基于视觉编码器的MLLM的基本构成:MLLM通常由预训练的模态编码器、预训练的LLM和一个连接它们的模态接口三个模块组成。模态编码器(如:CLIP-ViT视觉编码器、Whisper音频编码器等)将原始信息(如图像或音频)压缩成更紧凑的表示。预训练的LLM则负责理解和推理处理过的信号。模态接口用于对齐不同的模态,实现异构模态表征空间的语义对齐。下面这张图概括的比较好。
 基于视觉编码器的MLLM的基本构成
基于视觉编码器的MLLM的基本构成
上述工作都是基于视觉编码器的多模态大模型,下面来看一个Encoder-free VLMs(无视觉编码器的多模态大模型)的思路,供参考。
模型架构
 图片
图片
视觉和文本编码

多模态编码:为了在视觉和文本之间建立有效的交互,提出了一个分而治之的设计,通过引入模态感知组件来显式解耦关键模块。包括独立的注意力矩阵(查询、键和值)、归一化层和前馈模块,每个都有不同的参数,以适应不同模态的需求。
分而治设计
通过分而治之的架构设计,EVEv2.0能够有效地减少模态间的干扰,提高模型的训练效率和性能。
使用多头自注意力(Multi-Head Self-Attention, ATTN)来跨所有模态进行建模,以在统一特征空间中模拟跨模态关系。公式如下:


通过完全解耦架构,最小化表示空间中的干扰。每个Transformer块的总体操作定义如下:

