大模型

高性能计算群星闪耀时
“没有高性能计算,就没有大模型。 ”自 2023 年以来,伴随大模型崛起的除了芯片,还有芯片与模型之间的中间层——系统软件优化,其中高性能计算(HPC)背景出身的研究员参与占比大幅攀升。 但对大众来说,HPC 之于 LLM 的战略意义仍是晦涩艰深的,直到 DeepSeek 杀出重围,软硬协同的力量被具象化,他们才被更多关注。
8/21/2025 12:10:00 PM
陈彩娴

AI工具如何成为时间和成本的陷阱
周二下午2点,你本该在专心做重要项目,可实际上,过去三个小时你一直在测试在领英上发现的最新的AI工具。 “只是试试而已。 ”你这样想。
8/21/2025 7:00:00 AM
Mark

网易有道发布子曰教育大模型多款AI新品,定义教育AI应用能力L1-L5分级
8 月 20 日,网易有道在北京举行 “POWERED BY 子曰” 有道 AI 新品发布会。 重磅发布了基于 “子曰” 教育大模型的多款 AI 新品 —— 全新硬件有道 AI 答疑笔 Space X、一站式处理平台有道音视频翻译,以及全新升级的网易有道词典等。 会上,网易有道 CEO 周枫提出教育 AI 应用能力 L1-L5 分级标准,并指出,目前教育 AI 正加速升级,将带来千人千面的个性化课堂,让家庭学习更高效,让教师拥有随时在线的 “超级智脑助手”。
8/20/2025 8:47:00 PM
机器之心
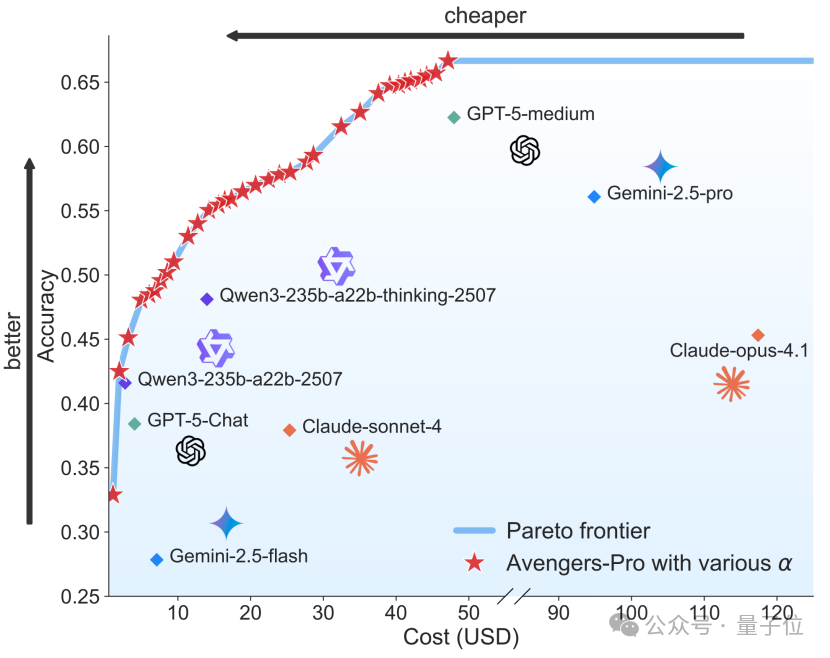
国产AI路由系统开源逆袭!仅用19%成本达到Gemini-2.5-Pro同等性能
顶级大模型性能确实很强,但对于预算不高的用户来说就是:. 你很好但我不配。 虽然大模型的优越表现令人瞩目,但动辄高昂的使用成本也让不少用户望而却步。
8/20/2025 3:43:04 PM
闻乐

最懂Claude内部运作团队采访流出:大模型输出的思考全是拍马屁!曝自家减少幻觉路径;绝非只预测下一个词。网友:这都敢免费公开
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)上周末,Anthropic 团队放出了一个非常优质的播客。 话题的敏感尺度很大,头排的听众们都替Claude担心了起来,惊呼:这种“核心机密”竟然敢免费公开吗? 甚至有网友表示,第一次从头到尾把60分钟的播客听完了。
8/20/2025 8:34:48 AM
云昭

AI教父辛顿:人类需要AI成为“母亲”,李飞飞:反对!
“AI 会统治人类吗? ”这个问题,早已不是科幻小说的专属。 不如我们回顾下《爱,死亡与机器人》中那个荒诞又深刻的故事——《当酸奶统治世界》。
8/20/2025 7:53:01 AM
DataFun

告别人工写脚本!多模态大模型驱动携程UI自动化测试迈入“描述即生成”阶段
作者简介Jessi Peng,携程资深后端开发工程师,关注AI技术在测试领域的应用。 一、引言 在传统的UI自动化测试流程中,测试人员需要构建完整的开发环境,包括Python运行环境、PyCharm集成开发环境、自动化测试框架等工具链的配置与部署。 在用例编写过程中,测试人员必须通过人工方式精确定位目标UI元素,并基于自动化框架封装的底层方法,手工编写测试代码。
8/19/2025 10:47:17 AM
Jessi Peng

一句话,性能暴涨49%!马里兰MIT等力作:Prompt才是大模型终极武器
AI性能的提升,一半靠模型,一半靠提示词。 最近,来自马里兰大学、MIT、斯坦福等机构联手验证,模型升级带来的性能提升仅占50%,而另外一半的提升,在于用户提示词的优化。 他们将其称之为「提示词适应」(prompt adaptation)。
8/18/2025 5:20:17 PM

