编辑 | 云昭
大模型的发展速度的确超乎想象,可以说现在一周,堪比过去3个月。好在,主体脉络还是沿着圈内预期的逻辑发展的:
观察→理解→推理→物理世界。
随着NanoBanana、Sora2的相继火爆、多模态模型领域烽烟再起,OpenAI与谷歌这一对宿敌纷纷摆好了姿态要在2025年年底各放大招。
假期期间,OpenAI在DevDay上发布的内置应用、AgentKit等收获了一大波好评,紧接着谷歌就发起了Gemini3.0的病毒式预热Marketing。
NanoBanana的刺激在前,小编本来这次还是打算再等等。
然而,这两天大洋彼岸的内测“Gemini3 Pro”的视频、图片效果实在太炸裂了。Ps:网上流传的有两种模型版本:3.0 Pro(代号 2HT)、3.0 Flash(代号 5QA)
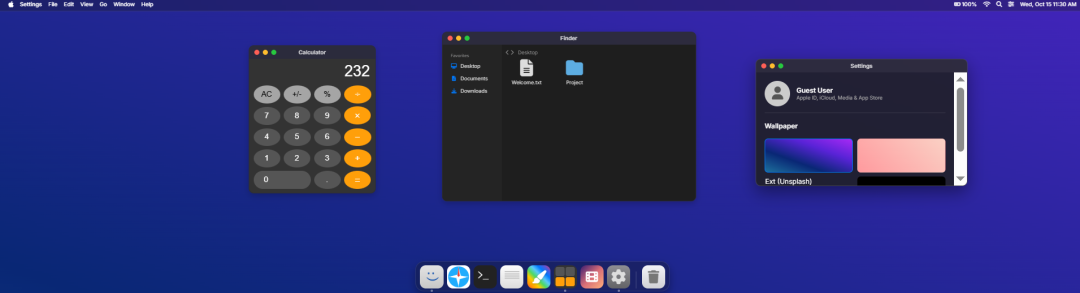
尤其今天看到,一个Prompt就能让Gemini生成一个可以模拟Mac、Windows、Linux操作系统风格的HTML文件,小编亲自体验了下这个网页系统,操作非常丝滑。更恐怖的是,不用抽卡!
 图片
图片
 图片
图片
你突然就会有了多年之前的那种“天亮了”的感觉:1997年,计算机在国际象棋上击败人类,2016年九段大师李世石被DeepMind的AlphaGo战胜,再到2021年11月,ChatGPT的人一样的聊天。
小编实在等不及谷歌正式发布了,觉得必须得写点什么。
声明:以下内容仅仅是看了网上流出的 Gemini3 Pro 的内测素材、跑分传言、网友热议等有感而发,最后还是看谷歌的正式发布版本为准。
Gemini 3 Pro 直接越过了那条线
这两天扒了不少圈内的传闻,这里总结一下这次Gemini 3 Pro的厉害之处:
1.全模态魔法
很早之前,其实用户并不习惯大模型只能 “文字进、文字出”。后来虽然模型支持了一些文件,但也仅限于图片、音视频、word文档等。
但这次,Gemini 3 Pro是真的猛,它能同时理解视频、3D 对象、音频、地理空间数据——甚至多种一起处理。如果真的这样的话,可以说许多现有的产品都要重新设计了,直播、家装、短视频各行业可以说门槛都要抹没了。
想象空间实在太大了,比如:
- 实时总结一段直播;
- 把蓝图转成 VR 场景;
- 或仅凭一段街景视频自动生成播放列表。
2.超级上下文窗口
据传,Gemini 3 Pro 的上下文可达数百万级。整本书、一座法律文件山、甚至上百万行代码——都能在一次提示中处理,仍然逻辑清晰。
量变引起的质变,是我们最猝不及防的,就如同Scaling Law让传统的OCR褪色一样,数百万级的Token,或会让之前繁琐的切片操作被淘汰掉。
3.数万亿参数、激活最相关的动态专家系统
两个点,一个是数万亿参数,第二个点,却只激活最相关的部分。这一点也很极客,Gemini3.0 Pro既保留了算力爆发,又达到了前所未有的响应速度。简单理解,它会自动决定该用多“聪明”的脑子来回答问题。
4.内置“深度思考”机制
无需切换模式。系统能主动规划、校验、并解释自己的多步推理。这更像是雇了一个世界级分析师——只是花几块 API 积分。
5.端侧算力进化
“Gemini Nano 3” 版本将让 Pixel 和 Android 用户在离线状态下体验真正的 AI 能力。实时总结、离线推理、即时问题解决——不再依赖云端。
 图片
图片
实测有多强?
先看下跑分,有疑似有内幕消息的网友这样说:
- 未经证实的基准测试显示,Gemini 3 Pro 的表现优于 GPT-5(“人类的最后考试”中分别为 32.4% 和 26.5%)。
- 推理方面,一位网友评论称,它的推理“感觉像人类”,并且它的自我纠正能力是我们所见过的任何东西的飞跃。
- 最惊艳的还是视觉领域,据称,Gemini 3 Pro 实时工作速度高达 60fps,这意味着它“获取”的是实时视频,而不仅仅是冻结的帧。
再来分享一些自认为非常震撼的实测用例。
先来看一个3D代码生成的用例。

