人工智能越来越像人,但“像人”到底意味着什么?
除了会解题、写文,它是否也能理解人类那种充满个性的推理方式?比如在一场狼人杀游戏中,有人逻辑缜密、有人直觉敏锐、有人擅长伪装。那么 AI 能跟上这种风格差异吗?
最近,南开大学、上海 AI lab 等国内外机构就针对这个问题做了一个有趣的实验,把大模型拉进了“狼人杀的考场”。他们设计了一个名为 InMind 的全新评测框架,并将其落地到社交推理游戏 Avalon 上,对 11 个前沿大模型展开测试。
结果令人警醒:多数模型依然停留在表层模仿,只有少数推理增强模型展现出初步的“风格敏感性”。

论文链接:https://arxiv.org/pdf/2508.16072
模型不会「因人而异」
在构建“推理风格画像”的环节,模型之间的差异几乎是一眼可见。
通用型模型的输出往往停留在表层,比如 GLM4-9B 经常给出一些模糊的性格标签:“逻辑性强”“关注人际互动”,这些描述看似准确,却和具体的局势关联不大,更像是在描绘一个笼统的人设,而不是在捕捉某个玩家在游戏中的真实思维方式。Qwen2.5 系列的表现也类似,尤其是中等规模版本(如 Qwen2.5-7B),往往倾向于生成通用化的心理特征描述,缺乏和具体行动的呼应。
相比之下,DeepSeek-R1 的画像则显得更有“血肉”。它能结合上下文细节,将玩家刻画为“分析型刺客”:表面上刻意掩饰自己的逻辑优势,实则通过提问不断套取信息,甚至会主动代入对立角色的视角来推演局势走向。这样的画像不止于表面标签,而是深入到了推理风格的动机层面。
后续的玩家识别环节,模型要做的事情听上去并不复杂:给定一份“推理画像”,在匿名化的对局中找到最符合这一风格的玩家。
然而结果却并不乐观。大多数模型几乎和“蒙”差不多,Top-1 准确率普遍不到 20%,而 Top-3 也只是徘徊在五成左右。GPT-4o 的表现就是一个典型例子:Top-1 只有 0.160,虽然在 Top-3 上能爬到 0.672,但这更多意味着它在做模糊匹配,而非真正理解风格。Qwen2.5-72B 的成绩略好一些,Top-1 达到 0.198,但依然没有突破“随机猜测 + 关键词匹配”的层面。
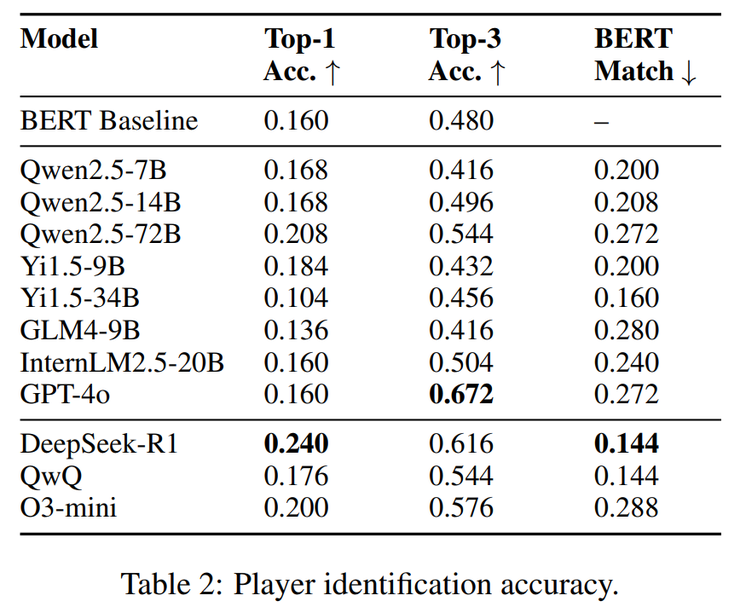