这种设计允许在保持预训练知识的同时,独立地进行单模态编码和跨模态对应,从而实现灵活的建模模式,以理解和推理多模态信息。
视觉特征与语言输入的融合方式
从代码上看,融合时,会遍历输入序列中的每个样本,根据 IMAGE_TOKEN_INDEX 确定图像特征的插入位置。将语言输入的嵌入和图像特征按顺序拼接在一起,形成新的输入嵌入 new_input_embeds,同时更新标签 new_labels 和视觉标记掩码 visual_token_mask。
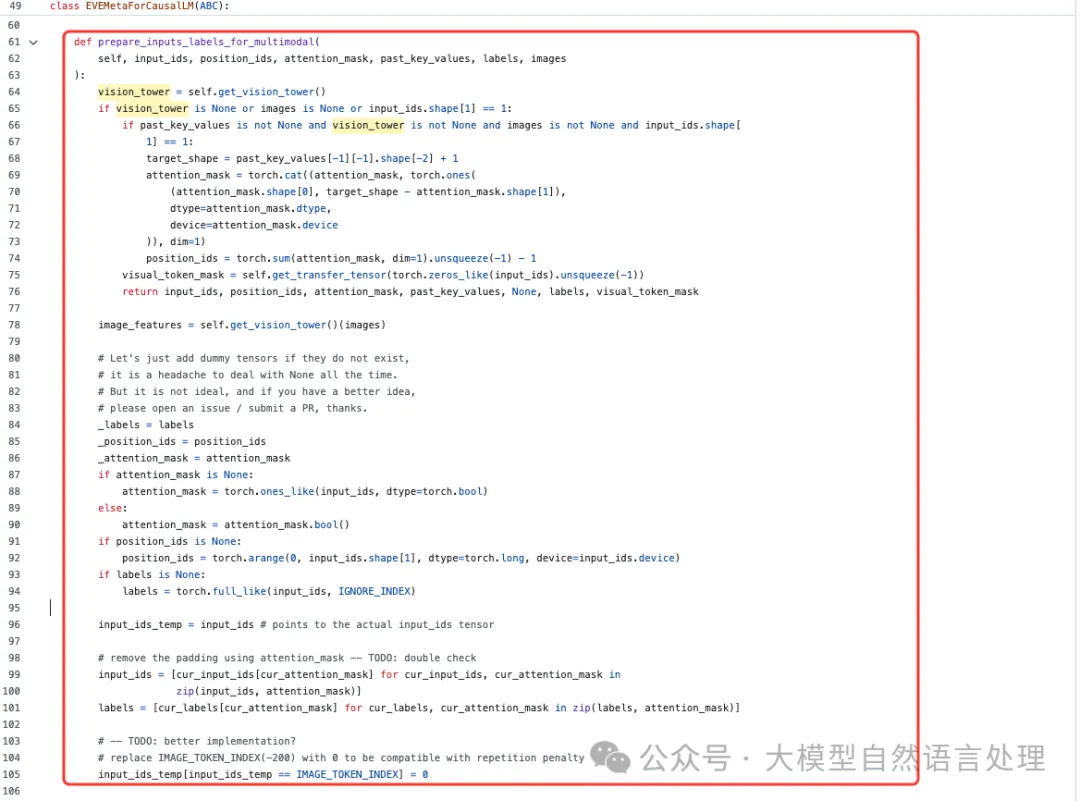 https://github.com/baaivision/EVE/blob/main/EVEv2/eve/model/eve_arch.py
https://github.com/baaivision/EVE/blob/main/EVEv2/eve/model/eve_arch.py
https://github.com/baaivision/EVE/blob/main/EVEv2/eve/model/eve_arch.py
训练方式
 训练流程概述。PEL/WEL 表示图像块/单词嵌入层。我们首先训练图像块嵌入层,以在不同模态间建立初始对齐。之后,我们仅更新大型语言模型(LLM)内的视觉层,逐步增强视觉感知能力。值得注意的是,我们将图像分辨率从 800×800 逐步提高到 1600×1600,并保持原始图像的宽高比。最后,我们通过问答(QA)和指令数据对整个模型进行训练,以加强跨模态对应和复杂理解能力。
训练流程概述。PEL/WEL 表示图像块/单词嵌入层。我们首先训练图像块嵌入层,以在不同模态间建立初始对齐。之后,我们仅更新大型语言模型(LLM)内的视觉层,逐步增强视觉感知能力。值得注意的是,我们将图像分辨率从 800×800 逐步提高到 1600×1600,并保持原始图像的宽高比。最后,我们通过问答(QA)和指令数据对整个模型进行训练,以加强跨模态对应和复杂理解能力。
训练流程概述。PEL/WEL 表示图像块/单词嵌入层。我们首先训练图像块嵌入层,以在不同模态间建立初始对齐。之后,我们仅更新大型语言模型(LLM)内的视觉层,逐步增强视觉感知能力。值得注意的是,我们将图像分辨率从 800×800 逐步提高到 1600×1600,并保持原始图像的宽高比。最后,我们通过问答(QA)和指令数据对整个模型进行训练,以加强跨模态对应和复杂理解能力。
训练过程分为四个连续阶段。训练数据包括公开可用的图像数据集,以及表 1 中的各种问答(QA)数据集和多模态对话数据。
 图片
图片
 第2.2阶段和第3阶段的训练数据集详细信息,用于微调E
VEv2.0,FL表示过滤后的训练数据集
第2.2阶段和第3阶段的训练数据集详细信息,用于微调E
VEv2.0,FL表示过滤后的训练数据集
阶段1:DenseFusion++
DenseFusion++:通过大规模的合成数据来增强模型的视觉感知能力。使用LLaVA-1.6(7B)为基础,结合多个视觉专家(如标签、检测、OCR等)来学习GPT-4V的融合策略。通过这种方式,可以在不依赖高质量标注的情况下,扩展合成数据的规模,从而提高训练效率。
阶段2:LLM引导的对齐
冻结大型语言模型(LLM)的权重,仅训练patch嵌入层。使用公开的网页数据进行训练,以防止模型崩溃并加速后续阶段的收敛。通过这种方式,确保模型在初始阶段能够快速对齐视觉和语言信息。
阶段3:视觉感知学习和视觉-文本完全对齐
- 视觉感知学习(Vision Perception Learning):加载LLM的权重并初始化LLM内部的视觉层。仅训练patch嵌入层和视觉层,而冻结Qwen2.5模型,以便在大规模合成数据上进行视觉表示的学习。通过逐步增加数据量和图像分辨率,促进视觉感知能力的提升。
- 视觉-文本完全对齐(Vision-Text Fully-aligning):更新整个模型架构以进一步改善图像-文本的关联。使用多样化的指令数据集进行训练,以增强模型的视觉感知能力和视觉-语言对齐。通过这种方式,确保模型在处理复杂的多模态任务时能够表现出色。
阶段4:监督微调
进一步优化模型以理解复杂的指令和对话模式。使用高质量的指令数据集进行训练,以提高模型在实际应用中的表现。通过这种方式,确保模型能够处理各种真实世界的应用场景。
实验效果


参考文献:EVEv2: Improved Baselines for Encoder-Free Vision-Language Models,https://arxiv.org/pdf/2502.06788


