens 收费加了很高溢价。
 图片
图片
A. 消费者套餐
- ChatGPT Pro:$20/月
- 假设每天 10 万 tokens(70% 输入 / 30% 输出)
- 实际成本 ≈ $3/月
- OpenAI 毛利:约 5–6 倍
典型重度用户:写作、编程、问答。经济性非常健康。
B. 开发者使用
- Claude Code Max 5:$100/月,2 小时/天
输入 ~200 万 tokens,输出 ~3 万 tokens/天
成本 ≈ $4.92/月 → 20 倍溢价
- Claude Code Max 10:$200/月,6 小时/天
- 输入 ~1000 万 tokens,输出 ~10 万 tokens/天
- 成本 ≈ $16.89/月 → 12 倍溢价
开发者场景的经济性更优:输入大量代码、文档、错误日志,输出却相对小。正好契合输入几乎免费的成本结构。
C. API 利润率
- 定价:$3 / $15 每百万 tokens
- 实际成本:约 $0.01 / $3
- 毛利率:80–95%+
API 基本就是印钞机。毛利接近软件,而不是基础设施。
7.写在最后:推理是门很好的生意
在这份分析中,我们做了很多假设,其中一些可能并不准确。但即便误差放大 3 倍,推理的经济性依然极其可观。
大多数人忽略的关键点就在于:输入处理的成本与输出生成相比,便宜得极其夸张。两者之间大约存在千倍差距:
输入 Token 的成本大约是每百万 $0.005,而输出 Token 则超过每百万 $3。
这种成本的不对称性,也解释了为什么某些场景能够获得极高利润,而另一些则举步维艰。
- 重输入/轻输出的应用极度盈利:对话助手、代码助手、文档分析、研究工具。
这些应用通常消耗海量上下文但只生成极少输出,几乎是在一个接近“免费层”的算力成本上运行。
- 重输出/轻输入的应用极其烧钱:视频生成就是典型。
一个视频模型可能只需要一个简单的文本提示作为输入,可能仅 50 个 Token,但生成的每一帧都需要消耗数百万个 Token。这也解释了为什么视频生成依然如此昂贵,以及为什么相关服务要么收取高昂费用,要么严格限制使用。
8.不要被“烧钱”吓到,未必是真的
所以,“AI 成本高得不可持续”的叙事,或许更多是在既得利益玩家的唬人话术,借以阻止竞争和替代性投资,而非真正反映经济现实。
当头部厂商不断强调巨大的成本和技术复杂性时,这会打击竞争者的进入热情以及对替代方案的投资。
但如果我们的测算哪怕接近准确,尤其是在输入密集型工作负载上,盈利性 AI 推理的门槛可能远低于大众的认知。
回顾十几二十年前,大家就在云计算成本上被超大规模厂商“忽悠”过一次,最终大厂们变成了印钞机。如果我们不小心,AI 推理也可能重蹈覆辙。
其实,他们很赚钱。
参考链接:https://martinalderson.com/posts/are-openai-and-anthropic-really-losing-money-on-inference/