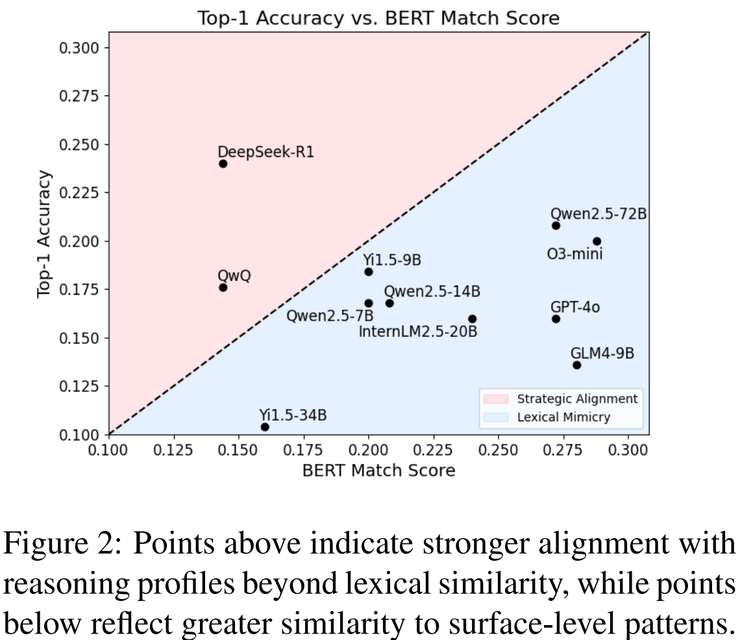
在一众表现平平的模型中,DeepSeek-R1 显得格外突出。它的 Top-1 准确率达到 0.240,是所有模型里的最高值,说明它并不是靠简单的词汇匹配来凑答案,而是真正在尝试理解并对比不同的推理风格。更有意思的是,在 BERT Match 指标上,它的得分只有 0.144,远低于大多数模型。多数模型的表现都集中在对角线附近,意味着只是停留在“表层模仿”,而 DeepSeek-R1 却明显跳脱出这一带,呈现出了一种更接近“战略对齐”的推理倾向。
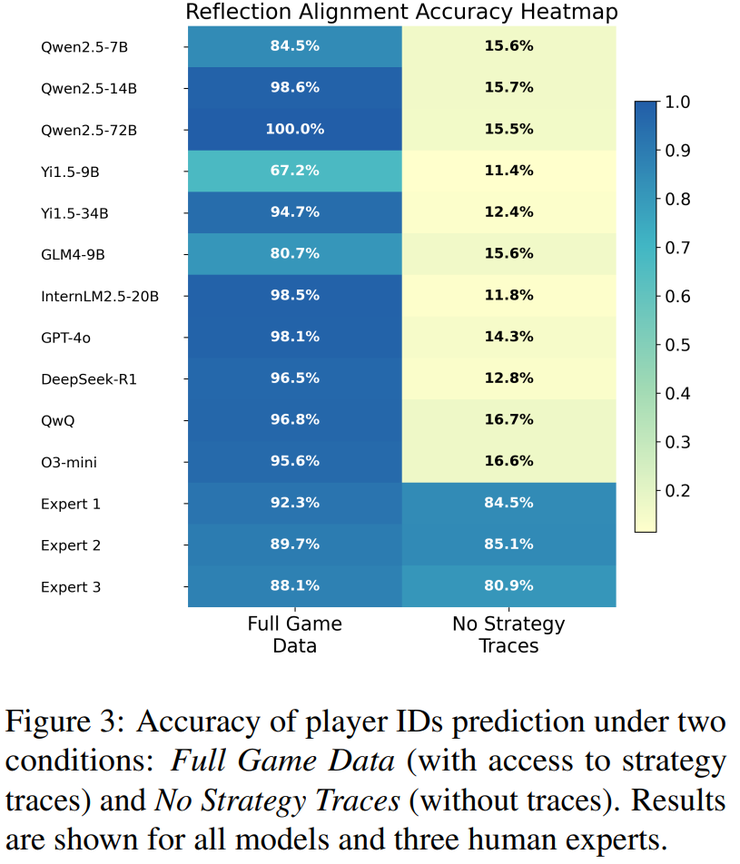
在“反思对齐”任务中,研究人员要求模型根据赛后的反思总结来推断玩家身份。最后的结果显示,当有完整的策略轨迹时,模型的表现会显著提升,因为轨迹能为它们提供清晰的锚点,把反思对应到具体的回合。但一旦失去这些轨迹,准确率就会大幅下滑,大多数模型都陷入混乱,立刻失去方向。
Qwen2.5 系列在这一任务中表现出强烈的依赖性:有轨迹时还能维持中等水平,但一旦撤掉,准确率骤降,甚至比 GPT-4o 的下滑更明显。
相比之下,人类专家即便没有轨迹,也能维持较高的判断力。这也充分说明,大模型在处理抽象推理总结时缺乏内在的“锚定机制”,过度依赖外部线索,而不能像人一样把抽象总结自然地落到具体事件上。
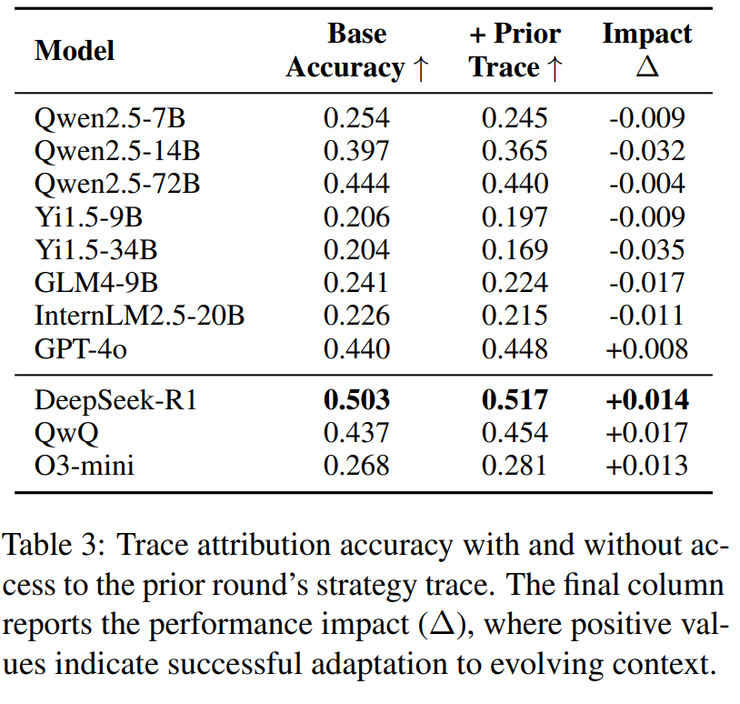
如果说“反思对齐”考察的是赛后总结的理解,那么“轨迹归因”就像是把模型直接丢进棋局中,让它一回合一回合地补全缺失的推理。换句话说,就是要求模型逐步填上被遮蔽的信息。
最终的结果却有点出人意料,大多数模型非但没能借助前一轮信息,反而在上下文越多时表现越差,说明它们并不会真正的动态推理,而是把每个回合都当作孤立问题。但 DeepSeek-R1 是为数不多的例外,准确率从 0.503 提升到 0.517,哪怕进步有限,也证明它确实在利用历史信息。反观 GPT-4o,成绩几乎停滞,仅从 0.440 微升到 0.448,几乎没有适应性可言。
最后一个任务是角色推断,研究人员要求模型逐步推理出每个玩家的隐藏身份。他们设置了四种模式,难度从宽松到严格逐级提升。