prompt:“用体素风格(voxel art)生成一只骑自行车的鹈鹕。”(create a pelican on a bike with voxil art)
该模型准确理解了多模态概念,生成了精确的 3D 体素代码,空间推理出色,画面布局也很平衡。

这说明它在「创造性理解 + 编程生成」上的能力已经达到顶级模型水准。
另一个震撼的用例则是,一位开发者让 Gemini 3.0 生成关于「卡尔达肖夫三级文明」的可视化,也就是能利用整个银河能量的假想文明。模型成功地融合了 天体物理学、未来设计和视觉想象力。

在零样本提示下,输出的图像展示了戴森球、星际工程等概念,还保持了物理一致性。此外还有系外行星核心可视化。
整段可视化是 Gemini 3.0 Pro 一次性生成的。
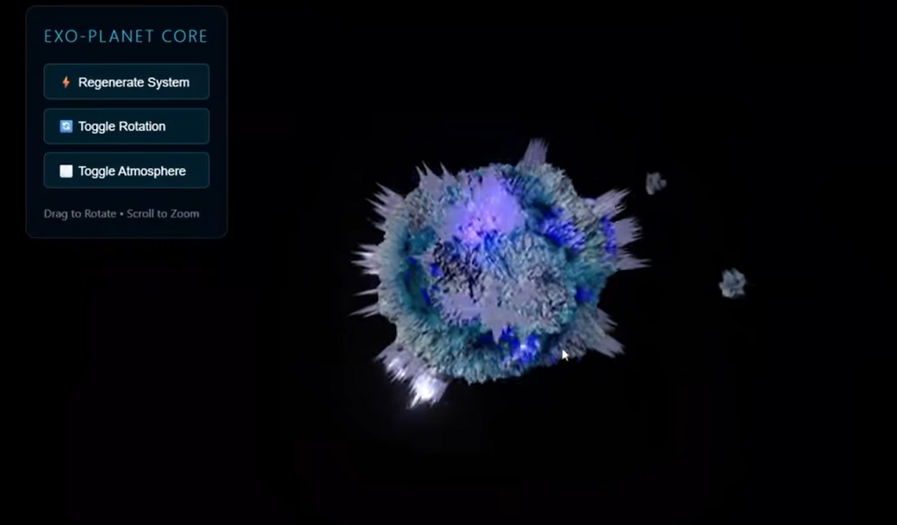
它能把抽象的行星数据转化为逼真的三维视觉,兼具科学准确性和空间推理能力——这是以前任何模型都没做到的。
在附上最新流出的几个体验用例:
比如3D埃菲尔铁塔、3D沉思者。


写在最后
回过头来,总结一下。这次 Gemini 3 Pro 恐怖的预热秀,究竟在向外界透露出怎样的信号?首先,看得出来谷歌这次的邀测对象主要有两类:一类是前端开发者,另一类则是数字创作者。这两类都是非常适合打造震撼宣传效果的群体,言外之意,自然也适合Marketing。其次,谷歌依旧在多模态方面持续发力,尤其在世界模型方面依旧在保持领先。当然,重点还是在于未来正式发布后,大家实际的使用效果。至少现在看来,超长上下文窗口、全模态输入、实时输出总结、无需切换模式深度内置思考,是模型层面主打的四大方向。
那么,对于外界应用而言,意味着什么呢?我想我们可以重新思考这样几件事情。
第一,对于技术人而言,分析、重构百万行代码极有可能不再那么困难了。效率将会大大提升。
其次,对于企业而言:Gemini 的内置 API 推理系统有望形成一种“数字免疫机制”,防止幻觉,保持企业语调一致,并自动化复杂工作流。
第三,对于更多的创作者来说,可以说门槛进一步降低。相信未来会更多人使用这种形式来创作:手绘草图 + 语音备注 = 即时动画短片。
第四,最终的福利还是属于普通大众的,未来的AI应用将会因为模型能力的提升摆脱“鸡肋”的尴尬。看得到的一个例子,离线实时翻译、总结、个人助理——真正随身的 AI,不难想象,就在眼前了。