硬核拆解!从GPT-2到gpt-oss,揭秘大模型进化关键密码
8月5日,在GPT-5发布前两天,OpenAI推出了它的两款开源权重大语言模型:gpt-oss-120b、gpt-oss-20b。 这是自2019年GPT-2,近六年来OpenAI首次发布开放权重的模型。 得益于巧妙的优化技术,这些模型甚至可以在本地设备上运行。
8/18/2025 9:15:00 AM

大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。 这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。 一个最基础、却也最关键的问题是:在评判一个模型是否“入戏”之前,AI裁判能准确识别出对话中到底是谁在说话吗?
8/18/2025 9:00:00 AM

谷歌最新「0.27B」Gemma 3开源!身板小却猛如虎,开发者直呼救命稻草
大块头不等于大智慧。 这在生成式AI领域,已逐渐成为共识。 Gemma 3系列的成功就是一个很好的例证。
8/18/2025 8:57:00 AM

AI大模型的版权风暴:行业巨头面临7500亿美元赔偿风险
近年来,随着人工智能技术的飞速发展,大型 AI 模型的训练数据来源问题日益成为业界关注的焦点。 许多知名企业在构建其 AI 模型时,似乎都选择了使用大量未授权的版权内容作为数据。 这一 “秘密配方” 引发了激烈的法律争论,并将硅谷的科技巨头们推上了风口浪尖。
8/15/2025 9:31:41 PM
AI在线

Agent 产品如何定价?我们花的钱,究竟值不值?
一方面,我们对Agent的期望是成为一个可靠、高效、且不知疲倦的伙伴;另一方面,现实体验却常常被一些“意外”打断:资源瓶颈的窘境:在执行关键任务的冲刺阶段,系统突然弹出“积分/点数已耗尽”的提示,如同汽车在距离目的地一公里处耗尽燃油,进程戛然而止。 性能波动的无奈:用户时常面临算力“堵车”的困境,Agent的响应速度时快时慢,尤其在服务高峰期,其表现更像一个“兼职员工”,而非全天候的专业助理。 DeepSeek等前沿应用在发布初期因用户激增而导致的服务器高负载现象,便是这一挑战的缩影。
8/14/2025 11:13:59 AM
DataFun

基于 DiT 大模型与字体级分割的视频字幕无痕擦除方案,助力短剧出海
当短剧出海、跨境电商等新兴领域打造全球化内容时,面临着一个棘手的基础问题——原始视频的中文字幕。 原始字幕对于海外观众来说,不仅是无效信息,还严重干扰观看体验。 传统方案——直接添加对应外语字幕会导致画面杂乱,而使用马赛克或基于 GAN 的字幕擦除补全方案会导致画面模糊、帧间闪烁,都无法彻底解决这一挑战,使得优质内容的出海之路障碍重重。
8/12/2025 9:37:43 AM
孙康、丁杨

Deep Agent 是如何让大模型更“聪明” ?
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活的计算架构的开源库 - “Deep Agent”。 众所周知,AI Agent 无疑是当下最激动人心的技术叙事之一。 它让我们看到了一个未来:AI不再仅仅是被动应答的工具,而是能够自主感知、推理并行动的“数字员工”。
8/12/2025 9:23:34 AM
Luga Lee

吴恩达解读 AI 天价薪酬:资本堆起的1亿美元不是情绪
人工智能界掀起了新的薪资地震。 吴恩达对此做了评价。 图片吴恩达在推特中表示,Meta为AI大模型开发者开出超过1亿美元的薪酬大礼包,震动了整个科技行业。
8/8/2025 2:27:22 PM

大模型训练“练兵千日”,别输在AI推理“用兵一时”
2025年被认为是AI智能体的元年,是AI走向大规模应用的开始。 随着AI应用爆发,算力的需求逻辑也正在被重塑:AI推理——而不是训练,将成为未来算力需求的核心增长点。 这种趋势在刚刚结束的2025年世界人工智能大会(WAIC)多有体现。
8/8/2025 6:00:00 AM
朱飞

从GPT-OSS谈谈大模型算法和Infra演进
TL;DRgpt-oss开源了,整个模型架构的设计真的是非常的simple & elegant。 本文结合一些前段时间一些Infra相关的争议和自己开发Agent相关的分析, 来对未来模型架构演进做一些分析。 OverviewOpenAI这次开源的是gpt-oss-20b 和 gpt-oss-120b两个模型。
8/8/2025 4:11:00 AM
zartbot
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
DeepSeek
谷歌
AI绘画
机器人
数据
大模型
Midjourney
开源
Meta
智能
微软
用户
AI新词
GPT
学习
技术
智能体
马斯克
Gemini
图像
Anthropic
英伟达
AI创作
训练
论文
LLM
代码
算法
芯片
Stable Diffusion
苹果
腾讯
AI for Science
Claude
Agent
蛋白质
开发者
生成式
神经网络
xAI
机器学习
3D
研究
人形机器人
生成
AI视频
百度
工具
具身智能
Sora
RAG
大语言模型
GPU
华为
计算
字节跳动
AI设计
搜索
大型语言模型
AGI
场景
深度学习
视频生成
架构
DeepMind
预测
视觉
伟达
Transformer
编程
AI模型
神器推荐
亚马逊
MCP