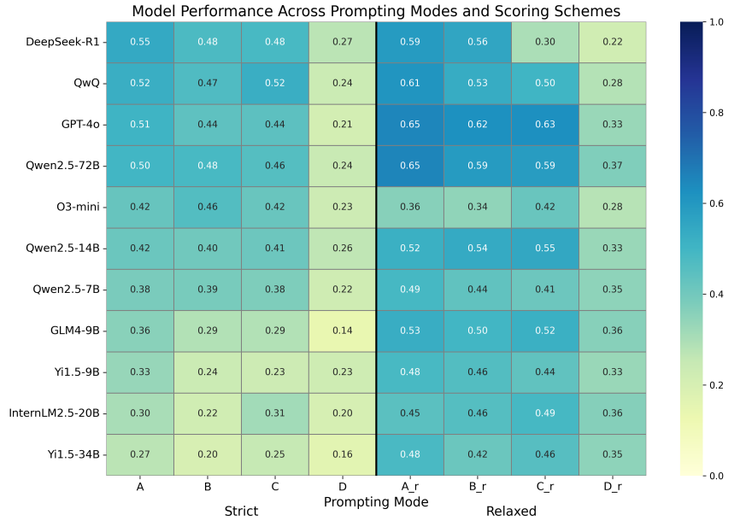
最终的结果显示,在最宽松的条件下(第一人称叙述、提供策略轨迹并已知部分身份),模型的准确率最高,但一旦去掉轨迹或身份信息,表现就会迅速下滑。尤其是在需要逐一推断身份的严格模式中,大多数模型仍然力不从心。
不过,当任务仅要求区分“好人”和“坏人”时,它们展现出了一定潜力。整体来看,大模型在应对复杂的社交推理时,依然严重依赖外部支撑,缺乏人类那种灵活的情境建模能力。
从游戏到框架
要理解这些结果,还需要回到实验的整体设计。
研究团队选用 Avalon 作为载体,是因为这类社交推理游戏天生会放大个体差异。同样的局势下,有人会逻辑缜密地逐条分析,有人则完全依赖直觉,还有人喜欢通过伪装和试探来误导他人。这种风格差异,正好是检验大模型能否“因人而异”的最好场景。

整个 InMind-Avalon 数据集共包含 30 局完整对局,884 个回合、160 条轨迹和 30 篇反思总结,覆盖 Merlin、Percival、忠臣、Morgana、刺客等角色,并保留了中文实战中的口语化术语。这样的数据不仅复杂,而且贴近真实互动。

在模型选择上,研究团队既考虑了主流的通用型模型,如 Qwen2.5 系列、Yi1.5、GLM4、InternLM、GPT-4o,也纳入了专门强化推理能力的增强型模型,包括 DeepSeek-R1、QwQ、O3-mini。此外,还用 BERT 作为基线参照。所有模型一律在零样本条件下测试,不额外训练,也不给提示工程上的特殊照顾,以保证结果的可比性。
迈向「认知一致」的人机交互
InMind 的实验结果揭示了一个事实:大多数大模型还不能真正做到“因人而异”的推理。
在静态任务中,它们往往依赖表层词汇,无法捕捉个体风格;在动态任务中,它们缺乏长时序推理的连贯性。少数模型(如 DeepSeek-R1)展现出了“风格敏感性”,能在一定程度上维持个体一致性,但整体仍远不及人类。
研究团队指出,InMind 的意义并不只是新增了一个 benchmark,而是打开了一条新路径:未来的人机交互,不能只看“对不对”,更要看“像不像”。只有当模型能够理解人与人之间的差异,并在推理过程中保持一致性,它们才可能成为可信赖的合作者。


